数据增强(检测,分类,识别):1708.Random Erasing Data Augmentation 论文笔记
Random Erasing Data Augmentation 论文下载地址:https://arxiv.org/abs/1708.04896
详细信息:

论文资源代码:
https://github.com/zhunzhong07/Random-Erasing
论文解读:
首先,为了增强模型的泛化的性能,一般的手段有数据增强和正则化方法(如dropout,BN),而用于数据增强的一般方法有:随机裁剪、随机水平翻转、平移、旋转、增加噪音和生成网络方法等(前两个方法用的最多,也最有效),作者从CNNs输入的数据预处理出发,极端的情况下,如果训练模型的数据集很少有遮挡的样本(尽管放大再随机裁剪一定程度对应对遮挡的情形上有帮助),那么最终训练得到的模型也不能很好处理遮挡情景,为了使训练的模型更好的应对作为影响模型泛化能力的重要而关键的因素–遮挡,作者提出了很简单且实用的无参数数据增强方法—Random Erasing(也可以被视为add noise的一种)。该方法被证明在多个CNN架构和不同领域中可以提升模型的性能和应对遮挡的鲁棒性,并且与随机裁剪、随机水平翻转(还有正则化方法)具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。
该方法可以很容易嵌入到现今大部分CNN模型中用于训练具有更好泛化性能的模型。
作者证明Random Erasing可以取得最好性能的一般过程如下:
随机0一定概率确定是否对一张被选择的图像进行处理,确定处理后,以一定的面积比范围和高宽比限制,并在不超过图像W和H的图像内随机选择一块矩形区域,给像素赋随机值或者[125.0,122.0,114.0](平均值即ImageNet mean pixel value)。算法图示,如下:

以图像分类和行人重识别为例,随机擦除数据增强,示例:

以目标检测为例,随机擦除数据增强,示例:
其中,分三种情况,IRE:Image-aware Random Erasing不区分目标框和背景区域,在整个图像来做擦除处理;ORE:区分目标框和背景区域,来做擦除处理,只在目标框内做擦除处理; I+ORE:区分目标框和背景区域,分别在目标框和整个图像来做擦除处理

随机擦除和随机裁剪的区别:

实验:
作者实验用的数据集有:
图像分类实验:CIFAR-10 and CIFAR-100 and Fashion-MNIST
目标检测:PASCAL VOC 2007/ PASCAL VOC 2012
行人重识别:Market-1501、DukeMTMC-reID、CUHK03(该数据集较小,用随机擦除可缓解复杂模型的过拟合)
随机擦除操作涉及的参数设置:面积比即Reasing area ratio rang阈值限(区间下限和上限决定了遮挡的级别)(level),高宽比Reasing aspect ratio rang阈值限,随机擦除概率(Erasing probability)
1.图像分类实验
数据集上的实验

随机擦除操作涉及的参数(超参数影响)
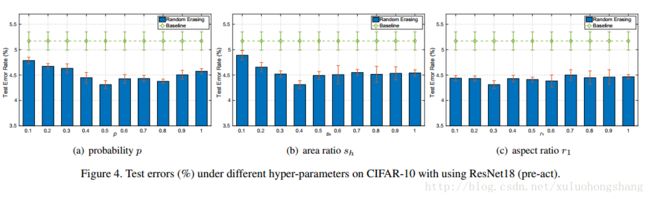
得出下面跟随的实验,无特别说明,采用的参数设置为:
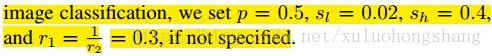
随机擦除的四种不同的赋值类型对比:

与dropout和随机添加噪声的实验比较:可以看出只有随机擦除有助于提升性能

和其他数据增强方法的比较:说明随机擦除是与随机裁剪和随机水平翻转具有同样的竞争力,并具有一定的互补性

对遮挡的鲁棒性实验:说明无随机擦除和有随机擦除随着遮挡区域的级别(占整个图像的面积)增大,后者drops的更慢,更低。即随机擦除可以提升CNNs对遮挡的鲁棒性。

2.目标检测实验
IRE:Image-aware Random Erasing不区分目标框和背景区域,在整个图像来做擦除处理;ORE:区分目标框和背景区域,来做擦除处理,只在目标框内做擦除处理; I+ORE:区分目标框和背景区域,分别在目标框和整个图像来做擦除处理
分析:表格上面部分是training with VOC07 trainval,下面部分的是The detector is trained with two training set, VOC07 trainval and union of VOC07 and VOC12 trainval.

3.行人重识别实验
实验设置:


不同数据集上对各方法的性能提升


涉及的一些有价值的论文:
regularization methods
A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012. 1, 2
L. Wan, M. Zeiler, S. Zhang, Y. L. Cun, and R. Fergus. Regularization of neural networks using dropconnect. In ICML, 2013
J. Ba and B. Frey. Adaptive dropout for training deep neural networks. In NIPS, 2013
M. D. Zeiler and R. Fergus. Stochastic pooling for regularization of deep convolutional neural networks. In ICLR, 2013
L. Xie, J. Wang, Z. Wei, M. Wang, and Q. Tian. Disturblabel: Regularizing cnn on the loss layer. In CVPR, 2016
G. Kang, X. Dong, L. Zheng, and Y. Yang. Patchshuffle regularization. arXiv preprint arXiv:1707.07103, 2017
总结:对于行人重识别来说,对不同的reid方法,同时应用该文的随机擦除数据增强和最新的re-ranking方法,是个比较好的选择,对提升reid识别率会很有帮助