梯度下降(Gradient Descent)
总目录
一、 凸优化基础(Convex Optimization basics)
- 凸优化基础(Convex Optimization basics)
二、 一阶梯度方法(First-order methods)
- 梯度下降(Gradient Descent)
- 次梯度(Subgradients)
- 近端梯度法(Proximal Gradient Descent)
- 随机梯度下降(Stochastic gradient descent)
待更新。。。
梯度下降
考虑一个无约束的,平滑的凸优化问题
min x f ( x ) \min_x f(x) xminf(x)
其中, f f f是凸函数,且在定义域 d o m ( f ) = R n dom(f)=R^n dom(f)=Rn上是可微的。
算法
选择一个初始点 x ( 0 ) ∈ R n x^{(0)}\in R^n x(0)∈Rn,重复操作:
x ( k ) = x ( k − 1 ) − t k ⋅ ∇ f ( x ( k − 1 ) ) , k = 1 , 2 , 3. , . . x^{(k)} = x^{(k-1)} - t_k \cdot \nabla f(x^{(k-1)}),\ k=1,2,3.,.. x(k)=x(k−1)−tk⋅∇f(x(k−1)), k=1,2,3.,..
直到达到某阈值后停止。梯度下降法就是沿着梯度减小的方向,每次走一定的步长,直到到达最优点为止。

梯度下降的解释
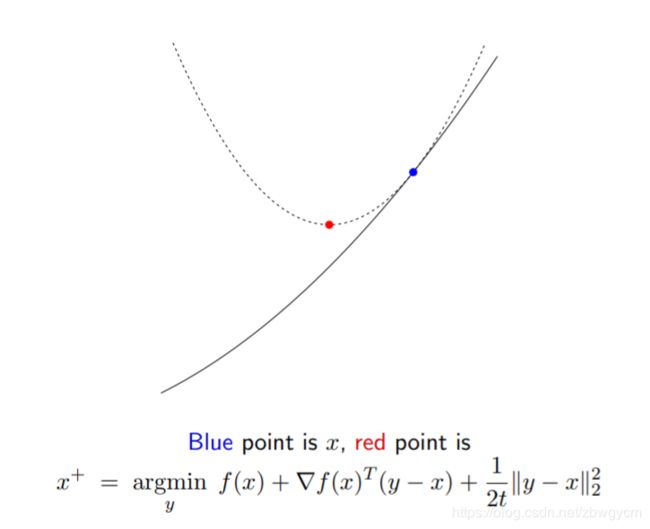
在每一次迭代中,对当前点做二次泰勒展开:
f ( y ) ≈ f ( x ) + ∇ f ( x ) T ( y − x ) + 1 2 t ∥ y − x ∥ 2 2 f(y)\approx f(x)+\nabla f(x)^T(y-x)+\frac{1}{2t}\|y-x\|^2_2 f(y)≈f(x)+∇f(x)T(y−x)+2t1∥y−x∥22
这里用 1 t I \frac{1}{t}I t1I代替了二次项系数海森矩阵 ∇ 2 f ( x ) \nabla^2 f(x) ∇2f(x)。
选择下一个点 y = x + y=x^+ y=x+去最小化该二次近似可以得到:
x + = x − t ∇ f ( x ) x^+=x-t\nabla f(x) x+=x−t∇f(x)
所以,梯度下降相当于在函数的每个点处都做二次近似,然后求解最小点的位置。
步长的选择
既然梯度下降每次迭代都要走一定的步长,那这个步长要怎么选择呢?
一种简单的方式是把步长固定,每次都移动常数距离, t k = t , f o r a l l k = 1 , 2 , 3 , . . . t_k=t,\ for\ all\ k=1,2,3,... tk=t, for all k=1,2,3,...。但是这样存在问题,如果 t t t太大,梯度下降可能会发散而不收敛;如果 t t t太小,梯度下降就会收敛很慢。只有 t t t选得“刚好”时,才能兼顾收敛性和收敛速度。另一种方法可以自适应地调整步长——回溯线性搜索
回溯线性搜索
- 首先固定参数 0 < β < 1 0<\beta<1 0<β<1和 0 < α ≤ 1 / 2 0<\alpha\leq 1/2 0<α≤1/2
- 在每次迭代中,首先设置 t = t i n i t t=t_{init} t=tinit,然后只要:
f ( x − t ∇ f ( x ) ) > f ( x ) − α t ∥ ∇ f ( x ) ∥ 2 2 f(x-t\nabla f(x))>f(x)-\alpha t \|\nabla f(x)\|^2_2 f(x−t∇f(x))>f(x)−αt∥∇f(x)∥22就收缩 t = β t t=\beta t t=βt - 重复步骤2,直到满足条件为止。然后进行梯度下降更新:
x + = x − t ∇ f ( x ) x^+=x-t\nabla f(x) x+=x−t∇f(x)
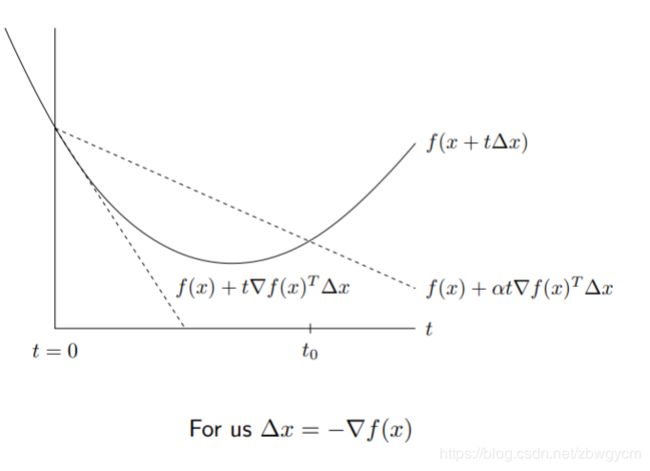
在实践中可以进一步简化 α = 1 / 2 \alpha=1/2 α=1/2。
收敛性分析
已知 f f f是凸函数,且在定义域 d o m ( f ) = R n dom(f)=R^n dom(f)=Rn上是可微的。而且 ∇ f \nabla f ∇f是关于常数 L > 0 L>0 L>0 Lipschitz连续的:
∥ ∇ f ( x ) − ∇ f ( y ) ∥ 2 ≤ L ∥ x − y ∥ 2 f o r a n y x , y \|\nabla f(x)-\nabla f(y)\|_2 \leq L\|x-y\|_2\quad for\ any\ x,y ∥∇f(x)−∇f(y)∥2≤L∥x−y∥2for any x,y(或者说二次微分 ∇ 2 f ( x ) ⪯ L I \nabla ^2f(x) \preceq LI ∇2f(x)⪯LI)
那么,梯度下降有 O ( 1 / k ) O(1/k) O(1/k)的收敛率, k k k为迭代次数。也就是说,在 O ( 1 / ϵ ) O(1/\epsilon) O(1/ϵ)次迭代后,可以找到 ϵ \epsilon ϵ误差的次优点。
如果 f f f是强凸的,即存在 m > 0 m>0 m>0,使得 f ( x ) − m 2 ∥ x ∥ 2 2 f(x)-\frac{m}{2}\|x\|^2_2 f(x)−2m∥x∥22是凸的(或者说二次微分 ∇ 2 f ( x ) ⪰ m I \nabla ^2f(x) \succeq mI ∇2f(x)⪰mI),那么收敛率将会达到指数收敛率 O ( γ k ) O(\gamma ^k) O(γk), 0 < γ < 1 0<\gamma<1 0<γ<1。也就是说,在 O ( l o g ( 1 / ϵ ) ) O(log(1/\epsilon)) O(log(1/ϵ))次迭代后,可以找到 ϵ \epsilon ϵ误差的次优点。
优缺点
优点
- 方法简单,每次迭代都很快;
- 对于良态的,强凸问题有很快的收敛速度。
缺点
- 由于许多问题是非强凸或良态的,因此梯度下降往往需要很多次迭代,收敛速度很慢;
- 不能应对不可微的函数。
在非凸问题上的分析
假设 f f f是可微的,且 ∇ f \nabla f ∇f是Lipschitz连续的,但是非凸的。在这种情况下,我们不再寻找最优点,而是寻找稳定点解,那么梯度下降有 O ( 1 / k ) O(1/\sqrt{k}) O(1/k)(或 O ( 1 / ϵ 2 ) O(1/\epsilon^2) O(1/ϵ2))的收敛率。
参考资料
CMU:Convex Optimization