pytorch-tensor basic operation
operation on tensor
本文涉及到的操作包括:基本创建操作,stack,cat,split,chunk,squeeze,unsqueeze,reshape,view…(待添加),可以将以上操作简单分为
- 创建操作
- cat,stack
- gather,scatter_
- split,chunk,unbind
- squeeze,unsqueeze
- reshape ,view
- transpose ,permute
tensor属性
每个torch.tensor都有 torch.dtype,torch.device,torch.layout属性
torch.dtype
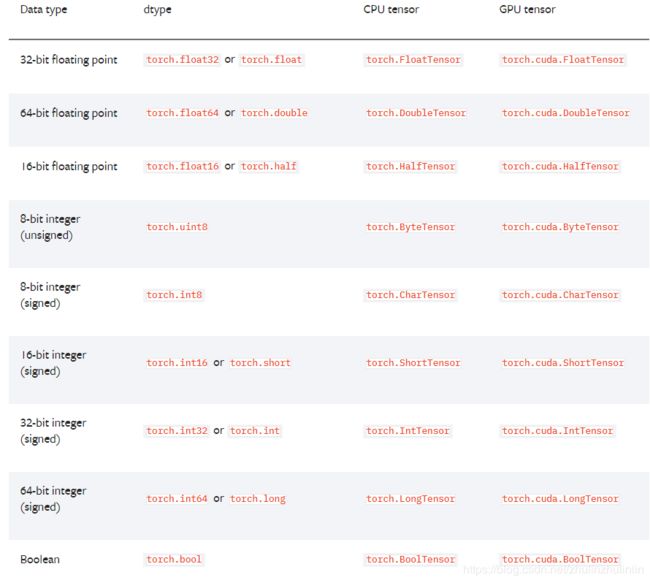
torch.Tensor的默认类型是浮点型(torch.FloatTensor)
torch.device
torch.device代表声明的tensor会在哪个设备上进行 申请内存,类型有 ‘cuda’ 和 ‘cpu’.
torch.device(‘cuda:0’)
torch.layout
torch.layout表示tensor在内存的布局,现在我们支持torch.strided,每一个strided tensor都关联一个torch.Storage,里面存放着数据,而strides表示对内存里的多维数据每一个维度进行步进的长度。strides是一个整数列表。

dtype,device可以用to方法改变
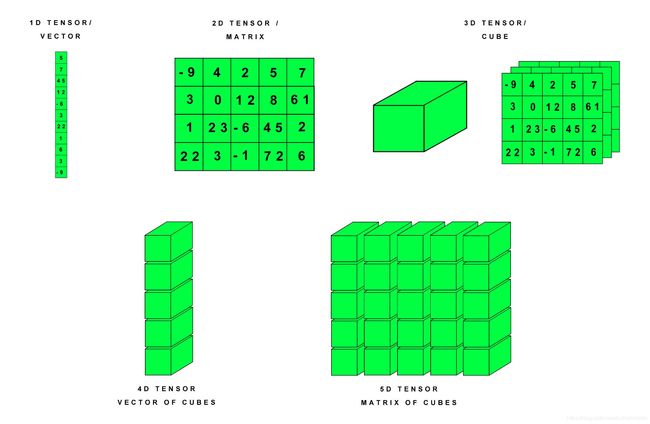
不同维度的tensor
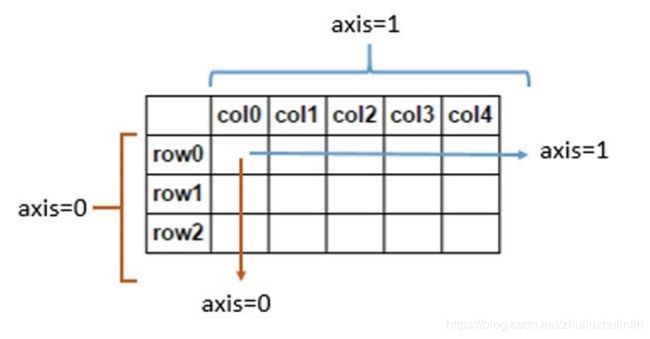
在了解基本操作之前,需要弄清楚一个概念,在pytorch tensor 是用维度来描述张量,而在numpy中用轴来描述array,然而维度这一词也经常用在描述向量的维度,即一个向量是有几个元素组成,即该向量可以表达多少维空间的一个点,注意区分。而对于tensor来说,比如size为(2,3)的张量,维度个数是2,其中维度0的大小为2,维度1的大小为3
【size表示每个维度的大小】
而对于维度理解,可以参考以下图(下图的axis可以 换成dim):
tensor的创建操作
1.从已经存在的序列数据data中创建tensor,利用torch.tensor()构造函数创建tensor,但该方法会复制data,如果从numpy转到tensor,不想复制data,而是共享内存可以使用 torch.as_tensor()方法
2. torch.rand() torch.empty() torch.zeros()
3. 从已有的tensor上创建新tensor
x.new_ones() torch.randn_like()
4.numpy和tensor互换
a.numpy()---->tensor变成numpy
tensor.from_numpy(ndarray)------->numpy变成tensor
stack,cat
cat :torch.cat(seq,dim=0,out=None) ,即沿着dim连接seq中的tensor,所有tensor必须相同的size或为empty,
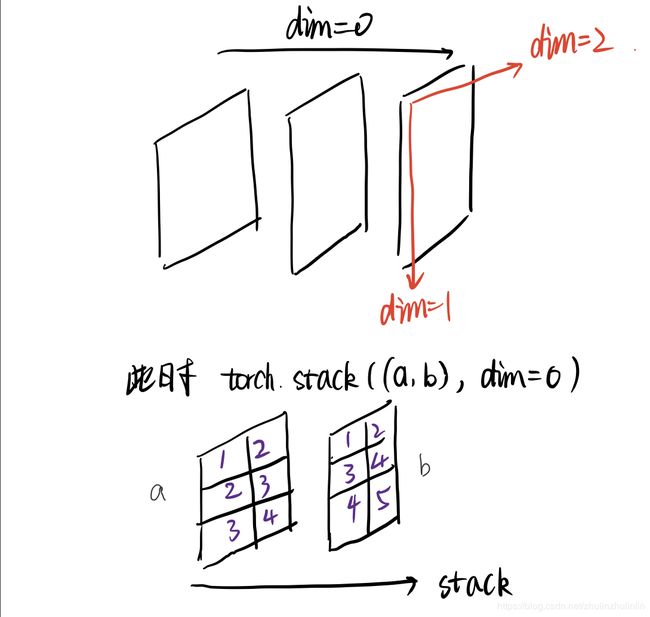
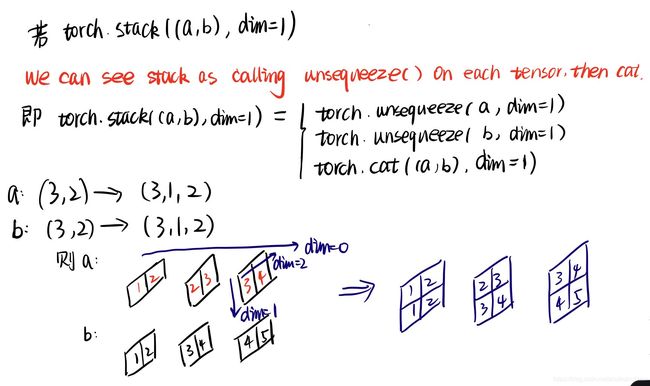
satck:torch.stack(seq,dim=0,out=None),会增加维度值,可以理解为先unsqueeze,再cat

下面是对cat和stack操作的代码,对于二维数组,分别从维度0和维度1进行操作
#cat
import torch
a=torch.tensor([[1,2],[2,3],[3,4]])# 3 x 2
b=torch.tensor([[1,2],[3,4],[4,5]])# 3 x 2
c=torch.cat([a,b],dim=0)
print(c.size())
print(c)
d=torch.cat([a,b],dim=1)
print(d.size())
print(d)
out:
torch.Size([6, 2])#c tensor([[1, 2], [2, 3], [3, 4], [1, 2], [3, 4], [4, 5]]) torch.Size([3, 4])#d tensor([[1, 2, 1, 2], [2, 3, 3, 4], [3, 4, 4, 5]])
#stack
a=torch.tensor([[1,2],[2,3],[3,4]])
b=torch.tensor([[1,2],[3,4],[4,5]])
c=torch.stack([a,b],dim=0)
print(c.size())
print(c)
d=torch.stack([a,b],dim=1)
print(d.size())
print(d)
out:
torch.Size([2, 3, 2])#c tensor([[[1, 2], [2, 3], [3, 4]], [[1, 2], [3, 4], [4, 5]]]) torch.Size([3, 2, 2])#d tensor([[[1, 2], [1, 2]], [[2, 3], [3, 4]], [[3, 4], [4, 5]]])
关于satck结果的解释:
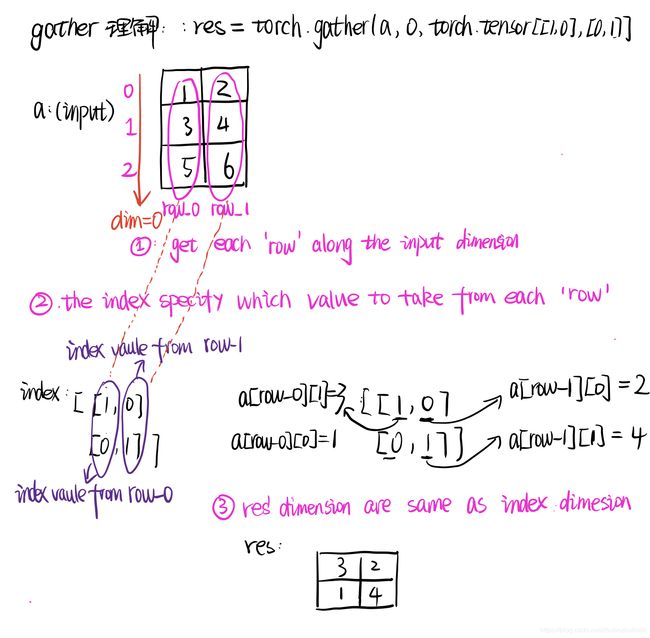
gather
gather:torch.gather(input, dim, index(index必须是torch.tensor类型), out=None)
Let’s start with going through the semantics of the different arguments: The first argument, input, is the source tensor that we want to select elements from. The second, dim, is the dimension (or axis in tensorflow/numpy) that we want to collect along. And finally, index are the indices to index input.
#在维度1上进行操作
a=torch.tensor([[1,2],[3,4],[5,6]])
res=torch.gather(a,1,torch.tensor([[1,0],[0,1],[0,0]]))
print(res)
out:
tensor([[2, 1], [3, 4], [5, 5]])
#在维度0上进行操作
a=torch.tensor([[1,2],[3,4],[5,6]])
res=torch.gather(a,0,torch.tensor([[1,0],[0,1]]))
print(res)
out:
tensor([[3, 2],[1, 4]])
torch.gather creates a new tensor from the input tensor by taking the values from each row along the input dimension dim,the index specify which value to take fro each ‘row’。
输入的index维度大小和输出的结果一样。
详细的解释如下图:
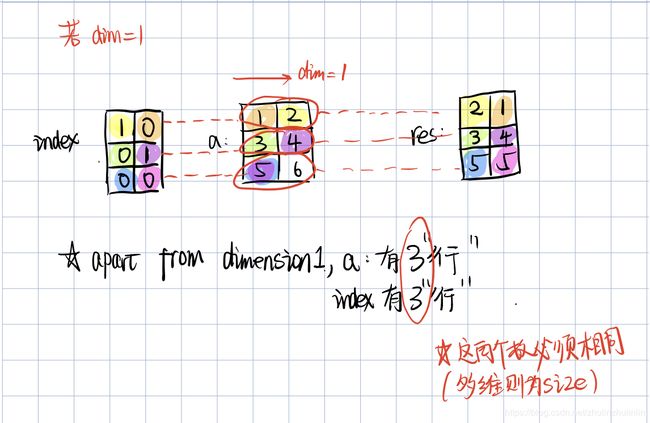
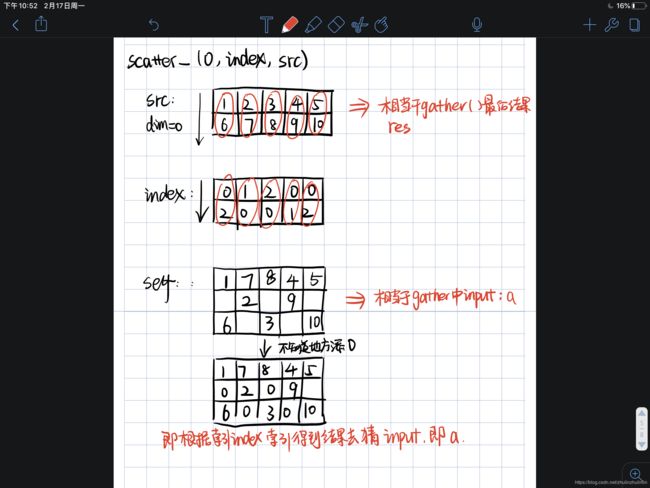
scaterr_()
scatter_(dim,index,src)–>Tensor
scatter_()操作就是gather的逆向操作,gather是根据index从input索引取值得到res,而scatter则是根据index,和res结果反推input.索引规律也一致
#src即res ,b即input
import torch
src=torch.FloatTensor([[1,2,3,4,5],[6,7,8,9,10]])
index=torch.LongTensor([[0,1,2,0,0],[2,0,0,1,2]])
b=torch.zeros(3,5).scatter_(0,index,src)
output:
tensor([[ 1., 7., 8., 4., 5.],
[ 0., 2., 0., 9., 0.],
[ 6., 0., 3., 0., 10.]])
split ,chunk,unbind
torch.chunk(input_tensor, chunks, dim=0)
# 按dim给输入tensor进行分块,chunks为分块的数目,按声明的分块数进行等分
torch.split(tensor, split_size_or_sections, dim=0)
# 将tensor 拆分成相应的组块,按声明的长度进行划分
import torch
a=torch.tensor([[1,2],[3,4],[5,6]])
a.split([1,2],dim=0)
out:
(tensor([[1, 2]]), tensor([[3, 4],
[5, 6]]))
unbind
torch.unbind(input, dim=0) → seq
Removes a tensor dimension.
Returns a tuple of all slices along a given dimension, already without it.
Parameters:
- input (Tensor) – the tensor to unbind
- dim (python:int) – dimension to remove

view and reshape
pytorch view ,reshape可以理解为把输入tensor中的数据按照行优先的顺序排成一维,然后按照参数组合成其它维度的tensor
view和reshape的区别,返回结果是一样的,主要区别在于view可以保证两个tensor 共享内存,而用reshape不能保证这一点,有可能copy了向量,也有可能共享内存了
torch.views merely creates a view of the original tensor.The new tensor will always share its data with the original data.to ensure this ,torch.view impose some contiguity on the shapes of the two tensors
torch.shape doesn’t impose any contiguity constraints ,but also does’t guarantee data sharing.
参考链接
这里不连续的含义是 张量的元素的顺序和新创建和它一样大小的张量的元素顺序不一样,通常转置会导致不连续。 pytorch里有contiguous函数,该函数会返回一个连续的张量:it actually makes a copy of tensor so the order of elements would be same as if tensor of same shape created from scratch.
contiguous详细解释请点击该链接
transpose 和permute
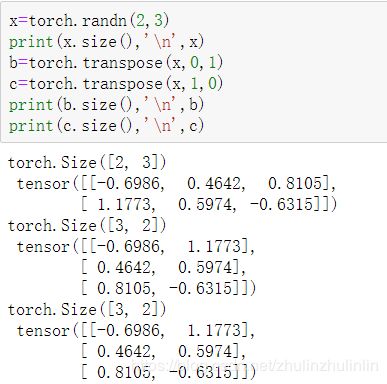
torch.transpose(input,dim0,dim1)
返回被交换两个维度后的tensor out,其中dim0和dim1表示被交换的两个维度,其返回的结果tensor out和之前的input是共享内存的,
transpose只能交换两个维度的顺序,而permute可以灵活的交换多个维度
tensor.permute(*dims)
改变tensor的维度顺序,*dims是期待输出的维度顺序
