看一下MYSQL存储引擎的Memory存储引擎,Memory存储引擎也称之为HEAP存储引擎,从这个存储引擎的名字中呢,
可以知道,所有的数据都保存在内存中的,这就意味着呢,这种存储引擎表的数据呢,一旦MYSQL重启,Memory存储引擎表的数据呢,
就会消失,但是表结构就会保留下来,我们一会在演示时呢,就会看到,Memory存储引擎的表,并不会存在磁盘数据文件,而只存在一个
FRM文件,而这个frm文件呢,就是MYSQL服务器层记录表结构使用的文件,那就是为什么MYSQL服务器重启后,Memory存储引擎表中的
数据会丢失,而表数据不会丢失的原因,因为表结构是存在磁盘文件中的,而数据是保存在内存中的,由于Memory存储引擎的存储特点呢,
我们也知道另外一件事情就是,Memory存储引擎的IO效率要比MYISAM高很多,因为MYISAM只有索引数据,会保存在内存中,而数据是由
操作系统来缓存的,而Memory存储的数据和索引呢,全都是在内存中的,接下来我们先来看一看Memory存储引擎的功能特点,再来给大家
演示一下,这种存储引擎的一种存储方式

首先来看看他的功能特点,Memory存储引擎支持两种索引类型,也就是hash索引和BTree索引,如果在建立索引时呢,
没有指定索引类型时的话呢,默认建立的是hash索引,由于hash索引的特点,如果是在做等值查询的话呢,会非常的快,
但是如果要做范围查询的话,就无法使用hash索引了,所以如果要使用memory存储引擎的话,我们在建立索引的时候呢,
先要了解我们的业务是如何使用存储引擎的表的,如果绝大部分要使用等值查找的话,我们就可以使用hash索引,但是如果我们
是范围查找呢,那就要特别注意了,一定要使用B树索引,使用错误的索引类型呢,是在Memory存储引擎中,最常见的一种
错误之一了,不正确的索引呢会对性能造成很大的影响,大家一定要注意

Memory存储引擎的第二个特点呢,就是所有字段的存储都是固定的长度,也就是说,就算是我们在定义表时,
使用了varchar(10)这样的字段类型,存储时呢,同样会转成char(10),这样固定长度字段的来进行存储,这就要求我们
在定义表结构时,一定要尽力使用符合要求的最小的字段长度,否则就会浪费大量的内存,但是官方版本的MYSQL这个问题
是一定存在的,Memory存储引擎,定义表结构时呢,还有一个很大的限制,不能使用text和blob大字段类型,同样由于大字段
类型呢会浪费很大的内存空间,所以memory存储引擎中呢是不能使用这种类型的

Memory存储引擎的第四个特点呢,就是Memory存储引擎所使用的表呢,他同样是使用表级锁的,所以尽管其所有数据
和索引全部在内存中,但是在一个繁忙的系统中,其性能也不见得比Innodb性能要好,一方面由于Innodb存储引擎呢,
也会把所有的数据和索引缓存在内存中,如果我们访问的是业务数据的话,也是直接从内存中进行读取的,因为另一方面
由于Innodb存储引擎所使用的是行级锁,而Memory所使用的是行级锁,行级锁比表级锁要支持更大的并发,所以吞吐量也会
更高,如果使用memory存储引擎呢,还有一点需要注意,就是memory表的最大大小呢参数max_heap_table_size来决定的,
这个参数的默认值只有16M,所以我们要在memory存储引擎表中呢,存储大量数据的话,需要修改这个参数,而且这个参数的修改呢,
是对于已经存在的memory存储引擎的表呢,是无效的,所以修改参数后,想对已经存在的memory存储引擎的表生效呢,就要对memory
存储引擎的表进行重建,下面对存储引擎的特点进行演示,下面我们就 进入到我们的演示系统,给大家演示memory存储引擎表使用的
注意事项

首先我们还是要建立一个存储引擎的表,按照我们之前的命名规则呢,把这个表命名为mymemory,他需要有几列,
一个是id列,一个是c1列,它是一个varchar列,c2列是一个char类型的列,在这里我们加入一个c3列,c3列是一个
text类型,之前我们在介绍中我们说过,memory存储引擎的表呢,是不支持大字段类型的,我们可以来看一看,如果我们加入
了这么一个列呢,这个表是否能够建立起来,大家看到这里出现了一个错误提示,提示的内容已经很明显了,我们所使用的存储
引擎是不支持这种blob和text列的类型的
create table mymemory(id int,c1 varchar(10),c2 char(10),c3 text)engine=memory;

那我们进行一下修改,把c3列删除之后,正确的语句就变成了这个,这个时候我们就建成了我们的memory存储引擎的表
create table mymemory(id int,c1 varchar(10),c2 char(10))engine=memory;

那首先呢我们先到我们的文件系统下,这个表的存储方式是什么样的,上面显示了所有mymemory开头的数据文件,
大家看到这里只有 一个frm文件,所以这里也从另一点说明呢,memory存储引擎的表呢,是不存在数据存储文件的,
而只有存储表结构的存储文件,frm文件,下面我们来看看memory表的索引

在这里我们为mymemory两个表建立索引,一个是在c1列上的索引,并不指定索引的类型
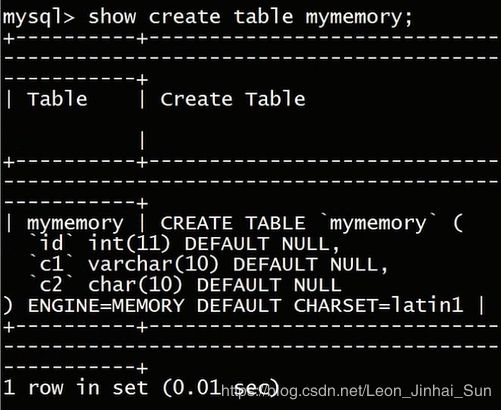
另外我么要在c2上建立索引,这个时候我们要指定我们使用的b树索引
create index idx_c1 on mymemory(c1);
create index idx_c2 using btree on mymemory(c2);
我们来看看索引是不是和我们想象的一样
show index from mymemory\G

大家可以看到这个表上的两个索引第一个是第一列上的索引,hash索引类型的,在第二列上的索引,由于我们指定了是b树的索引,
所以他的索引类型是b树类型的索引
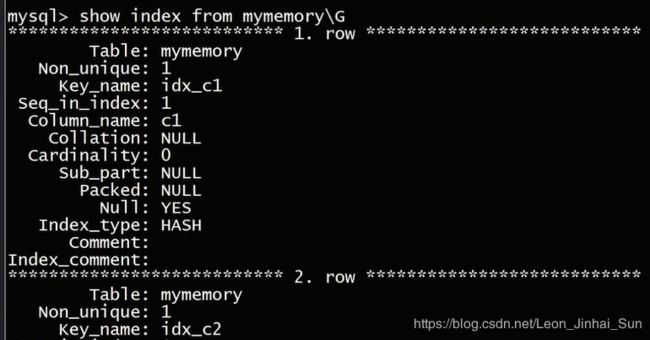
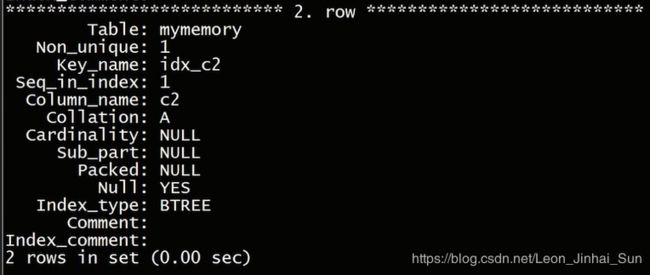
这就是我们刚才所讲到的,存储引擎支持的两种索引类型,那么我们再来看一看表的状态信息
show create table mymemory\G
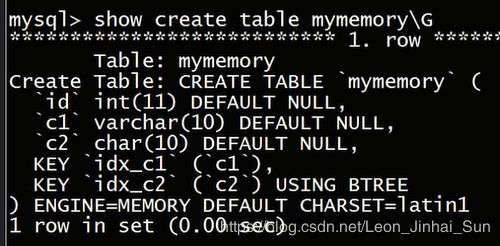
对于这个表的结构呢,相对应的索引信息是在这,我们只需要查看mymemory这个表就可以了
show table status like 'mymemory\G'

大家可以看到,这里写的行的类型是固定长度,从另一方面说明了就是说,memory存储引擎中的表呢,所有列的长度都是固定的,
其实我们之前定义了varchar长度的c2,但是他同样会被转换为固定长度,来进行存储,以上就是存储引擎的使用方式,和他的存储
函数的一些特点
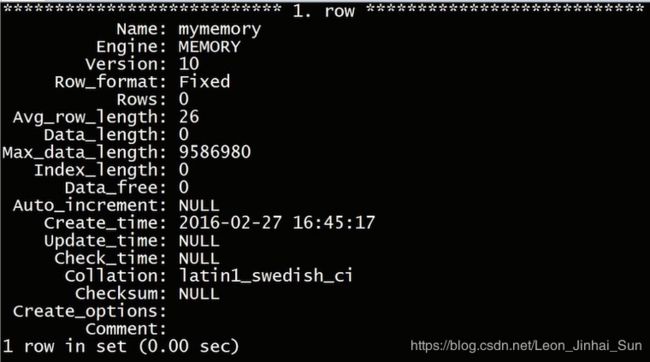
下面我们来看看memory存储引擎中,有一个比较混淆的概念,就是memory存储引擎表和临时表,这两个概念是非常
容易让人混淆的,临时表可以分成两种,一种是由查询分析器,查询优化器列的查询,所使用的一些表,也就是内部临时表,
而另一种是使用create temporay table语句建立的临时表,无论哪种临时表,只有当前session是可见的,Memory存储引擎的
表呢,所以memory存储引擎的表并不是临时表,另外对于系统使用的临时表来说,有两种情况,在限制以内会使用Memory存储
引擎的表,而如果超过了限制呢,或者要使用text和blob这种大字段时呢,会使用myisam来建立临时表,这就是我们刚才所说的
两种情况,如果系统使用了myisam的临时表呢,这时的查询性能就会受到影响,而对于create tempory table,语句建立的临时表
呢,是可以使用任何的存储引擎的
那么经过上面的分析和介绍呢,我们就知道了Memory存储引擎,使用hash索引,对于等值查找是非常高效的,
所以对于一些查找表和映射表呢,比如邮编和地区的对应关系表,只会使用邮编这种等值查找,这种查询就可以
使用memory存储引擎的查找,另外由于memory引擎的表是易失的,所以可以用于存储一些中间结果,或者是做一些
周期记录聚合表的使用,不过无论哪种场景呢,要注意一点,memory存储引擎的表呢,MYSQL重启以后就会丢失,
所以使用memory存储引擎表的数据呢,一定是要可以再生的

有人可能有这样的想法,使用主从复制,并且在主中使用memory引擎的表,而对于相同的表呢,在从DB中呢,
使用其他引擎,InnoDB,或者MYISAM,想以这样的方式呢,来保证当主DB重启时,从DB中还有一份可用的数据,
但是如果真是这样想的话,可能会法相实际情况不会像我们想象中的那样,因为主DB在重启时,会重建memroy
引擎的表,所以从DB的表也会被重建,所以数据还是会丢失,这一点也是需要大家来注意的