SQL笔试题练习记录
SQL笔试题练习记录
- day 1
- day2
- 行列转换
- 窗口函数
- day3
- day 4
- day 5
day 1
https://zhuanlan.zhihu.com/p/80905376
1、用户行为分析
(1) 取某一天查看用户资料行为(event_name=profile.index)的20,50,80分位点
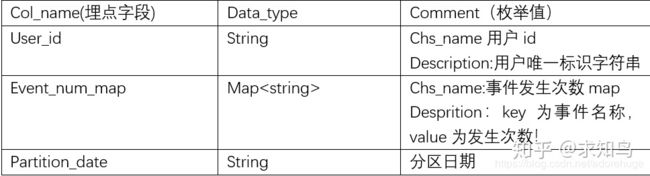
思路:分位数采用 percentile_approx(),where定位某一天某一用户
实现:
select percentile_approx(event_num_map, array(0.2,0.5,0.8),9999)
from event_summary
where Partition_date = ${date}
and event_name = profile.index
(2) 查看用户资料行为的不同行为频次的用户分布

思路:
event_summary: user_id 一个行为 行为次数
连接表,主表是某时间区间的用户id,一个事件为一条记录,所以id会有大量重复;
次表定义每个用户每个行为的行为频次字段。之所以用到两个表是因为占比字段需要用到主表
实现:
select t2."行为频次", count(distinct t2.user_id),
count(distinct t2.user_id)/count(t1.user_id),
sum(count(distinct t2.user_id)) over(partition by t2."行为频次")
from (select User_id from event_summary
where Partition_date between ${begin_date} and ${end_date}) t1
left join (select user_id,
(case when event_num_map between 0 and 5 then "0-5"
case when event_num_map between 5 and 15 then "5-15"
else "其他" end ) as "行为频次"
from event_summary
where Partition_date between ${begin_date} and ${end_date}) t2
on t1.user_id = t2.user_id
group by t2.行为频次
2、流失用户分析
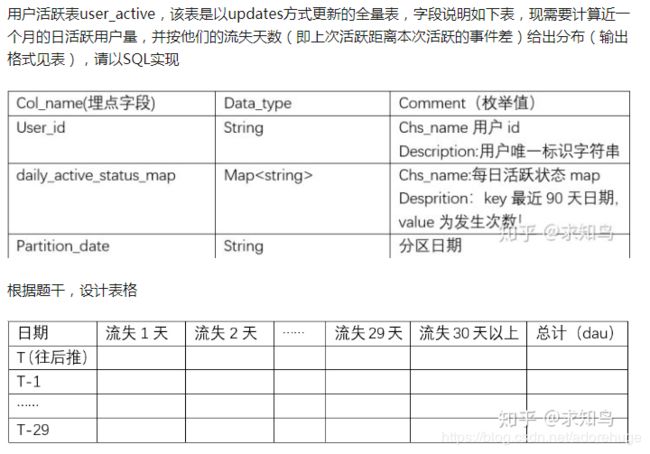
思路:复写表,表1输出某一天活跃的用户表,表2输出不活跃用户表,两者连接后,按日期group by,其日期差值就是流失的天数
题目感觉条件不足,先不考虑了
代码:
select Partition_date,case when datediff(t2.Partition_date,t1.Partition_date)=1 then count(distinct t2.user_id) end) as '流失1天',
case when datediff(t2.Partition_date,t1.Partition_date)=2 then count(distinct t1.user_id) end) as '流失2天',
case when datediff(t2.Partition_date,t1.Partition_date)=3 then count(distinct t1.user_id) end) as '流失3天',
case when datediff(t2.Partition_date,t1.Partition_date)>=30 then count(distinct t1.user_id) end) as '流失30天以上',
from (
select user_id,Partition_date
from usre_active
where daily_active_status_map=1
)t1
left join (
select user_id,Partition_date
from usre_active
where daily_active_status_map=1
)t2
on t1.user_id=t2.user_id
where t2.user_id is null
group by t1.Partition_date
order by Partition_date desc
分位数函数
percentile_approx()和 percentile()
percentile(col, p)、percentile_approx(col, p,B),返回col列p分位上的值。B用来控制内存消耗的精度。实际col中distinct的值
p可以是数值也可以是数组,一般默认以升序的形式取数。
day2
行列转换
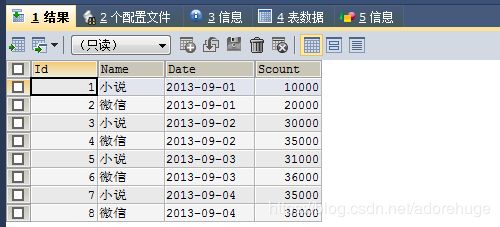
1、列转行统计数据
select Date,
max(case Name when "小说" then Scount else 0 end) 小说,
max(case Name when "微信" then Scount else 0 end) 微信
from tabname
group by Date

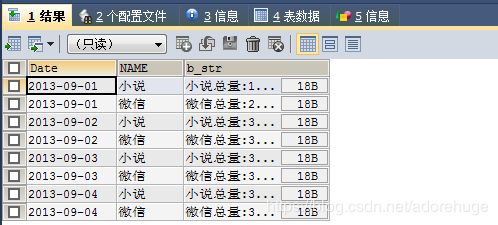
2、行转列统计数据
select date,name,group_concat(name,'总量:',Scount) as b_str from tabname group by date,name
窗口函数
1、用于排序
row_number() over(partition by column A order by column B) 1,2,3,4,5
rank() over(partition by column A order by column B) 1,2,2,4,5
dense_rank() over(partition by column A order by column B) 1,2,2,3,4
eg1:
现有交易数据表user_goods_table如下:
user_name 用户名
goods_kind 用户订购的的外卖品类
现在老板想知道每个用户购买的外卖品类偏好分布,并取出每个用户购买最多的外卖品类是哪个。
select t.user_name, t.goods_kind from
(select user_name, goods_kind, row_number() over(partition by user_name order by goods_kind desc) as rank
from user_goods_table
group by user_name, goods_kind) as t
where t.rank = 1
eg2:统计每一个客户最近下的订单是第几次下的订单
select t.customerID, max(t.rank)
from (
select customerID,totalPrice, DID,
row_number() over(partition by customerID order by totalPrice) as rank from OP_order
) as t
group by t.customerID
**eg.3:**统计每一个客户所有的订单中购买的金额最小,并统计该订单中,客户是第几次购买的
思路:
1)先按照客户进行分组,然后按照客户下单的时间进行正序排列,并编号(rowIndex),生成临时表baseDate;
2)再按照客户进行分组,然后按照客户下单的金额进行倒序排列,并编号(rowIndex),生成临时表basePrice;
3)最后取basePrice中编号为1的数据,然后根据id到baseDate中去查,即可;
with baseDate as(
select Id,UserId,TotalPrice,orderTime,ROW_NUMBER() over (partition by UserId order by orderTime) as rowIndex from OrderInfo
),
with basePrice as(
select Id,UserId,TotalPrice,orderTime,ROW_NUMBER() over (partition by UserId order by TotalPrice ) as rowIndex from OrderInfo
)
select * from baseDate
where Id in (select from basePrice where rowIndex=1)
2、用户分组查询
ntile(5) over(order by sum(pay_amount) desc) as level2
将整表数据进行均匀切片分组,默认是对表在不做任何操作之前进行切片分组。
eg:
现有交易数据表user_sales_table如下:
user_name 用户名
pay_amount 用户支付额度
现在老板想知道支付金额在前20%的用户。
select t.user_name
from (select user_name,
ntile(5) over(partition by user_name order by sum(pay_amount) desc) as level2
from user_sales_table) as t
where t.level2 = 1
3、偏移分析
lead(expression,offset,default) over(partition by … order by …) 某一行数据向下偏移offset位
DATE_SUB(date,INTERVAL expr type) 函数从日期减去指定的时间间隔。 second/minute/hour/day/week/month/quarter/year
Cast() 函数类型转换。CHAR字符型/DATE日期/DATETIME日期和时间/DECIMALfloat/SIGNEDint/ TIME时间
eg:
现有用户登陆表user_login_table如下:
user_name 用户名
date 用户登陆时间
现在老板想知道连续7天都登陆平台的重要用户。
select t1.user_name
from (select user_name, date,lead(date,7) over(partition by user_name order by date desc) as date_7
from user_login_table) as t1
where t1.date is not null
and date_sub(cast(t1.date as date) ,interval 7 day) = cast(t1.date_7 as date)
4、没有窗口函数,这类问题一般采用自连接解决
输入表结构:
create table mianshi1 (
id varchar(20),
dates varchar(20),
v_num int
输出表结构:

# 当月访问次数
select id, dates, sum(v_num)
from mianshi1
group by id,dates
# 最大访问次数与总访问次数
with temp as(
select id, dates, sum(v_num) from mianshi1 group by id,dates)
select t2.id, t2.dates,max(t1.v_num), sum(t1.v_num)
from temp as t1, temp as t2
where t1.id = t2.id
and t1.date <= t2.date
group by t2.id,t2.date
day3
拼多多2020学霸批
题目转自https://blog.csdn.net/weixin_44915703/article/details/99414226
1、用户活动订单金额反馈


(1)创建表act_output,保存以下信息:
区分不同活动,统计每个活动对应所有用户在报名参与活动之后产生的总订单金额、总订单数(一个用户只能参加一个活动)。
create table act_output as
select act.act_id, sum(ord.ord_amt) as total_amount, count(ord.ord_id) as total_id
from ord left join act_user as act on ord.user_id=act.user_id
where act.create_time <= ord.create_time
group by act.act_id
(2)加入活动开始后每天都会产生订单,计算每个活动截止当前(2019-08-12)平均每天产生的订单数,活动开始时间假设为用户最早报名时间。
select act.act_id, round(count(ord.ord_id) / datediff('2019-08-12',min(act.create_time)),3) as avg_order
from ord left join act_user as act on ord.user_id=act.user_id
where act.create_time <= ord.create_time
group by act.act_id
ps:时间的相关函数
- 时间格式的转换
https://www.cnblogs.com/lydg/p/11362388.html - 求时间差
TIMESTAMPDIFF(单位,开始时间,结束时间) == 结束时间-开始时间
DATEDIFF(datepart,startdate,enddate) 默认返回两个date之间日期的差值 = startdate - enddate - date_sub
DATE_SUB 将从一个日期/时间值中减去一个时间值(时间间隔)
DATE_SUB(date,INTERVAL expr type)
eg:
select DATE_SUB(CURDATE(), INTERVAL 1 YEAR) as yearTime
SELECT DATE_SUB(‘2010-08-12’, INTERVAL ‘3-2’ YEAR_MONTH) AS NewDate
2、用户访问操作流水
(1)计算网站每天的访客数以及他们的平均操作次数;
select log_time, count(distinct user_id) as user_sum, count(opr_type)/count(distinct user_id) as avg_opr
from tracking_log
group by log_time
(2)统计每天符合A操作后B操作的操作模式的用户数,即要求AB相邻。
select r.log_time, count(distinct r.user_id)
from ( select user_id, opr_type, lead(opr_id,1) over(partition by user_id order by log_time) as offset_opr, log_time
from tracking_log) as r
where opr_type='A' and offset_opr='B'
group by log_time
(3)计算网络每日新增访客表
select t1.log_time, count(distinct t1.user_id)
from tracking_log t1
left join
(select user_id, min(log_time) as start_time
from tracking_log
group by user_id) t2
on t1.user_id = t2.user_id and t1.log_time = t2.start_time
group by t1.log_time
(4)新增访客的第2日、第30日回访比例。
新增列 first_log,t
create view view1 as
select user_id,log_time,
min(log_time) over(partition by user_id order by log_time) as first_log,
row_number() over(partition by user_id,log_time) as t
from tracking_log
去重,新增一列by_day,用于留存天数的筛选
create view view2 as
select *, datediff(log_time, first_log) as by_day
from view1
where t=1
第二日回访的比例 = 第二日回访用户数/第一日新增访客数
第三十日回访的比例 = 第三十日回访用户数/第一日新增访客数
create view view3 as
select
sum(case when by_day=0 then 1 else 0 end) as day_0,
sum(case when by_day=1 then 1 else 0 end) as day_2,
sum(case when by_day=29 then 1 else 0 end) as day_30
from view4
group by first_log
select first_log, day_2/day_0 as day2_return, day_30/day_0 as day3_return from view4
day 4
摩拜单车,题目转自https://zhuanlan.zhihu.com/p/80925454
1、


Orders表示订单表,包括优惠券金额,订单金额及产生订单的城市代码(注:城市代码包括已开城市Citycode及乱码/NA/不在已开城市代码中的数字)。City_conf表示摩拜所开城市列表,包括城市名称,城市代码及所属大区。请统计每个城市优惠券cover的订单费用。
(注:1. 如果优惠券金额大于订单金额则cover的是订单费,否则为优惠券金额。2. 所有归不到城市列表中的订单统一为others)
一般出现如果那么的都可以用case when then else end 来解决
select r.name,sum(r.fee)
from (select
case when coupon_fee >= order_fee then order_fee else coupon_fee end as fee
case when name is null then 'others' else name end as city
from orders as o left join city_conef as c
on o.citycode = c.citycode) as r
group by r.name
2、

select m.name, count(1) as num
from metro as m left join orders as o
on trunc(m.lng,2)=trunc(o.lng,2) and trunc(m.lat,2)=trunc(o.lat,2)
where o.time between '2017-07-01 07:00:00' and '2017-07-01 09:00:00'
group by m.name
order by num desc limit 10
tips:
TRUNC(number[,decimals]),直接截去不四舍五入,round() 四舍五入
TRUNC(89.985,2)=89.98
TRUNC(89.985,-1)=80
count(1) 和 count() 和 count(字段)
count(1)和count()的作用:
都是检索表中所有记录行的数目,不论其是否包含null值。但是count(1)比count()效率更高
count(字段)与count(1)和count()的区别:
count(字段)的作用是检索表中的这个字段的非空行数,不统计这个字段值为null的记录
day 5
转自https://zhuanlan.zhihu.com/p/81043448
VIPkid数据分析笔试
1、

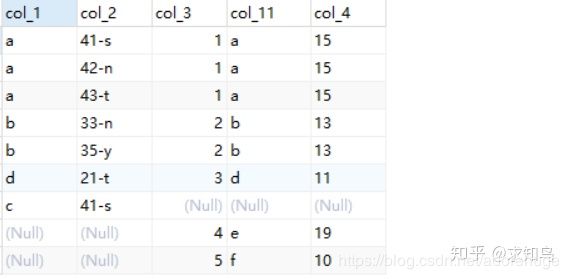
select A.col_1,A.col_2,B.col_3,B.col_1 as B.col_11,B.col_4
from table_A A full join table_B B on A.col_1 = B.col_1
全连接
2、表 order_record

select t.month,t.sum_amount,sum(t.sum_amount) over(order by t1.month) as add_amount
from(select left(date(paid_time),7)as month, sum(amount) as sum_amount
from order_record
group by month) as t1
-
累加求和
参考https://www.cnblogs.com/mingdashu/p/12100734.html
sum() over(partiotion by A ) 按照A列分组后,分组求和
sum() over(order by B ) 按照B列元素累加求和
sum() over(partition by A order by B) 按照A列分组后,对每个小组内按B列累加求和 -
提取日期的部分
日期是字符串格式:substr(str, start , len)
日期是日期格式:先提取日期中的成分,再用字符串截取的方式选择。
DATE() - 格式 YYYY-MM-DD
DATETIME() - 格式: YYYY-MM-DD HH:MM:SS
TIMESTAMP() - 格式: YYYY-MM-DD HH:MM:SS
YEAR() - 格式 YYYY 或 YY, int
MONTH() -返回月份值,int
DAY() - 返回日期值, int