Java开源序列化框架:Kryo说明文档翻译
原文链接:https://github.com/EsotericSoftware/kryo/blob/master/README.md
版本编号:5.0.0 RC4部分内容保留原版英文,不影响阅读。
Kryo是一个高效快速的Java序列化框架,拥有更快速、省内存、API简单等优点。可用于将对象持久保存到文件,数据库或通过网络。
Kryo还可以执行自动的深层和浅层复制/克隆。 这是从对象到对象的直接复制,而不是从对象到字节的复制。
Contact / Mailing list
请使用 Kryo mailing list 进行问题,讨论和支持。 请将Kryo问题追踪器的使用限制为错误和增强功能,而不是问题,讨论或支持。
目录
- 最近版本
- 安装
- 使用Maven
- 不适用Maven
- 快速开始
- IO
- Output
- Input
- ByteBuffers
- Unsafe buffers
- Variable length encoding
- Chunked encoding
- Buffer performance
- 读写对象
- Round trip
- 深复制和浅复制
- 引用
- 引用解析器
- 引用限制
- 上下文
- 重置
- 序列化器框架
- 类注册
- 类解析器
- 自定义注册
- 默认序列化器
- 序列化器工厂
- 创建对象
- 实例化策略
- 重写创建
- Final类
- 闭包
- 压缩与加密
- 类注册
- 实现一个序列化器
- 序列化器引用
- 嵌套序列化器
- Kryo异常
- 堆内存
- 处理null值
- 泛型
- KryoSerializable接口
- 序列化复制
- 实现KryoCopyable接口
- 不可变的序列化器
- 序列化器引用
- Kryo版本控制与更新
- 互通性
- 兼容性
- 序列化器
- FieldSerializer
- 缓存字段设置
- FieldSerializer注解
- VersionFieldSerializer
- TaggedFieldSerializer
- CompatibleFieldSerializer
- BeanSerializer
- CollectionSerializer
- MapSerializer
- JavaSerializer 和 ExternalizableSerializer
- FieldSerializer
- 日志
- 线程安全
- 池化
- Benchmarks
- 友情链接
- Projects using Kryo
- Scala
- Clojure
- Objective-C
Recent releases
5.0.0-RC4 第四版候选版本,基于反馈改进了先前的RC。 也可以参考 Migration to v5 将 kryo 4.x 升级。
5.0.0-RC1 解决了许多问题,并进行了许多期待已久的改进。
4.0.2 带来了一些增量修复和改进。
Installation
Kryo JAR包可在 发布页面 和 Maven仓库 获得。Kryo的最新快照(包括master快照的版本)位于 Sonatype Repository.
With Maven
要使用最新的Kryo版本,请编辑您的 pom.xml:
<dependency>
<groupId>com.esotericsoftwaregroupId>
<artifactId>kryoartifactId>
<version>5.0.0-RC4version>
dependency>
要使用最新的Kryo快照,请这么操作:
<repository>
<id>sonatype-snapshotsid>
<name>sonatype snapshots reponame>
<url>https://oss.sonatype.org/content/repositories/snapshotsurl>
repository>
<dependency>
<groupId>com.esotericsoftwaregroupId>
<artifactId>kryoartifactId>
<version>5.0.0-RC5-SNAPSHOTversion>
dependency>
Without Maven
并非每个人都是Maven粉丝。 在没有Maven的情况下使用Kryo需要将 Kryo JAR 配置到你的 classpath。
Quickstart
我们先看看这个JAR包怎么使用,下面有个示例:
import com.esotericsoftware.kryo.Kryo;
import com.esotericsoftware.kryo.io.Input;
import com.esotericsoftware.kryo.io.Output;
import java.io.*;
public class HelloKryo {
static public void main (String[] args) throws Exception {
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
SomeClass object = new SomeClass();
object.value = "Hello Kryo!";
Output output = new Output(new FileOutputStream("file.bin"));
kryo.writeObject(output, object);
output.close();
Input input = new Input(new FileInputStream("file.bin"));
SomeClass object2 = kryo.readObject(input, SomeClass.class);
input.close();
}
static public class SomeClass {
String value;
}
}
Kryo类自动执行序列化。 Output和Input类处理缓冲字节,并可选地刷新到流。
本文档的其余部分详细介绍了它的工作方式以及该库的高级用法。
IO
Kryo使用相关的IO类对数据进行输入输出操作。这些IO类是非线程安全的。
Output
Output类是一个输出流,它将数据写入字节数组缓冲区。 如果需要字节数组,则可以直接获取并使用此缓冲区。 如果为Output提供了输出流,则它将在缓冲区已满时将字节刷新到流,否则Output可以自动增加其缓冲区。 Output类具有许多有效地将基元和字符串写入字节的方法。 它在一个类中提供与DataOutputStream,BufferedOutputStream,FilterOutputStream和ByteArrayOutputStream相似的功能。
Tip: Input和Output类包含ByteArrayOutputSteam的所有方法。我们几乎很少需要将Output的内容再刷新到ByteArrayOutputSteam中。
Output类在写入OutputStream时会缓冲字节,因此在写入完成后必须调用“ flush”或“ close”才能将缓冲的字节写入OutputStream。 如果没有提供OutputStream,则不需要调用“ flush”或“ close”。 与许多流不同,可以通过设置位置或设置新的字节数组或流来重用Output实例。
输出在写入OutputStream时会缓冲字节,因此在写入完成后必须调用“ flush”或“ close”才能将缓冲的字节写入OutputStream。 如果没有提供OutputStream,则不需要调用“ flush”或“ close”。 与许多流不同,可以通过设置位置或设置新的字节数组或流来重用Output实例。
Tip: 由于Output已经缓冲,因此没有必要将Output刷新到BufferedOutputStream。
零参数Output构造函数创建一个未初始化的Output。 必须先调用输出setBuffer,然后才能使用输出。
Input
Input类是一个InputStream,它从字节数组缓冲区中读取数据。 如果需要从字节数组读取,则可以直接设置此缓冲区。 如果为Input提供了InputStream,则在读取缓冲区中的所有数据后,它将从流中填充缓冲区。 输入有许多方法可以有效地从字节中读取基元和字符串。 它提供与DataInputStream,BufferedInputStream,FilterInputStream和ByteArrayInputStream相似的功能,所有这些功能都在一个类中。
Tip: 输入提供ByteArrayInputStream的所有功能。 很少要从ByteArrayInputStream读取Input。
如果调用了输入close,则关闭输入的InputStream(如果有)。 如果不从InputStream读取,则不必调用close。 与许多流不同,可以通过设置位置和限制或设置新的字节数组或InputStream来重用Input实例。
零参数Input构造函数创建一个未初始化的Input。 必须先调用输入“ setBuffer”,然后才能使用输入。
ByteBuffers
ByteBufferOutput和ByteBufferInput类的工作方式与Output和Input完全相同,不同的是它们使用ByteBuffer而不是字节数组。
Unsafe buffers
UnsafeOutput,UnsafeInput,UnsafeByteBufferOutput和UnsafeByteBufferInput类的工作方式与非unsafe输出类完全相同,但在许多情况下,它们使用sun.misc.Unsafe可获得更高的性能。 要使用这些类,Util.unsafe必须为true。
使用不安全缓冲区的不利之处在于执行序列化的系统的本机字节序和数字类型表示会影响序列化的数据。 例如,如果将数据写入X86并在SPARC上读取,则反序列化将失败。 同样,如果使用不安全的缓冲区写入数据,则必须使用不安全的缓冲区读取数据。
不使用可变长度编码时,不安全缓冲区的最大性能差异是使用大型原始数组。 可以对不安全的缓冲区或仅对特定字段(使用FieldSerializer时)禁用可变长度编码。
Variable length encoding
IO类提供了读写可变长度int(varint)和long(varlong)值的方法。 通过使用每个字节的第8位来指示是否跟随更多字节来完成此操作,这意味着varint使用1-5个字节,而varlong使用1-9个字节。 使用可变长度编码是更昂贵的,但是使序列化的数据要小得多。
写入可变长度值时,可以针对正值或针对负值和正值优化该值。 例如,当针对正值进行优化时,在一个字节中写入0到127,在两个字节中写入128到16383,等等。但是,较小的负数在5字节时是最坏的情况。 如果未针对正值进行优化,则这些范围将下移一半。 例如,在一个字节中写入-64至63,在两个字节中写入64至8191和-65至-8192,等等。
输入和输出缓冲区提供了读取和写入固定大小或可变长度值的方法。 还有一些方法允许缓冲区决定写入固定大小还是可变长度值。 这允许序列化代码确保将可变长度编码用于非常常见的值,如果使用固定大小,该值将使输出膨胀,同时仍允许缓冲区配置确定所有其他值。
| Method | Description |
|---|---|
| writeInt(int) | Writes a 4 byte int. |
| writeVarInt(int, boolean) | Writes a 1-5 byte int. |
| writeInt(int, boolean) | Writes either a 4 or 1-5 byte int (the buffer decides). |
| writeLong(long) | Writes an 8 byte long. |
| writeVarLong(long, boolean) | Writes an 1-9 byte long. |
| writeLong(long, boolean) | Writes either an 8 or 1-9 byte long (the buffer decides). |
要禁用所有值的可变长度编码,必须重写writeVarInt,writeVarLong,readVarInt和readVarLong方法。
Chunked encoding
先写一些数据的长度,然后写数据,这很有用。 如果提前不知道数据长度,则需要对所有数据进行缓冲以确定其长度,然后可以写入长度,然后写入数据。 为此使用单个大缓冲区将阻止流传输,并且可能需要不合理的大缓冲区,这是不理想的。
块编码通过使用较小的缓冲区解决了此问题。 当缓冲区已满时,将写入其长度,然后写入数据。 这是一块数据。 缓冲区将被清除,直到没有更多数据可写入为止。 长度为零的块表示块的末尾。
Kryo提供了用于进行分块编码的类。 OutputChunked用于写入分块数据。 它扩展了Output,因此具有所有方便的数据写入方法。 当OutputChunked缓冲区已满时,它将块刷新到另一个OutputStream。 endChunks方法用于标记一组块的结尾。
OutputStream outputStream = new FileOutputStream("file.bin");
OutputChunked output = new OutputChunked(outputStream, 1024);
// Write data to output...
output.endChunks();
// Write more data to output...
output.endChunks();
// Write even more data to output...
output.close();
要读取分块的数据,请使用InputChunked。 它扩展了Input,因此具有所有方便的方法来读取数据。 读取时,InputChunked在到达一组块的末尾时似乎会到达数据的末尾。 即使没有从当前组块中读取所有数据,nextChunks方法也会前进到下一组组块。
InputStream outputStream = new FileInputStream("file.bin");
InputChunked input = new InputChunked(inputStream, 1024);
// Read data from first set of chunks...
input.nextChunks();
// Read data from second set of chunks...
input.nextChunks();
// Read data from third set of chunks...
input.close();
Buffer performance
通常,输出和输入可提供良好的性能。 如果不安全的缓冲区的跨平台不兼容性是可接受的,则它们的性能同样好或更好,尤其是对于原始数组。 ByteBufferOutput和ByteBufferInput的性能稍差一些,但是如果字节的最终目的地必须是ByteBuffer,则可以接受。
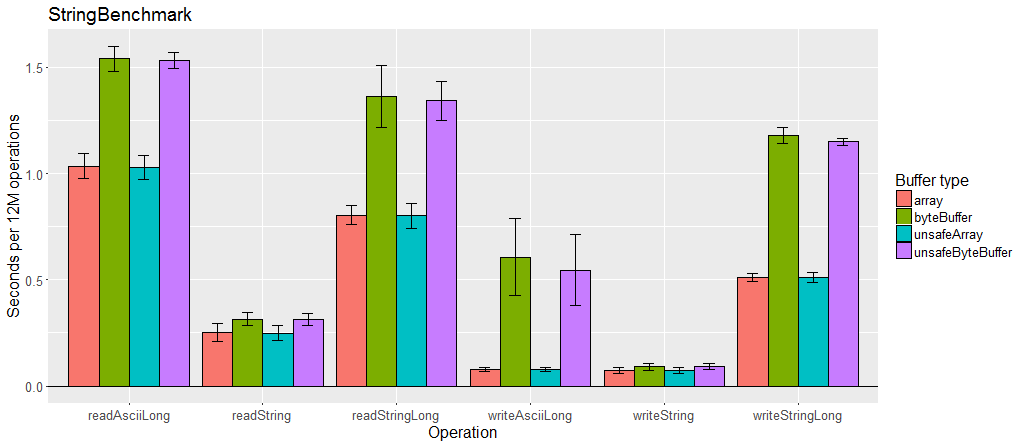
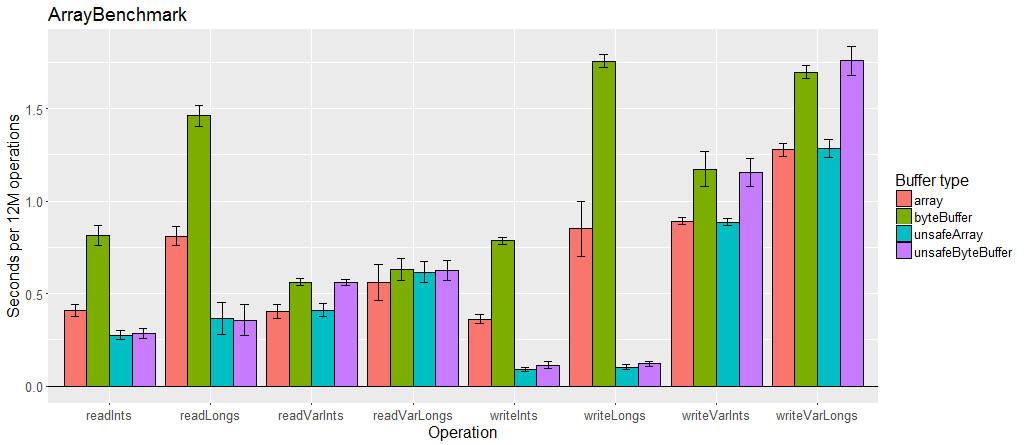
可变长度编码比固定值慢,尤其是在使用大量数据的情况下。
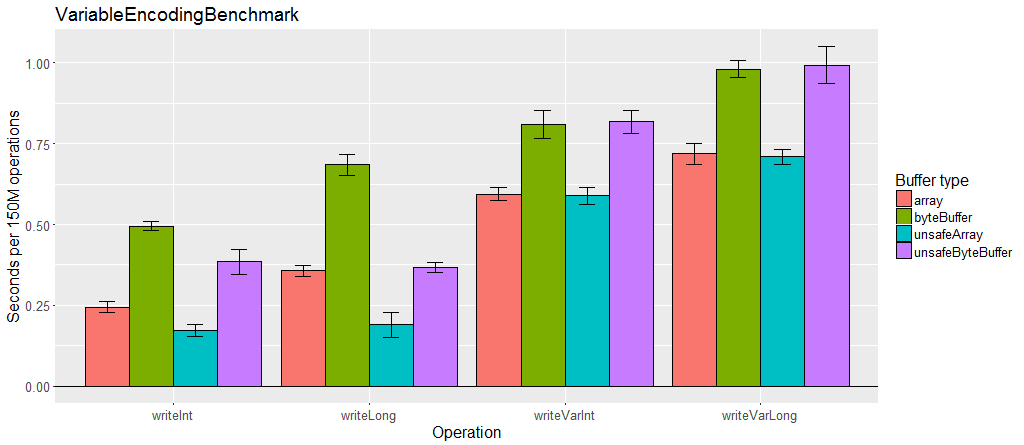
块编码使用中间缓冲区,因此它将所有字节添加一个附加副本。 仅此一项是可以接受的,但是在可重入序列化器中使用时,序列化器必须为每个对象创建一个OutputChunked或InputChunked。 在序列化过程中分配和垃圾回收这些缓冲区可能会对性能产生负面影响。
Reading and writing objects
Kryo具有三套读取和写入对象的方法。 如果该对象的具体类未知,且对象可以为null:
kryo.writeClassAndObject(output, object);
Object object = kryo.readClassAndObject(input);
if (object instanceof SomeClass) {
// ...
}
如果该类是已知的并且该对象可以为null:
kryo.writeObjectOrNull(output, object);
SomeClass object = kryo.readObjectOrNull(input, SomeClass.class);
如果类是已知的,该对象不能为null:
kryo.writeObject(output, object);
SomeClass object = kryo.readObject(input, SomeClass.class);
所有这些方法都首先找到要使用的适当的序列化器,然后使用该序列化器对对象进行序列化或反序列化。 序列化程序可以调用这些方法进行递归序列化。 Kryo自动处理对同一对象的多个引用和循环引用。
除了读取和写入对象的方法外,Kryo类还提供了一种注册序列化器,有效读取和写入类标识符,为不接受空值的序列化器处理空对象以及处理读取和写入对象引用(如果启用)的方法。 这使序列化程序可以专注于其序列化任务。
Round trip
在测试和探索Kryo API时,将对象写入字节,然后将这些字节读回到对象可能很有用。
Kryo kryo = new Kryo();
// Register all classes to be serialized.
kryo.register(SomeClass.class);
SomeClass object1 = new SomeClass();
Output output = new Output(1024, -1);
kryo.writeObject(output, object1);
Input input = new Input(output.getBuffer(), 0, output.position());
SomeClass object2 = kryo.readObject(input, SomeClass.class);
在此示例中,输出从容量为1024字节的缓冲区开始。 如果将更多字节写入输出,则缓冲区的大小将无限制地增加。 无需关闭输出,因为尚未为其提供OutputStream。 输入直接从输出的byte []缓冲区读取。
Deep and shallow copies
Kryo支持使用从一个对象到另一个对象的直接分配来制作对象的深层复制和浅层复制。 这比序列化为字节并返回对象的效率更高。
Kryo kryo = new Kryo();
SomeClass object = ...
SomeClass copy1 = kryo.copy(object);
SomeClass copy2 = kryo.copyShallow(object);
所有正在使用的序列化程序都需要支持复制。 Kryo随附的所有序列化程序均支持复制。
与序列化一样,复制时,如果启用了引用,则Kryo会自动处理对同一对象的多个引用和循环引用。
如果仅将Kryo用于复制,则可以安全地禁用注册。
复制对象图以获得旧对象到新对象的映射后,可以使用Kryo的getOriginalToCopyMap。 Kryoreset自动清除该映射,因此仅在KryosetAutoReset为false时才有用。
References
默认情况下,不启用引用。 这意味着,如果一个对象多次出现在对象图中,它将被多次写入并将被反序列化为多个不同的对象。 禁用引用时,循环引用将导致序列化失败。 使用Kryo的setReferences进行序列化和使用setCopyReferences进行复制来启用或禁用引用。
启用引用后,将在第一次在对象图中出现varint时将其写入对象。 对于该类在同一对象图中的后续出现,仅写入varint。 反序列化后,将还原对象引用,包括任何循环引用。 使用中的序列化程序必须通过在序列化程序read中调用Kryoreference来支持引用。
启用引用会影响性能,因为需要跟踪每个读取或写入的对象。
ReferenceResolver
在幕后,ReferenceResolver处理已读取或写入的跟踪对象,并提供int引用ID。提供了多种实现:
-
如果未指定参考解析器,则默认使用MapReferenceResolver。它使用Kryo的IdentityObjectIntMap(一个cuckoo hashmap)来跟踪写入的对象。这种映射具有非常快的获取速度,并且不分配用于放置,但是用于大量对象的放置会有些慢。
-
HashMapReferenceResolver使用HashMap跟踪写入的对象。这种类型的映射分配给放置,但可能为具有大量对象的对象图提供更好的性能。
-
ListReferenceResolver使用ArrayList跟踪写入的对象。对于对象数量相对较少的对象图,这可能比使用地图要快(在某些测试中要快15%)。不应将其用于具有许多对象的图形,因为它具有线性查找功能来查找已写入的对象。
ReferenceResolver的useReferences(Class)可以被覆盖。 它返回一个布尔值,以确定类是否支持引用。 如果一个类不支持引用,则varint引用ID不会写在该类型的对象之前。 如果一个类不需要引用,并且该类型的对象多次出现在对象图中,则可以通过禁用该类的引用来大大减小序列化的大小。 对于所有原始包装和枚举,默认的引用解析器返回false。 通常,对于String和其他类,还返回false,这取决于要序列化的对象图。
public boolean useReferences (Class type) {
return !Util.isWrapperClass(type) && !Util.isEnum(type) && type != String.class;
}
Reference limits
引用解析器确定单个对象图中的最大引用数量。 Java数组索引仅限于Integer.MAX_VALUE,因此在序列化超过20亿个对象时,使用基于数组的数据结构的引用解析器可能会导致java.lang.NegativeArraySizeException。 Kryo使用int类ID,因此单个对象图中的最大引用数限制为int的正数和负数的全部范围(约40亿个)。
Context
KryogetContext返回用于存储用户数据的映射。 Kryo实例可用于所有序列化程序,因此所有序列化程序都可以轻松访问此数据。
Kryo的“ getGraphContext”类似,但是在每个对象图被序列化或反序列化后将被清除。 这使得管理仅与当前对象图相关的状态变得容易。 例如,这可用于在对象图中第一次遇到类时写入一些模式数据。 有关示例,请参见CompatibleFieldSerializer。
Reset
默认情况下,在序列化每个对象图之后,会调用Kryoreset。 这将重置类解析器中的未注册类名,对引用解析器中先前序列化或反序列化的对象的引用,并清除图形上下文。 KryosetAutoReset(false)可用于禁用自动调用reset,从而允许该状态跨越多个对象图。
Serializer framework
Kryo是促进序列化的框架。 框架本身并不执行架构,也不关心数据的写入或读取方式。 序列化器是可插入的,并决定读写内容。 开箱即用提供了许多串行器,以各种方式读取和写入数据。 虽然提供的序列化程序可以读取和写入大多数对象,但可以轻松地用您自己的序列化程序部分或完全替换它们。
Registration
当Kryo编写对象的实例时,首先可能需要编写一些可以标识该对象的类的东西。 默认情况下,必须预先注册Kryo将读取或写入的所有类。 注册提供一个int类ID,用于该类的序列化程序以及用于创建该类实例的对象实例化器。
Kryo kryo = new Kryo();
kryo.register(SomeClass.class);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);
在反序列化期间,注册的类必须具有与序列化期间完全相同的ID。 注册后,将为类别分配下一个可用的最低整数ID,这意味着注册订单类别非常重要。 可以选择明确指定类ID,以使顺序不重要:
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, 9);
kryo.register(AnotherClass.class, 10);
kryo.register(YetAnotherClass.class, 11);
类别ID -1和-2保留。 默认情况下,类ID 0-8用于原始类型和String,尽管这些ID可重新使用。 ID被写为正优化的varint,因此当它们是小的正整数时,效率最高。 负ID无法有效地序列化。
ClassResolver
在幕后,ClassResolver实际处理读写字节来表示一个类。 在大多数情况下,默认实现就足够了,但是可以替换它,以自定义注册类时发生的情况,序列化过程中遇到的未注册类以及代表类的读写内容。
Optional registration
可以将Kryo配置为允许序列化而无需预先注册类。
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);
可以混合使用已注册和未注册的类。 未注册的类有两个主要缺点:
- 存在安全隐患,因为它允许反序列化创建任何类的实例。 在构造或完成期间具有副作用的类可用于恶意目的。
- 完全写类名而不是写varint类ID(通常为1-2个字节),而是在对象图中首次出现未注册的类时写入完全限定的类名。 该类在同一对象图中的后续外观是使用varint编写的。 可以考虑使用简短的程序包名称来减小序列化的大小。
如果仅将Kryo用于复制,则可以安全地禁用注册。
当不需要注册时,当遇到未注册的类时,可以启用KryosetWarnUnregisteredClasses来记录消息。 这可以用来轻松获取所有未注册类的列表。 可以重写KryounregisteredClassMessage来自定义日志消息或采取其他措施。
Default serializers
注册类时,可以选择指定序列化程序实例。 反序列化期间,注册的类必须具有与序列化期间完全相同的序列化程序和序列化程序配置。
Kryo kryo = new Kryo();
kryo.register(SomeClass.class, new SomeSerializer());
kryo.register(AnotherClass.class, new AnotherSerializer());
如果未指定序列化程序,或者遇到未注册的类,则会从“默认序列化程序”列表中自动选择一个序列化程序,该列表将类映射到序列化程序。 有许多默认的序列化程序不会影响序列化性能,因此默认情况下,Kryo具有[50+个默认的序列化程序](https://github.com/EsotericSoftware/kryo/blob/master/src/com/esotericsoftware/kryo/Kryo.java #L179)适用于各种JRE类。 可以添加其他默认序列化器:
Kryo kryo = new Kryo();
kryo.setRegistrationRequired(false);
kryo.addDefaultSerializer(SomeClass.class, SomeSerializer.class);
Output output = ...
SomeClass object = ...
kryo.writeObject(output, object);
注册SomeClass或扩展或实现SomeClass的任何类时,这将导致创建SomeSerializer实例。
默认的序列化程序已排序,因此首先匹配更具体的类,但否则按照添加顺序进行匹配。 它们的添加顺序可能与接口有关。
如果没有默认的序列化程序与某个类匹配,则使用全局默认的序列化程序。 全局默认序列化程序默认设置为FieldSerializer,但可以更改。 通常,全局序列化程序是可以处理许多不同类型的序列化程序。
Kryo kryo = new Kryo();
kryo.setDefaultSerializer(TaggedFieldSerializer.class);
kryo.register(SomeClass.class);
使用此代码,假设没有默认的序列化程序与SomeClass匹配,则将使用TaggedFieldSerializer。
一个类也可以使用DefaultSerializer批注,该批注将用于代替选择Kryo的默认序列化程序之一:
@DefaultSerializer(SomeClassSerializer.class)
public class SomeClass {
// ...
}
为了获得最大的灵活性,可以覆盖Kryo的getDefaultSerializer以实现用于选择和实例化序列化程序的自定义逻辑。
Serializer factories
addDefaultSerializer(Class,Class)方法不允许配置序列化程序。 可以设置序列化程序工厂而不是序列化程序类,从而允许工厂创建和配置每个序列化程序实例。 为常见的序列化器提供了工厂,通常使用getConfig方法来配置所创建的序列化器。
Kryo kryo = new Kryo();
TaggedFieldSerializerFactory defaultFactory = new TaggedFieldSerializerFactory();
defaultFactory.getConfig().setReadUnknownTagData(true);
kryo.setDefaultSerializer(defaultFactory);
FieldSerializerFactory someClassFactory = new FieldSerializerFactory();
someClassFactory.getConfig().setFieldsCanBeNull(false);
kryo.register(SomeClass.class, someClassFactory);
序列化程序工厂有一个issupported(Class)方法,即使它与该类匹配,它也可以拒绝处理一个类。 这允许工厂检查多个接口或实现其他逻辑。
Object creation
虽然某些序列化程序用于特定类,但其他序列化器可以序列化许多不同的类。 序列化器可以使用KryonewInstance(Class)创建任何类的实例。 通过查找该类的注册,然后使用注册的ObjectInstantiator来完成此操作。 实例化程序可以在注册中指定。
Registration registration = kryo.register(SomeClass.class);
registration.setInstantiator(new ObjectInstantiator<SomeClass>() {
public SomeClass newInstance () {
return new SomeClass("some constructor arguments", 1234);
}
});
如果注册没有实例化器,则由KryonewInstantiator提供。 为了自定义对象的创建方式,可以重写KryonewInstantiator或提供InstantiatorStrategy。
InstantiatorStrategy
Kryo提供了DefaultInstantiatorStrategy,它使用ReflectASM创建对象以调用零参数构造函数。如果不可能,则使用反射来调用零参数构造函数。如果这也失败了,那么它要么抛出异常,要么尝试回退InstantiatorStrategy。反射使用“ setAccessible”,因此私有零参数构造函数是允许Kryo创建类实例而不影响公共API的好方法。
建议使用DefaultInstantiatorStrategy使用Kryo创建对象。它就像使用Java代码一样运行构造函数。也可以使用其他语言外机制来创建对象。 ObjenesisStdInstantiatorStrategy使用JVM特定的API创建类的实例,而根本不调用任何构造函数。使用此方法很危险,因为大多数类都希望它们的构造函数被调用。通过绕过其构造函数创建对象可能会使该对象处于未初始化或无效状态。必须将类设计为以这种方式创建。
可以将Kryo配置为首先尝试DefaultInstantiatorStrategy,然后在必要时回退到StdInstantiatorStrategy。
kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new StdInstantiatorStrategy()));
另一个选项是SerializingInstantiatorStrategy,它使用Java的内置序列化机制来创建实例。 使用此方法,该类必须实现java.io.Serializable,并调用超类中的第一个零参数构造函数。 这也绕过了构造函数,因此出于与StdInstantiatorStrategy相同的原因是危险的。
kryo.setInstantiatorStrategy(new DefaultInstantiatorStrategy(new SerializingInstantiatorStrategy()));
Overriding create
另外,一些通用的序列化器提供了可以重写的方法,以自定义特定类型的对象,而不是调用KryonewInstance。
kryo.register(SomeClass.class, new FieldSerializer(kryo, SomeClass.class) {
protected T create (Kryo kryo, Input input, Class<? extends T> type) {
return new SomeClass("some constructor arguments", 1234);
}
});
一些序列化器提供了一个writeHeader方法,该方法可以被覆盖以在适当的时候写入create所需的数据。
static public class TreeMapSerializer extends MapSerializer<TreeMap> {
protected void writeHeader (Kryo kryo, Output output, TreeMap map) {
kryo.writeClassAndObject(output, map.comparator());
}
protected TreeMap create (Kryo kryo, Input input, Class<? extends TreeMap> type, int size) {
return new TreeMap((Comparator)kryo.readClassAndObject(input));
}
}
如果序列化器没有提供“ writeHeader”,则可以在“ write”中为“ create”写入数据。
static public class SomeClassSerializer extends FieldSerializer<SomeClass> {
public SomeClassSerializer (Kryo kryo) {
super(kryo, SomeClass.class);
}
public void write (Kryo kryo, Output output, SomeClass object) {
output.writeInt(object.value);
}
protected SomeClass create (Kryo kryo, Input input, Class<? extends SomeClass> type) {
return new SomeClass(input.readInt());
}
}
Final classes
即使序列化程序知道某个值的预期类(例如,字段的类),如果该值的具体类不是final修饰,则序列化程序也需要先写入类ID,然后再写入该值。 由于final类是非多态的,因此它们可以更有效地序列化。
KryoisFinal用于确定某个类是否为final。 即使不是fianl类型,也可以重写此方法以返回true。 例如,如果应用程序广泛使用ArrayList,但从不使用ArrayList子类,则将ArrayList视为final可以允许FieldSerializer为每个ArrayList字段节省1-2个字节。
Closures
Kryo可以序列化实现java.io.Serializable的Java 8+闭包,但有一些警告。 在一个JVM上序列化的闭包可能无法在另一个JVM上反序列化。
KryoisClosure用于确定类是否为闭包。 如果是这样,则使用ClosureSerializer.Closure而不是闭包的类来查找类注册。 要序列化闭包,必须注册以下类:ClosureSerializer.Closure,SerializedLambda,Object []和Class。 此外,必须注册闭包的捕获类。
kryo.register(Object[].class);
kryo.register(Class.class);
kryo.register(SerializedLambda.class);
kryo.register(ClosureSerializer.Closure.class, new ClosureSerializer());
kryo.register(CapturingClass.class);
Callable<Integer> closure1 = (Callable<Integer> & java.io.Serializable)( () -> 72363 );
Output output = new Output(1024, -1);
kryo.writeObject(output, closure1);
Input input = new Input(output.getBuffer(), 0, output.position());
Callable<Integer> closure2 = (Callable<Integer>)kryo.readObject(input, ClosureSerializer.Closure.class);
可以不费吹灰之力将不实现Serializable的闭包进行序列化。
Compression and encryption
Kryo支持流,因此对所有序列化字节使用压缩或加密很简单:
OutputStream outputStream = new DeflaterOutputStream(new FileOutputStream("file.bin"));
Output output = new Output(outputStream);
Kryo kryo = new Kryo();
kryo.writeObject(output, object);
output.close();
如果需要,可以使用序列化器来压缩或加密对象图的仅一部分字节的字节。 例如,请参阅DeflateSerializer或BlowfishSerializer。 这些串行器包装另一个串行器以对字节进行编码和解码。
Implementing a serializer
Serializer抽象类定义了从对象到字节以及从字节到对象的方法。
public class ColorSerializer extends Serializer<Color> {
public void write (Kryo kryo, Output output, Color color) {
output.writeInt(color.getRGB());
}
public Color read (Kryo kryo, Input input, Class<? extends Color> type) {
return new Color(input.readInt());
}
}
序列化器只有两种必须实现的方法。 write将对象作为字节写入输出。 read创建对象的新实例,并从Input中读取以填充它。
Serializer references
当使用Kryo在Serializerread中读取嵌套对象时,如果嵌套对象有可能引用父对象,则必须先与父对象一起调用Kryoreference。 如果嵌套对象不可能引用父对象,或者嵌套对象没有使用Kryo,或者引用没有使用,则不必调用Kryo引用。 如果嵌套对象可以使用相同的序列化器,则序列化器必须是可重入的。
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
SomeClass object = new SomeClass();
kryo.reference(object);
// Read objects that may reference the SomeClass instance.
object.someField = kryo.readClassAndObject(input);
return object;
}
Nested serializers
序列化器通常不应直接使用其他序列化器,而应使用Kryo读写方法。 这使Kryo能够编排序列化并处理诸如引用和空对象之类的功能。 有时,序列化程序知道用于嵌套对象的序列化程序。 在这种情况下,它应该使用Kryo的读取和写入方法来接受序列化程序。
如果对象允许为null:
Serializer serializer = ...
kryo.writeObjectOrNull(output, object, serializer);
SomeClass object = kryo.readObjectOrNull(input, SomeClass.class, serializer);
如果对象不允许为null:
Serializer serializer = ...
kryo.writeObject(output, object, serializer);
SomeClass object = kryo.readObject(input, SomeClass.class, serializer);
序列化期间,Kryo的getDepth提供对象序列的当前深度。
KryoException
当序列化失败时,可以引发KryoException并附带有关对象图中异常发生位置的序列化跟踪信息。 使用嵌套的序列化程序时,可以捕获KryoException以添加序列化跟踪信息。
Object object = ...
Field[] fields = ...
for (Field field : fields) {
try {
// Use other serializers to serialize each field.
} catch (KryoException ex) {
ex.addTrace(field.getName() + " (" + object.getClass().getName() + ")");
throw ex;
} catch (Throwable t) {
KryoException ex = new KryoException(t);
ex.addTrace(field.getName() + " (" + object.getClass().getName() + ")");
throw ex;
}
}
Stack size
序列化程序Kryo提供了在序列化嵌套对象时使用调用堆栈的方法。 Kryo最大限度地减少了堆栈调用,但是对于极深的对象图,可能会发生堆栈溢出。 对于大多数序列化库(包括内置Java序列化),这是一个常见问题。 可以使用-Xss来增加堆栈大小,但是请注意,这适用于所有线程。 具有多个线程的JVM中的大型堆栈可能会占用大量内存。
KryosetMaxDepth可用于限制对象图的最大深度。 这样可以防止恶意数据导致堆栈溢出。
Accepting null
默认情况下,序列化程序永远不会收到null,而是Kryo将根据需要写入一个字节来表示null或不为null。 如果序列化程序本身可以通过处理null来提高效率,则可以调用SerializersetAcceptsNull(true)。 当已知串行器将处理的所有实例永远不会为空时,这也可以用于避免写入表示空值的字节。
Generics
KryogetGenerics提供了通用类型信息,因此序列化程序可以更高效。 最通常用于避免在类型参数类为final时编写该类。
如果该类具有单个类型参数,则nextGenericClass返回该类型参数类;如果没有,则返回null。 在读取或写入任何嵌套对象后,必须调用popGenericType。 有关示例,请参见CollectionSerializer。
public class SomeClass<T> {
public T value;
}
public class SomeClassSerializer extends Serializer<SomeClass> {
public void write (Kryo kryo, Output output, SomeClass object) {
Class valueClass = kryo.getGenerics().nextGenericClass();
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
kryo.writeObjectOrNull(output, object.value, serializer);
} else
kryo.writeClassAndObject(output, object.value);
kryo.getGenerics().popGenericType();
}
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
Class valueClass = kryo.getGenerics().nextGenericClass();
SomeClass object = new SomeClass();
kryo.reference(object);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
object.value = kryo.readObjectOrNull(input, valueClass, serializer);
} else
object.value = kryo.readClassAndObject(input);
kryo.getGenerics().popGenericType();
return object;
}
}
对于具有多个类型参数的类,nextGenericTypes返回GenericType实例的数组,而resolve用于获取每个GenericType的类。 在读取或写入任何嵌套对象后,必须调用popGenericType。 有关示例,请参见MapSerializer。
public class SomeClass<K, V> {
public K key;
public V value;
}
public class SomeClassSerializer extends Serializer<SomeClass> {
public void write (Kryo kryo, Output output, SomeClass object) {
Class keyClass = null, valueClass = null;
GenericType[] genericTypes = kryo.getGenerics().nextGenericTypes();
if (genericTypes != null) {
keyClass = genericTypes[0].resolve(kryo.getGenerics());
valueClass = genericTypes[1].resolve(kryo.getGenerics());
}
if (keyClass != null && kryo.isFinal(keyClass)) {
Serializer serializer = kryo.getSerializer(keyClass);
kryo.writeObjectOrNull(output, object.key, serializer);
} else
kryo.writeClassAndObject(output, object.key);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
kryo.writeObjectOrNull(output, object.value, serializer);
} else
kryo.writeClassAndObject(output, object.value);
kryo.getGenerics().popGenericType();
}
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
Class keyClass = null, valueClass = null;
GenericType[] genericTypes = kryo.getGenerics().nextGenericTypes();
if (genericTypes != null) {
keyClass = genericTypes[0].resolve(kryo.getGenerics());
valueClass = genericTypes[1].resolve(kryo.getGenerics());
}
SomeClass object = new SomeClass();
kryo.reference(object);
if (keyClass != null && kryo.isFinal(keyClass)) {
Serializer serializer = kryo.getSerializer(keyClass);
object.key = kryo.readObjectOrNull(input, keyClass, serializer);
} else
object.key = kryo.readClassAndObject(input);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
object.value = kryo.readObjectOrNull(input, valueClass, serializer);
} else
object.value = kryo.readClassAndObject(input);
kryo.getGenerics().popGenericType();
return object;
}
}
对于在对象图中传递嵌套对象的类型参数信息的串行器(某种高级用法),首先使用GenericsHierarchy存储类的类型参数。 在序列化期间,在解析泛型类型(如果有)之前,将调用泛型pushTypeVariables。 如果返回> 0,则必须紧随其后的是泛型popTypeVariables。 有关示例,请参见FieldSerializer。
public class SomeClass<T> {
T value;
List<T> list;
}
public class SomeClassSerializer extends Serializer<SomeClass> {
private final GenericsHierarchy genericsHierarchy;
public SomeClassSerializer () {
genericsHierarchy = new GenericsHierarchy(SomeClass.class);
}
public void write (Kryo kryo, Output output, SomeClass object) {
Class valueClass = null;
Generics generics = kryo.getGenerics();
int pop = 0;
GenericType[] genericTypes = generics.nextGenericTypes();
if (genericTypes != null) {
pop = generics.pushTypeVariables(genericsHierarchy, genericTypes);
valueClass = genericTypes[0].resolve(generics);
}
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
kryo.writeObjectOrNull(output, object.value, serializer);
} else
kryo.writeClassAndObject(output, object.value);
kryo.writeClassAndObject(output, object.list);
if (pop > 0) generics.popTypeVariables(pop);
generics.popGenericType();
}
public SomeClass read (Kryo kryo, Input input, Class<? extends SomeClass> type) {
Class valueClass = null;
Generics generics = kryo.getGenerics();
int pop = 0;
GenericType[] genericTypes = generics.nextGenericTypes();
if (genericTypes != null) {
pop = generics.pushTypeVariables(genericsHierarchy, genericTypes);
valueClass = genericTypes[0].resolve(generics);
}
SomeClass object = new SomeClass();
kryo.reference(object);
if (valueClass != null && kryo.isFinal(valueClass)) {
Serializer serializer = kryo.getSerializer(valueClass);
object.value = kryo.readObjectOrNull(input, valueClass, serializer);
} else
object.value = kryo.readClassAndObject(input);
object.list = (List)kryo.readClassAndObject(input);
if (pop > 0) generics.popTypeVariables(pop);
generics.popGenericType();
return object;
}
}
KryoSerializable
除了使用序列化程序,类还可以选择通过实现KryoSerializable(类似于java.io.Externalizable)来进行自己的序列化。
public class SomeClass implements KryoSerializable {
private int value;
public void write (Kryo kryo, Output output) {
output.writeInt(value, false);
}
public void read (Kryo kryo, Input input) {
value = input.readInt(false);
}
}
显然,在调用read之前必须已经创建了实例,因此该类无法控制自己的创建。 一个KryoSerializable类将使用默认的序列化程序KryoSerializableSerializer,该序列化程序使用KryonewInstance创建一个新实例。 编写自己的序列化程序以自定义过程,在序列化之前或之后调用方法等都是很简单的。
Serializer copying
序列化程序仅在“副本”被覆盖时才支持复制。 与Serializerread类似,此方法包含创建和配置副本的逻辑。 就像read一样,如果任何子对象可以引用父对象,则在使用Kryo复制子对象之前必须调用Kryoreference。
class SomeClassSerializer extends Serializer<SomeClass> {
public SomeClass copy (Kryo kryo, SomeClass original) {
SomeClass copy = new SomeClass();
kryo.reference(copy);
copy.intValue = original.intValue;
copy.object = kryo.copy(original.object);
return copy;
}
}
KryoCopyable
类可以不使用序列化程序,而可以实现KryoCopyable进行自己的复制:
public class SomeClass implements KryoCopyable<SomeClass> {
public SomeClass copy (Kryo kryo) {
SomeClass copy = new SomeClass();
kryo.reference(copy);
copy.intValue = intValue;
copy.object = kryo.copy(object);
return copy;
}
}
Immutable serializers
当类型是不可变的时,可以使用序列化器“ setImmutable(true)”方法。 在那种情况下,不需要实现Serializer的“ copy”,默认的“ copy”实现将返回原始对象。
Kryo versioning and upgrading
以下经验法则适用于Kryo的版本编号:
-
如果序列化兼容性被破坏,则会增加主要版本。 这意味着使用先前版本序列化的数据可能不会使用新版本反序列化。
-
如果记录的公共API的二进制或源兼容性被破坏,则次要版本会增加。 为了避免在影响很少用户的情况下增加版本,如果在很少使用或不打算用于一般用途的公共类中发生较小的损坏,则允许一些较小的损坏。
升级任何依赖项都是很重要的事情,但是与大多数依赖项相比,序列化库更容易损坏。 升级Kryo时,请检查版本差异并在您自己的应用程序中彻底测试新版本。 我们试图使其尽可能安全和容易。
- 在开发时,已针对不同的二进制格式和默认序列化程序测试了序列化兼容性。
- 在开发时,使用clirr跟踪二进制文件和源代码的兼容性。
- 对于每个发行版,都提供changelog,其中还包含报告序列化,二进制文件和源兼容性的部分。
- 为了报告二进制和源代码兼容性,使用了japi-compliance-checker。
Interoperability
默认情况下提供的Kryo序列化程序假定Java将用于反序列化,因此它们未明确定义所编写的格式。 可以使用其他语言更容易读取的标准化格式编写序列化程序,但是默认情况下未提供。
Compatibility
对于某些需求,例如长期存储序列化字节,序列化如何处理对类的更改可能很重要。 这被称为前向兼容性(读取由较新类序列化的字节)和向后兼容性(读取由较旧类序列化的字节)。 Kryo提供了一些通用的串行器,它们采用不同的方法来处理兼容性。 可以轻松开发其他串行器以实现向前和向后的兼容性,例如使用外部手写模式的串行器。
Serializers
Kryo为许多串行器提供了各种配置选项和兼容性级别。 其他序列化器可以在kryo-serializers姊妹项目中找到,该项目承载可访问私有API或在所有JVM上都不完全安全的序列化器。 可以在链接部分中找到更多的序列化器。
FieldSerializer
FieldSerializer通过序列化每个非瞬态字段来工作。 它无需任何配置即可序列化POJO和许多其他类。 默认情况下,所有非公共字段都是读写的,因此评估要序列化的每个类很重要。 如果字段是公共的,则序列化可能会更快。
使用Java类文件作为模式,通过仅写入字段数据而没有任何模式信息,FieldSerializer效率很高。 它不支持在不使先前序列化的字节无效的情况下添加,删除或更改字段的类型。 仅在不更改字段的字母顺序的情况下才允许重命名字段。
在许多情况下,例如通过网络发送数据时,FieldSerializer的兼容性缺点是可以接受的,但是对于长期数据存储而言,它可能不是一个好的选择,因为Java类无法进化。
FieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
fieldsCanBeNull |
如果为false,则假定没有字段值为null,这样每个字段可以节省0-1个字节。 | true |
setFieldsAsAccessible |
如果为true,则将对所有非临时字段(包括私有字段)进行序列化,并setAccessible在必要时进行序列化。如果为false,则只会序列化公共API中的字段。 |
true |
ignoreSyntheticFields |
如果为true,则对合成字段(由编译器生成以进行作用域)进行序列化。 | false |
fixedFieldTypes |
如果为true,则假定每个字段值的具体类型都与该字段的类型匹配。这样就无需为字段值编写类ID。 | false |
copyTransient |
如果为true,将复制所有瞬态字段。 | true |
serializeTransient |
如果为true,则将对瞬态字段进行序列化。 | false |
variableLengthEncoding |
如果为true,则将可变长度值用于int和long字段。 | true |
extendedFieldNames |
如果为true,则字段名称以其声明类为前缀。当子类具有与父类同名的字段时,可以避免冲突。 | false |
CachedField settings
FieldSerializer提供将被序列化的字段。字段可以删除,因此不会被序列化。可以配置字段以提高序列化效率。
FieldSerializer fieldSerializer = ...
fieldSerializer.removeField("id"); // Won't be serialized.
CachedField nameField = fieldSerializer.getField("name");
nameField.setCanBeNull(false);
CachedField someClassField = fieldSerializer.getField("someClass");
someClassField.setClass(SomeClass.class, new SomeClassSerializer());
| Setting | Description | Default value |
|---|---|---|
canBeNull |
如果为false,则假定字段值永远不会为null,这可以节省0-1个字节。 | true |
valueClass |
设置要用于字段值的具体类和序列化程序。这样就无需为该值编写类ID。如果字段值的类是原始,原始包装或最终的,则此设置默认为字段的类。 | null |
serializer |
设置要用于字段值的序列化程序。如果设置了序列化程序,则某些序列化程序还需要设置值类别。如果为null,将使用在Kryo中注册的用于字段值类的序列化程序。 | null |
variableLengthEncoding |
如果为true,则使用可变长度值。这仅适用于int或long字段。 | true |
optimizePositive |
如果为true,则为可变长度值优化正值。当使用可变长度编码时,这仅适用于int或long字段。 | true |
FieldSerializer annotations
注释可用于为每个字段配置序列化器。
| Annotation | Description |
|---|---|
@Bind |
Sets the CachedField settings for any field. |
@CollectionBind |
Sets the CollectionSerializer settings for Collection fields. |
@MapBind |
Sets the MapSerializer settings for Map fields. |
@NotNull |
Marks a field as never being null. |
public class SomeClass {
@NotNull
@Bind(serializer = StringSerializer.class, valueClass = String.class, canBeNull = false)
Object stringField;
@Bind(variableLengthEncoding = false)
int intField;
@BindMap(
keySerializer = StringSerializer.class,
valueSerializer = IntArraySerializer.class,
keyClass = String.class,
valueClass = int[].class,
keysCanBeNull = false)
Map map;
@BindCollection(
elementSerializer = LongArraySerializer.class,
elementClass = long[].class,
elementsCanBeNull = false)
Collection collection;
}
VersionFieldSerializer
VersionFieldSerializer extends FieldSerializer and provides backward compatibility. This means fields can be added without invalidating previously serialized bytes. Removing, renaming, or changing the type of a field is not supported.
When a field is added, it must have the @Since(int) annotation to indicate the version it was added in order to be compatible with previously serialized bytes. The annotation value must never change.
VersionFieldSerializer adds very little overhead to FieldSerializer: a single additional varint.
VersionFieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
compatible |
When false, an exception is thrown when reading an object with a different version. The version of an object is the maximum version of any field. | true |
VersionFieldSerializer also inherits all the settings of FieldSerializer.
TaggedFieldSerializer
TaggedFieldSerializer extends FieldSerializer to provide backward compatibility and optional forward compatibility. This means fields can be added or renamed and optionally removed without invalidating previously serialized bytes. Changing the type of a field is not supported.
Only fields that have a @Tag(int) annotation are serialized. Field tag values must be unique, both within a class and all its super classes. An exception is thrown if duplicate tag values are encountered.
The forward and backward compatibility and serialization performance depends on the readUnknownTagData and chunkedEncoding settings. Additionally, a varint is written before each field for the tag value.
When readUnknownTagData and chunkedEncoding are false, fields must not be removed but the @Deprecated annotation can be applied. Deprecated fields are read when reading old bytes but aren’t written to new bytes. Classes can evolve by reading the values of deprecated fields and writing them elsewhere. Fields can be renamed and/or made private to reduce clutter in the class (eg, ignored1, ignored2).
TaggedFieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
readUnknownTagData |
When false and an unknown tag is encountered, an exception is thrown or, if chunkedEncoding is true, the data is skipped.When true, the class for each field value is written before the value. When an unknown tag is encountered, an attempt to read the data is made. This is used to skip the data and, if references are enabled, any other values in the object graph referencing that data can still be deserialized. If reading the data fails (eg the class is unknown or has been removed) then an exception is thrown or, if chunkedEncoding is true, the data is skipped.In either case, if the data is skipped and references are enabled, then any references in the skipped data are not read and further deserialization may receive the wrong references and fail. |
|
chunkedEncoding |
When true, fields are written with chunked encoding to allow unknown field data to be skipped. This impacts performance. | false |
chunkSize |
The maximum size of each chunk for chunked encoding. | 1024 |
TaggedFieldSerializer also inherits all the settings of FieldSerializer.
CompatibleFieldSerializer
CompatibleFieldSerializer extends FieldSerializer to provided both forward and backward compatibility. This means fields can be added or removed without invalidating previously serialized bytes. Renaming or changing the type of a field is not supported. Like FieldSerializer, it can serialize most classes without needing annotations.
The forward and backward compatibility and serialization performance depends on the readUnknownFieldData and chunkedEncoding settings. Additionally, the first time the class is encountered in the serialized bytes, a simple schema is written containing the field name strings. Because field data is identified by name, if a super class has a field with the same name as a subclass, extendedFieldNames must be true.
CompatibleFieldSerializer settings
| Setting | Description | Default value |
|---|---|---|
readUnknownFieldData |
When false and an unknown field is encountered, an exception is thrown or, if chunkedEncoding is true, the data is skipped.When true, the class for each field value is written before the value. When an unknown field is encountered, an attempt to read the data is made. This is used to skip the data and, if references are enabled, any other values in the object graph referencing that data can still be deserialized. If reading the data fails (eg the class is unknown or has been removed) then an exception is thrown or, if chunkedEncoding is true, the data is skipped.In either case, if the data is skipped and references are enabled, then any references in the skipped data are not read and further deserialization may receive the wrong references and fail. |
|
chunkedEncoding |
When true, fields are written with chunked encoding to allow unknown field data to be skipped. This impacts performance. | false |
chunkSize |
The maximum size of each chunk for chunked encoding. | 1024 |
CompatibleFieldSerializer also inherits all the settings of FieldSerializer.
BeanSerializer
BeanSerializer is very similar to FieldSerializer, except it uses bean getter and setter methods rather than direct field access. This slightly slower, but may be safer because it uses the public API to configure the object. Like FieldSerializer, it provides no forward or backward compatibility.
CollectionSerializer
CollectionSerializer serializes objects that implement the java.util.Collection interface.
CollectionSerializer settings
| Setting | Description | Default value |
|---|---|---|
elementsCanBeNull |
When false it is assumed that no elements in the collection are null, which can save 0-1 byte per element. | true |
elementClass |
Sets the concrete class to use for each element in the collection. This removes the need to write the class ID for each element. If the element class is known (eg through generics) and a primitive, primitive wrapper, or final, then CollectionSerializer won’t write the class ID even when this setting is null. | null |
elementSerializer |
Sets the serializer to use for every element in the collection. If the serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for each element’s class will be used. | null |
MapSerializer
MapSerializer serializes objects that implement the java.util.Map interface.
MapSerializer settings
| Setting | Description | Default value |
|---|---|---|
keysCanBeNull |
When false it is assumed that no keys in the map are null, which can save 0-1 byte per entry. | true |
valuesCanBeNull |
When false it is assumed that no values in the map are null, which can save 0-1 byte per entry. | true |
keyClass |
Sets the concrete class to use for every key in the map. This removes the need to write the class ID for each key. | null |
valueClass |
Sets the concrete class to use for every value in the map. This removes the need to write the class ID for each value. | null |
keySerializer |
Sets the serializer to use for every key in the map. If the value serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for each key’s class will be used. | null |
valueSerializer |
Sets the serializer to use for every value in the map. If the key serializer is set, some serializers required the value class to also be set. If null, the serializer registered with Kryo for each value’s class will be used. | null |
JavaSerializer and ExternalizableSerializer
JavaSerializer and ExternalizableSerializer are Kryo serializers which uses Java’s built-in serialization. This is as slow as usual Java serialization, but may be necessary for legacy classes.
java.io.Externalizable and java.io.Serializable do not have default serializers set by default, so the default serializers must be set manually or the serializers set when the class is registered.
class SomeClass implements Externalizable { /* ... */ }
kryo.addDefaultSerializer(Externalizable.class, ExternalizableSerializer.class);
kryo.register(SomeClass.class);
kryo.register(SomeClass.class, new JavaSerializer());
kryo.register(SomeClass.class, new ExternalizableSerializer());
Logging
Kryo makes use of the low overhead, lightweight MinLog logging library. The logging level can be set by one of the following methods:
Log.ERROR();
Log.WARN();
Log.INFO();
Log.DEBUG();
Log.TRACE();
Kryo does no logging at INFO (the default) and above levels. DEBUG is convenient to use during development. TRACE is good to use when debugging a specific problem, but generally outputs too much information to leave on.
MinLog supports a fixed logging level, which causes the Java compiler to remove logging statements below that level at compile time. Kryo must be compiled with a fixed logging level MinLog JAR.
Thread safety
Kryo is not thread safe. Each thread should have its own Kryo, Input, and Output instances.
Pooling
Because Kryo is not thread safe and constructing and configuring a Kryo instance is relatively expensive, in a multithreaded environment ThreadLocal or pooling might be considered.
static private final ThreadLocal<Kryo> kryos = new ThreadLocal<Kryo>() {
protected Kryo initialValue() {
Kryo kryo = new Kryo();
// Configure the Kryo instance.
return kryo;
};
};
Kryo kryo = kryos.get();
For pooling, Kryo provides the Pool class which can pool Kryo, Input, Output, or instances of any other class.
// Pool constructor arguments: thread safe, soft references, maximum capacity
Pool<Kryo> kryoPool = new Pool<Kryo>(true, false, 8) {
protected Kryo create () {
Kryo kryo = new Kryo();
// Configure the Kryo instance.
return kryo;
}
};
Kryo kryo = kryoPool.obtain();
// Use the Kryo instance here.
kryoPool.free(kryo);
Pool<Output> outputPool = new Pool<Output>(true, false, 16) {
protected Output create () {
return new Output(1024, -1);
}
};
Output output = outputPool.obtain();
// Use the Output instance here.
outputPool.free(output);
Pool<Input> inputPool = new Pool<Input>(true, false, 16) {
protected Input create () {
return new Input(1024, -1);
}
};
Input input = inputPool.obtain();
// Use the Input instance here.
inputPool.free(input);
If true is passed as the first argument to the Pool constructor, the Pool uses synchronization internally and can be accessed by multiple threads concurrently.
If true is passed as the second argument to the Pool constructor, the Pool stores objects using java.lang.ref.SoftReference. This allows objects in the pool to be garbage collected when memory pressure on the JVM is high. Pool clean removes all soft references whose object has been garbage collected. This can reduce the size of the pool when no maximum capacity has been set. When the pool has a maximum capacity, it is not necessary to call clean because Pool free will try to remove an empty reference if the maximum capacity has been reached.
The third Pool parameter is the maximum capacity. If an object is freed and the pool already contains the maximum number of free objects, the specified object is reset but not added to the pool. The maximum capacity may be omitted for no limit.
If an object implements Pool.Poolable then Poolable reset is called when the object is freed. This gives the object a chance to reset its state for reuse in the future. Alternatively, Pool reset can be overridden to reset objects. Input and Output implement Poolable to set their position and total to 0. Kryo implements Poolable to reset its object graph state.
Pool getFree returns the number of objects available to be obtained. If using soft references, this number may include objects that have been garbage collected. clean may be used first to remove empty soft references.
Pool getPeak returns the all-time highest number of free objects. This can help determine if a pool’s maximum capacity is set appropriately. It can be reset any time with resetPeak.
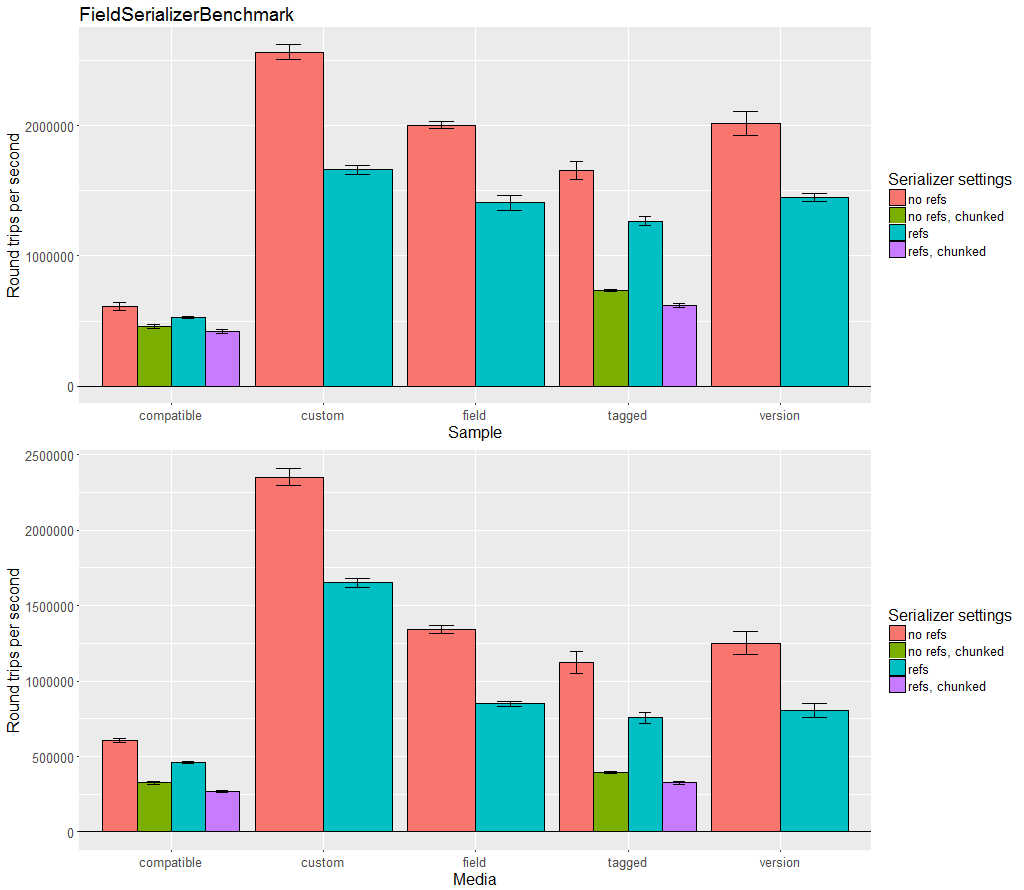
Benchmarks
Kryo provides a number of JMH-based benchmarks and R/ggplot2 files.
Kryo can be compared to many other serialization libraries in the JVM Serializers project. The benchmarks are small, dated, and homegrown rather than using JMH, so are less trustworthy. Also, it is very difficult to thoroughly compare serialization libraries using a benchmark. Libraries have many different features and often have different goals, so they may excel at solving completely different problems. To understand these benchmarks, the code being run and data being serialized should be analyzed and contrasted with your specific needs. Some serializers are highly optimized and use pages of code, others use only a few lines. This is good to show what is possible, but may not be a relevant comparison for many situations.
Links
Projects using Kryo
There are a number of projects using Kryo. A few are listed below. Please submit a pull request if you’d like your project included here.
- KryoNet (NIO networking)
- kryo-serializers (additional serializers)
- Twitter’s Scalding (Scala API for Cascading)
- Twitter’s Chill (Kryo serializers for Scala)
- Apache Fluo (Kryo is default serialization for Fluo Recipes)
- Apache Hive (query plan serialization)
- Apache Spark (shuffled/cached data serialization)
- DataNucleus (JDO/JPA persistence framework)
- CloudPelican
- Yahoo’s S4 (distributed stream computing)
- Storm (distributed realtime computation system, in turn used by many others)
- Cascalog (Clojure/Java data processing and querying details)
- memcached-session-manager (Tomcat high-availability sessions)
- Mobility-RPC (RPC enabling distributed applications)
- akka-kryo-serialization (Kryo serializers for Akka)
- Groupon
- Jive
- DestroyAllHumans (controls a robot!)
- Mybatis Redis-Cache (MyBatis Redis Cache adapter)
- Apache Dubbo (high performance, open source RPC framework)
Scala
- Twitter’s Chill (Kryo serializers for Scala)
- akka-kryo-serialization (Kryo serializers for Scala and Akka)
- Twitter’s Scalding (Scala API for Cascading)
- Kryo Serializers (Additional serializers for Java)
- Kryo Macros (Scala macros for compile-time generation of Kryo serializers)
Clojure
- Carbonite (Kryo serializers for Clojure)
Objective-C
- kryococoa (Objective-C port of Kryo)