SpringCloud熔断降级Hystrix详解
参考文档:https://www.cnblogs.com/qdhxhz/p/9581440.html
一、概念
为什么需要熔断降级?
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C有调用其他的微服务,这就是所谓的”扇出”,如扇出的链路上某个微服务的调用响应式过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统雪崩,所谓的”雪崩效应”
(1)需求背景
它是系统负载过高,突发流量或者网络等各种异常情况介绍,常用的解决方案。
在一个分布式系统里,一个服务依赖多个服务,可能存在某个服务调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败。
如果下图所示:A作为服务提供者,B为A的服务消费者,C和D是B的服务消费者。A不可用引起了B的不可用,并将不可用像滚雪球一样放大到C和D时,雪崩效应就形成了。
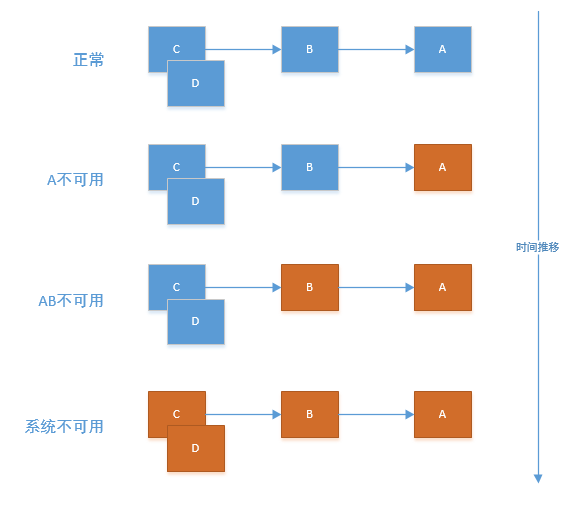
比如:某微服务业务逻辑复杂,在高负载情况下出现超时情况。
内部条件:程序bug导致死循环、存在慢查询、程序逻辑不对导致耗尽内存
外部条件:黑客攻击、促销、第三方系统响应缓慢。
(2)解决思路
解决接口级故障的核心思想是优先保障核心业务和优先保障绝大部分用户。比如登录功能很重要,当访问量过高时,停掉注册功能,为登录腾出资源。
(3)解决策略
熔断,降级,限流,排队
1、什么是熔断
一般是某个服务故障或者是异常引起的,类似现实世界中的‘保险丝’,当某个异常条件被触发,直接熔断整个服务,而不是一直等到此服务超时,为了防止防止整个系统的故障,
而采用了一些保护措施。过载保护。比如A服务的X功能依赖B服务的某个接口,当B服务接口响应很慢时,A服务X功能的响应也会被拖慢,进一步导致了A服务的线程都卡在了X功能上,A服务的其它功能也会卡主或拖慢。此时就需要熔断机制,即A服务不在请求B这个接口,而可以直接进行降级处理。
2、什么是降级
服务器当压力剧增的时候,根据当前业务情况及流量,对一些服务和页面进行有策略的降级。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和
大部分客户的得到正确的相应。
自动降级:超时、失败次数、故障、限流
(1)配置好超时时间(异步机制探测回复情况);
(2)不稳的的api调用次数达到一定数量进行降级(异步机制探测回复情况);
(3)调用的远程服务出现故障(dns、http服务错误状态码、网络故障、Rpc服务异常),直接进行降级。
人工降级:秒杀、双十一大促降级非重要的服务。
4、熔断和降级异同
相同点:
1)从可用性和可靠性触发,为了防止系统崩溃
2)最终让用户体验到的是某些功能暂时不能用
不同点:
1)服务熔断一般是下游服务故障导致的,而服务降级一般是从整体系统负荷考虑,由调用方控制
2)触发原因不同,上面颜色字体已解释
5、熔断到降级的流程讲解
Hystrix
Hystrix是一个用于分布式系统的延迟和容错的开源库。在分布式系统里,许多依赖不可避免的调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个服务失败,避免级联故障,以提高分布式系统的弹性。
Hystrix设计原则
1.防止单个服务的故障,耗尽整个系统服务的容器(比如tomcat)的线程资源,避免分布式环境里大量级联失败。通过第三方客户端访问(通常是通过网络)依赖服务出现失败、拒绝、超时或短路时执行回退逻辑
2.用快速失败代替排队(每个依赖服务维护一个小的线程池或信号量,当线程池满或信号量满,会立即拒绝服务而不会排队等待)和优雅的服务降级;当依赖服务失效后又恢复正常,快速恢复
3.提供接近实时的监控和警报,从而能够快速发现故障和修复。监控信息包括请求成功,失败(客户端抛出的异常),超时和线程拒绝。如果访问依赖服务的错误百分比超过阈值,断路器会跳闸,此时服务会在一段时间内停止对特定服务的所有请求
4.将所有请求外部系统(或请求依赖服务)封装到HystrixCommand或HystrixObservableCommand对象中,然后这些请求在一个独立的线程中执行。使用隔离技术来限制任何一个依赖的失败对系统的影响。每个依赖服务维护一个小的线程池(或信号量),当线程池满或信号量满,会立即拒绝服务而不会排队等待
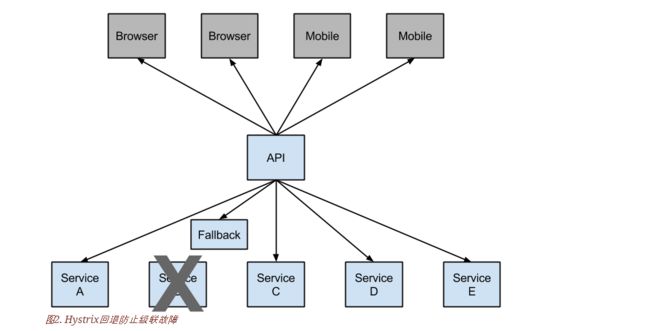
Hystrix特性
1.断路器机制:断路器很好理解, 当Hystrix Command请求后端服务失败数量超过一定比例(默认50%), 断路器会切换到开路状态(Open). 这时所有请求会直接失败而不会发送到后端服务. 断路器保持在开路状态一段时间后(默认5秒), 自动切换到半开路状态(HALF-OPEN). 这时会判断下一次请求的返回情况, 如果请求成功, 断路器切回闭路状态(CLOSED), 否则重新切换到开路状态(OPEN). Hystrix的断路器就像我们家庭电路中的保险丝, 一旦后端服务不可用, 断路器会直接切断请求链, 避免发送大量无效请求影响系统吞吐量, 并且断路器有自我检测并恢复的能力
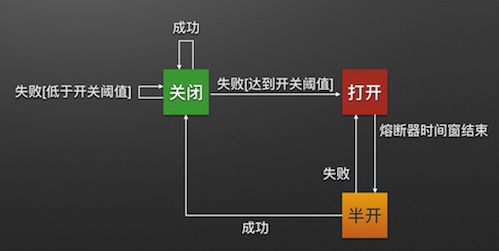
Hystrix提供了如下的几个关键参数,来对一个熔断器进行配置:
circuitBreaker.requestVolumeThreshold //滑动窗口的大小,默认为20
circuitBreaker.sleepWindowInMilliseconds //过多长时间,熔断器再次检测是否开启,默认为5000,即5s钟
circuitBreaker.errorThresholdPercentage //错误率,默认50%3个参数放在一起,所表达的意思就是:每当20个请求中,有50%失败时,熔断器就会打开,此时再调用此服务,将会直接返回失败,不再调远程服务。直到5s钟之后,重新检测该触发条件,判断是否把熔断器关闭,或者继续打开。
这里面有个很关键点,达到熔断之后,那么后面它就直接不去调该微服务。那么既然不去调该微服务或者调的时候出现异常,出现这种情况首先不可能直接把错误信息传给用户,所以针对熔断我们可以考虑采取降级策略。所谓降级,就是当某个服务熔断之后,服务器将不再被调用,此时客户端可以自己准备一个本地的fallback回调,返回一个缺省值。
这样做,虽然服务水平下降,但好歹可用,比直接挂掉要强,当然这也要看适合的业务场景。
2.服务降级:Fallback相当于是降级操作. 对于查询操作, 我们可以实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值. fallback方法的返回值一般是设置的默认值或者来自缓存.告知后面的请求服务不可用了,不要再来了。
3.依赖隔离(采用舱壁模式,Docker就是舱壁模式的一种):在Hystrix中, 主要通过线程池来实现资源隔离. 通常在使用的时候我们会根据调用的远程服务划分出多个线程池.比如说,一个服务调用两外两个服务,你如果调用两个服务都用一个线程池,那么如果一个服务卡在哪里,资源没被释放后面的请求又来了,导致后面的请求都卡在哪里等待,导致你依赖的A服务把你卡在哪里,耗尽了资源,也导致了你另外一个B服务也不可用了。这时如果依赖隔离,某一个服务调用A B两个服务,如果这时我有100个线程可用,我给A服务分配50个,给B服务分配50个,这样就算A服务挂了,我的B服务依然可以用。
Hystrix如何解决依赖隔离
1)、包裹请求:使用HystrixCommand包裹对依赖的调用逻辑,每个命令在独立的线程中执行,使用了设计模式中的“命令模式”;
2)、跳闸机制:当某服务的错误率超过一定阈值时,Hystrix可以自动或者手动跳闸,停止请求该服务一段时间;
3)、资源隔离:Hystrix为每个依赖都维护了一个小型的线程池(或者信号量)。如果该线程已满,则发向该依赖的请求就会被立即拒绝,而不是排队等候,从而加速失败判定;
4)、监控:Hystrix可以近乎实时地监控运行指标和配置的变化,例如成功、失败、超时、以及被拒绝的请求等;
5)、回退机制:当请求失败、超时、被拒绝,或当断路器打开时,执行回退逻辑,回退逻辑由开发人员自行提供,如返回一个缺省值;
6)、自我修复:断路器打开一段时间后,会自动进入“半开”状态,此时断路器可允许一个请求访问依赖的服务,若请求成功,则断路器关闭,否则断路器转为“打开”状态;
4.请求缓存:比如一个请求过来请求我userId=1的数据,你后面的请求也过来请求同样的数据,这时我不会继续走原来的那条请求链路了,而是把第一次请求缓存过了,把第一次的请求结果返回给后面的请求。
5.请求合并:我依赖于某一个服务,我要调用N次,比如说查数据库的时候,我发了N条请求发了N条SQL然后拿到一堆结果,这时候我们可以把多个请求合并成一个请求,发送一个查询多条数据的SQL的请求,这样我们只需查询一次数据库,提升了效率。
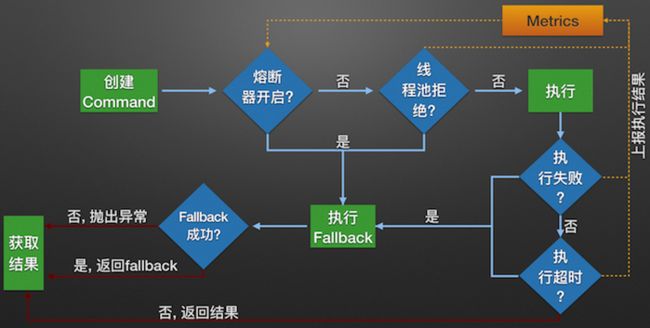
Hystrixl流程图如下:
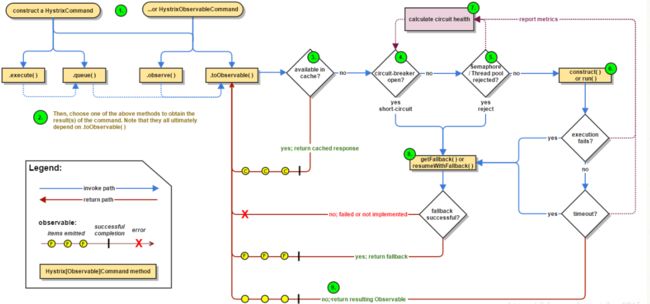
Hystrix流程说明:
1:每次调用创建一个新的HystrixCommand,把依赖调用封装在run()方法中.
2:执行execute()/queue做同步或异步调用.
4:判断熔断器(circuit-breaker)是否打开,如果打开跳到步骤8,进行降级策略,如果关闭进入步骤5.
5:判断线程池/队列/信号量是否跑满,如果跑满进入降级步骤8,否则继续后续步骤6.
6:调用HystrixCommand的run方法.运行依赖逻辑
6a:依赖逻辑调用超时,进入步骤8.
7:判断逻辑是否调用成功
7a:返回成功调用结果
7b:调用出错,进入步骤8.
8:计算熔断器状态,所有的运行状态(成功, 失败, 拒绝,超时)上报给熔断器,用于统计从而判断熔断器状态.
9:getFallback()降级逻辑.以下四种情况将触发getFallback调用:
(1):run()方法抛出非HystrixBadRequestException异常。
(2):run()方法调用超时
(3):熔断器开启拦截调用
(4):线程池/队列/信号量是否跑满
9a:没有实现getFallback的Command将直接抛出异常
9b:fallback降级逻辑调用成功直接返回
9c:降级逻辑调用失败抛出异常
10:返回执行成功结果这里接着前面的Ribbon进行Hystrix集成。说白了你想对一个请求进行熔断,必然不能让客户直接去调用那个请求,你必然要要对别人的请求进行包装一层和拦截,才能做点手脚,比如进行熔断,所以说要在Ribbon上动手脚。因为它是请求发起的地方。我们刚开始请求一个服务,为了负载均衡进行了拦截一次,现在我们要进行熔断,所以必须跟Ribbon集成一次,再进行请求拦截来熔断。
二、Hystrix实战
使用到的组件包括:Eureka、Feign包括以下三个项目:
(1)Eureka-server: 7001 注册中心
(2)product-server :8001 商品微服务
(3)order-server : 9001 订单微服务
1、pom.xml
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
2、application.yml
server:
port: 9001
#指定注册中心地址
eureka:
client:
serviceUrl:
defaultZone: http://localhost:7001/eureka/
#服务的名称
spring:
application:
name: order-service
#开启feign支持hystrix (注意,一定要开启,旧版本默认支持,新版本默认关闭)
# #修改调用超时时间(默认是1秒就算超时)
feign:
hystrix:
enabled: true
client:
config:
default:
connectTimeout: 2000
readTimeout: 2000
3、SpringBoot启动类
@SpringBootApplication
@EnableFeignClients
//添加熔断降级注解
@EnableCircuitBreaker
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
}
4、ProductClient
/**
* 商品服务客户端
* name = "product-service"是你调用服务端名称
* fallback = ProductClientFallback.class,后面是你自定义的降级处理类,降级类一定要实现ProductClient
*/
@FeignClient(name = "product-service",fallback = ProductClientFallback.class)
public interface ProductClient {
//这样组合就相当于http://product-service/api/v1/product/find
@GetMapping("/api/v1/product/find")
String findById(@RequestParam(value = "id") int id);
}
5、ProductClientFallback降级处理类
/**
* 针对商品服务,错降级处理
*/
@Component
public class ProductClientFallback implements ProductClient {
@Override
public String findById(int id) {
System.out.println("ProductClientFallback中的降级方法");
//这对gai该接口进行一些逻辑降级处理........
return null;
}
}
6、OrderController类
注意:fallbackMethod = "saveOrderFail"中的saveOrderFail方法中的参数类型,个数,顺序要和save一模一样,否则会报找不到saveOrderFail方法。
@RestController
@RequestMapping("api/v1/order")
public class OrderController {
@Autowired
private ProductOrderService productOrderService;
@RequestMapping("save")
//当调用微服务出现异常会降级到saveOrderFail方法中
@HystrixCommand(fallbackMethod = "saveOrderFail")
public Object save(@RequestParam("user_id")int userId, @RequestParam("product_id") int productId){
return productOrderService.save(userId, productId);
}
//注意,方法签名一定要要和api方法一致
private Object saveOrderFail(int userId, int productId){
System.out.println("controller中的降级方法");
Map msg = new HashMap<>();
msg.put("code", -1);
msg.put("msg", "抢购人数太多,您被挤出来了,稍等重试");
return msg;
}
}
7、测试
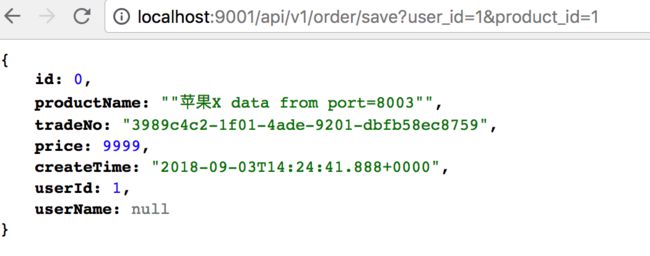
(1)正常情况
先将订单服务(order)和商品服务(product)同时启动,如图:

订单服务调用商品服务正常
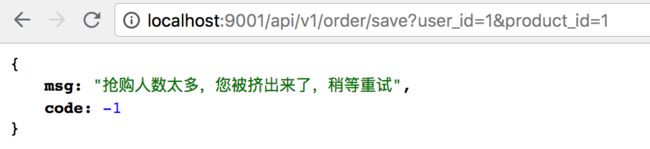
(2)异常情况
此刻我将商品微服务停掉:只启动订单微服务,这时去调用商品服务当然会出现超时异常情况。

在调接口,发现已经成功到降级方法里
在看controller中的降级方法和ProductClientFallback降级方法的实现先后顺序,它们的顺序是不固定的,有可能controller中降级方法先执行,也可能ProductClientFallback降级方法先执行。
具体要看哪个线程先获得cpu执行权。
三、结合redis模拟熔断降级服务异常报警通知实战
主要是完善完善服务熔断处理,报警机制完善结合redis进行模拟短信通知用户下单失败。
1、pom.xml
org.springframework.boot
spring-boot-starter-data-redis
2、application.yml
#服务的名称
#redis
spring:
application:
name: order-service
redis:
database: 0
host: 127.0.0.1
port: 6379
timeout: 2000
3、OrderController类
主要看降级方法的不同
@RestController
@RequestMapping("api/v1/order")
public class OrderController {
@Autowired
private ProductOrderService productOrderService;
//添加bean
@Autowired
private StringRedisTemplate redisTemplate;
@RequestMapping("save")
//当调用微服务出现异常会降级到saveOrderFail方法中
@HystrixCommand(fallbackMethod = "saveOrderFail")
public Object save(@RequestParam("user_id")int userId, @RequestParam("product_id") int productId,HttpServletRequest request){
return productOrderService.save(userId, productId);
}
//注意,方法签名一定要要和api方法一致
private Object saveOrderFail(int userId, int productId, HttpServletRequest request){
//监控报警
String saveOrderKye = "save-order";
//有数据代表20秒内已经发过
String sendValue = redisTemplate.opsForValue().get(saveOrderKye);
final String ip = request.getRemoteAddr();
//新启动一个线程进行业务逻辑处理
new Thread( ()->{
if (StringUtils.isBlank(sendValue)) {
System.out.println("紧急短信,用户下单失败,请离开查找原因,ip地址是="+ip);
//发送一个http请求,调用短信服务 TODO
redisTemplate.opsForValue().set(saveOrderKye, "save-order-fail", 20, TimeUnit.SECONDS);
}else{
System.out.println("已经发送过短信,20秒内不重复发送");
}
}).start();
Map msg = new HashMap<>();
msg.put("code", -1);
msg.put("msg", "抢购人数太多,您被挤出来了,稍等重试");
return msg;
}
}
4、测试
当20秒内连续发请求会提醒已发短
![]()
官方文档:https://github.com/Netflix/Hystrix/wiki/Configuration#execution.isolation.strategy