python3爬取中国考研网 考研学校名称和地区并进行数据清洗
目录
一、爬取数据
二、数据清洗
一、爬取数据
1.请求页面
(1)导入包
import requests
from bs4 import BeautifulSoup
import re
import pymysql(2)添加请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}2.获取页面、解析页面
(1)通过中国考研网首页获取各地研招网的url,以便于进一步爬取相关学校

url='http://www.chinakaoyan.com/'
res=requests.get(url,headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
data=soup.find_all('div',attrs={'class':'soso_area_box'})
data=str(data)
data=str(data)
pattern=re.compile(r'(.*?)',re.S)
item=pattern.findall(data)
print(item)![]()
(2)通过上一步返回的url进一步爬取各地区考研学校
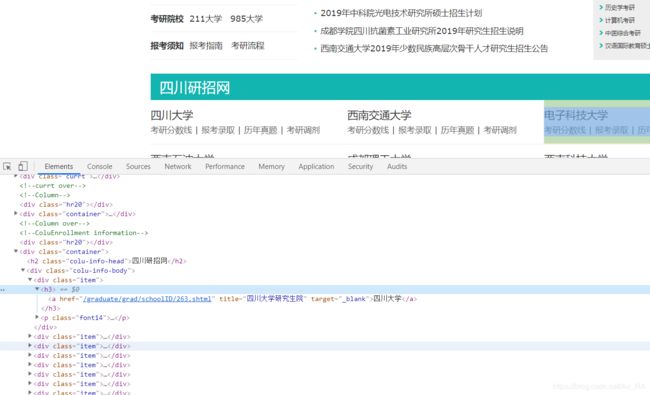
url='http://www.chinakaoyan.com/'+a_list[0]
res=requests.get(url,headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
data=soup.find_all('div',attrs={'class':'colu-info-body'})
data = str(data)
pattern = re.compile(r'.*?(.*?)
',re.S)
item = pattern.findall(data)
for i in item:
b_list=[]
b_list.append(i)
b_list.append(a_list[1])
# insert_info(b_list)
print(b_list)

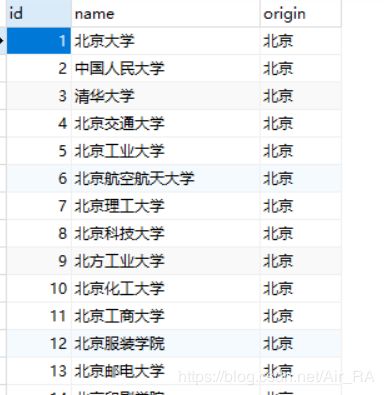
3.数据存储
保存到MySQL数据库
def insert_info(value):
db = pymysql.connect("localhost", "root", "root", "exercise")
cursor = db.cursor()
sql = "INSERT INTO exer(name,origin) VALUES (%s,%s)"
try:
cursor.execute(sql, value)
db.commit()
print('插入数据成功')
except:
db.rollback()
print("插入数据失败")
db.close()
二、数据清洗
1.检查数据
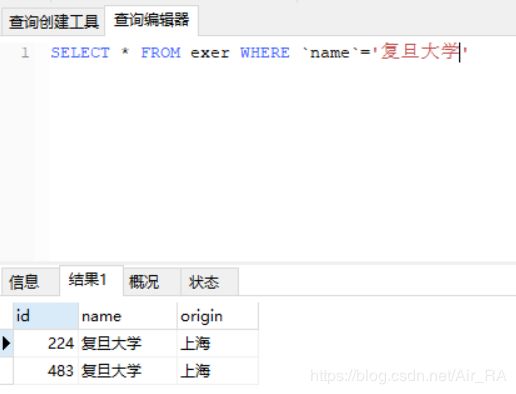
有重复数据
2.数据清洗
使用pandas进行数据清洗
(1)导入相关包
import pymysql
import pandas as pd
(2)从数据库拿出数据(查询)
def all_info():
#连接数据库(mysql,账户名,密码,数据库)
db = pymysql.connect("localhost", "root", "root", "exercise")
#创建游标
cursor = db.cursor()
#sql语句
sql='select * from exer'
try:
#执行sql语句
cursor.execute(sql)
results=cursor.fetchall()
# print(results)
return results
except:
print('error')
(3)构造DataFrame
results=all_info()
name=[]
locate=[]
for i in results:
name.append(i[1])
locate.append(i[2])
data={'name':name,'locate':locate}
df=pd.DataFrame(data)
(4)使用drop_duplicates去掉重复行
df1=df.drop_duplicates('name',keep='first',inplace=False)
(5)重新存入数据库
for i in range(len(df1)):
# print(df1.iloc[i])
insert(list(df1.iloc[i]))
三、源码
数据采集
import requests
from bs4 import BeautifulSoup
import re
import pymysql
def insert_info(value):
db = pymysql.connect("localhost", "root", "root", "exercise")
cursor = db.cursor()
sql = "INSERT INTO exer(name,origin) VALUES (%s,%s)"
try:
cursor.execute(sql, value)
db.commit()
print('插入数据成功')
except:
db.rollback()
print("插入数据失败")
db.close()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"
}
#从首页拿到 各地研究网的url
def geturl():
url='http://www.chinakaoyan.com/'
res=requests.get(url,headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
data=soup.find_all('div',attrs={'class':'soso_area_box'})
data=str(data)
data=str(data)
pattern=re.compile(r'(.*?)',re.S)
item=pattern.findall(data)
print(item)
return item
#拿到一个地区 每个学校的 学校名称
def getcityhtml(a_list):
url='http://www.chinakaoyan.com/'+a_list[0]
res=requests.get(url,headers=headers)
soup=BeautifulSoup(res.text,'html.parser')
data=soup.find_all('div',attrs={'class':'colu-info-body'})
data = str(data)
pattern = re.compile(r'.*?(.*?)
',re.S)
item = pattern.findall(data)
for i in item:
b_list=[]
b_list.append(i)
b_list.append(a_list[1])
# insert_info(b_list)
print(b_list)
#从geturl返回的url拿到各地信息
def everycity_gethtml():
a_list=geturl()
for i in a_list:
getcityhtml(i)
if __name__ == '__main__':
everycity_gethtml()
数据清洗
import pymysql
import pandas as pd
def all_info():
#连接数据库(mysql,账户名,密码,数据库)
db = pymysql.connect("localhost", "root", "root", "exercise")
#创建游标
cursor = db.cursor()
#sql语句
sql='select * from exer'
try:
#执行sql语句
cursor.execute(sql)
results=cursor.fetchall()
# print(results)
return results
except:
print('error')
def insert(value):
db = pymysql.connect("localhost", "root", "root", "exercise")
cursor = db.cursor()
sql = "INSERT INTO exer_info(name,origin) VALUES (%s,%s)"
try:
cursor.execute(sql, value)
db.commit()
print('插入数据成功')
except:
db.rollback()
print("插入数据失败")
db.close()
def school():
results=all_info()
name=[]
locate=[]
for i in results:
name.append(i[1])
locate.append(i[2])
data={'name':name,'locate':locate}
df=pd.DataFrame(data)
# print(df)
df1=df.drop_duplicates('name',keep='first',inplace=False) #按照name去除重复行
for i in range(len(df1)):
# print(df1.iloc[i])
insert(list(df1.iloc[i]))
school()