不是GPU的IPU,为什么更值得英伟达警惕?

在大规模数据中心,Graphcore 将会与英伟达进行正面的竞争。
作者包永刚
出品雷锋网产业组
2020 年 7 月 30 日,MLPerf 组织发布第三个版本 MLPerf Training v0.7 基准测试(Benchmark)结果。英伟达基于 5 月最新发布的 A100 Tensor Core GPU 构建的 DGX SuperPOD 系统在性能上打破了 8 个记录,这为不少想要打造比英伟达更好 GPU 的 AI 芯片公司增加了难度。
相比而言,7 月 15 日 Graphcore 发布的第二代 IPU GC200 更值得英伟达警惕。其中的原因,当然不是简单因为同为台积电 7nm 工艺的第二代 IPU 823 平方毫米的裸片面积比英伟达 A100 GPU 的 826 平方毫米更大。

而是,Graphcore 的第二代 IPU 在多个主流模型上的表现优于 A100 GPU,两者将在超大规模数据中心正面竞争。未来,IPU 可能在一些新兴的 AI 应用中展现出更大的优势。
1
多维度对比 GPU,IPU 有最高
100 倍性能提升
目前,AI 的应用主要还是集中在计算机视觉(CV)。就 CV 而言,以谷歌最新发布的 EfficientNet 模型的 Benchmarks(基准测试)来看,推理性能 IPU 吞吐量可以达到 GPU 的 15 倍,训练也有 7 倍的性能提升。

在 ResNet 的改进模型 ResNeXt-101 的推理中,IPU 可以带来 7 倍吞吐量的提升,同时时延降低了约 24 倍。在 ResNeXt-50 模型的一个训中练,IPU 的吞吐量比 GPU 提升 30% 左右。
另外,在目前最流行的 NLP 模型 BERT-Base 中,进行推理时相同时延 IPU 可以有 2 倍的吞吐量,训练时间减少 25% 到 36.3 小时左右,同时可以降低 20% 的功耗。

在概率模型中,IPU 同样有优势,在 MCMC 的一个训练模型中,IPU 比 GPU 有 15 倍的性能提升,同时缩短 15 倍的训练时间。在 VAE 的精度训练模型中,可以达到 4.8 倍的性能提升,缩短 4.8 倍的训练时间。
还有,目前比较受关注的销售预测和推荐模型。IPU 在用在做销售数据分析的 MLP 模型训练中相比 GPU 有最高 6 倍的性能提升,在用于推荐的 Dense Autoencoder 模型训练性能有 2.5 倍提升。
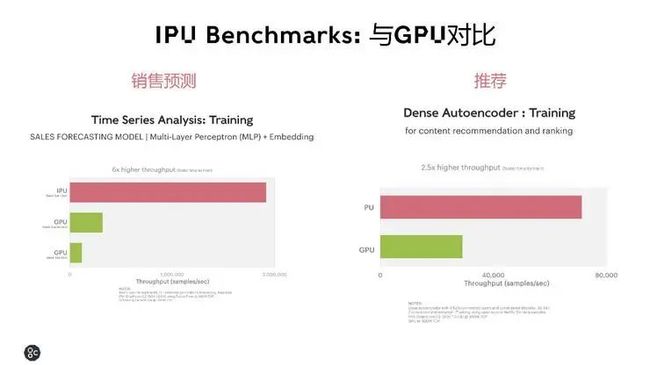
如果是在 IPU 更擅长的分组卷积内核中,组维度越少,IPU 的性能优势越明显,总体而言,有4-100 倍的吞吐量提升。

2
IPU 的三大技术突破
从 IPU 与 GPU 在当下 AI 应用的多个维度对比中,已经可以看到 IPU 的优势,这与 Graphcore 的计算、数据、通信三大关键技术突破密切相关。
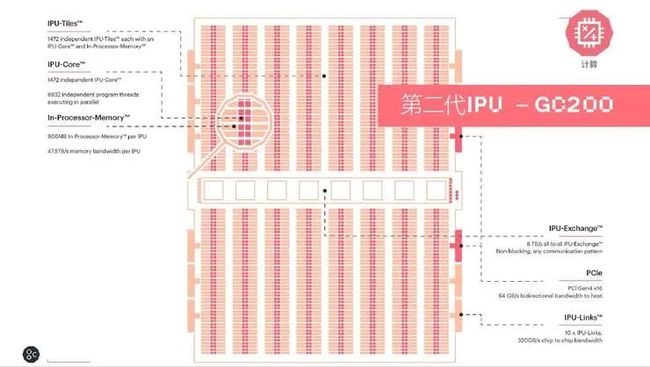
Graphcore 最新发布的第二代 IPU Colossus Mk2 GC200)算力核心从 1216 个提升到 1472 个独立的 IPU-Tiles 的单元,共有 8832 个可以并行执行的线程。In-Processor-Memory 从上一代的 300MB 提升到 900MB。每个 IPU 的 Memory 带宽为 47.5TB/s。
还包含了 IPU-Exchange 以及 PCI Gen4 跟主机交互的一个接口;以及 IPU-Links 320GB/s的一个芯片到芯片的互联。
计算
选用三个典型的应用场景从计算层面对比第二代和第一代 IPU,BERT-Large 的训练有 9.3 倍性能的提升,3 层 BERT 推理有 8. 5 倍的性能提升,EfficientNet-B3 有 7.4 倍的性能提升。第二代 IPU 相比第一代 IPU 有两倍峰值算力的提升,在典型的 CV 还是 NLP 的模型中,第二代 IPU 相比第一代 IPU 则展现出了平均 8 倍的性能提升。

这样的性能提升很重要的是处理器内部存储从 300MB 提升到了 900MB。Graphcore 中国区技术应用总负责人罗旭对雷锋网(公众号:雷锋网)表示,“我们在算力核心的微架构上做了一些调整,每个 IPU-Tiles 的性能本身就会更强,总体实现 2 倍的峰值性能提升。在有效算力方面,处理器内存储从 300M 提升到 900M 可以带来较大的提升。”
MK2 IPU 增加的存储器内存储主要是用于供我们模型的激活、权重的一些存储空间。因为处理器内存储的程序所占的空间与第一代 IPU 基本相同,所以增加的空间可以供算法模型可用的权重和激活容量有 6 倍以上的有效存储。

但是,300M 的处理器内存储本身就挑战很大,提升到 900M 面临着怎样的挑战?罗旭指出,“要让 MK2 支持 8000 个超线程并发一起工作,并且保证其线性度和各方面性能都要好,这个是非常复杂的一个技术,我们是利用 BSP 这一套软件+硬件+编译的机制,来保障性能能够提升。软件层面主要的挑战是对新模式的支持,所以我们的软件 Poplar SDK 要不断迭代。“
如果对比英伟达基于 8 个最新 A100 GPU 的 DGX-A100,Graphcore 8 个 M2000 组成得系统的 FP32 算力是 DGX-A100 的 12 倍,AI 计算是 3 倍,AI 存储是 10 倍。价格上,IPU-M2000 需要花费 25.96 万美元,DGX-A100 需要 19.9 万美元。Graphcore 有一定的性价比优势。

如果从应用的角度,在 EfficientNet-B4 的图象分类训练中,8 个 IPU-M2000(在 1U 的盒子里集成 4 个 GC200 IPU)的性能等同于 16 个 DGX-A100,这时候就能体现出 10 倍以上的价格优势。


数据
数据方面,Graphcore 提出了 IPU Exchange Memory 的交换式存储概念,相比英伟达当前使用的 HBM 技术,IPU- M2000 每个 IPU-Machine 通过 IPU-Exchange-Memory 技术,可以提供近 100 倍的带宽以及大约 10 倍的容量,这对于很多复杂的 AI 模型算法是非常有帮助。

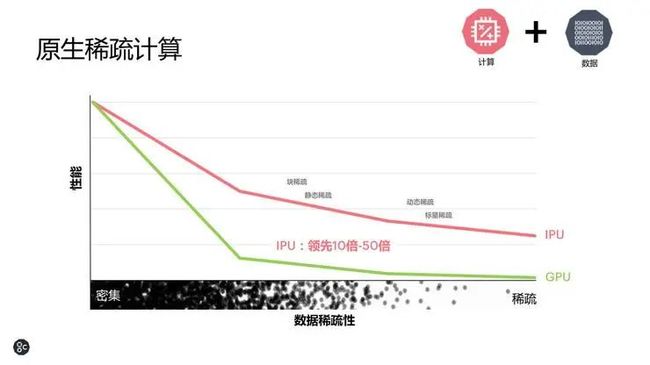
计算加上数据的突破可以让 IPU 在原生稀疏计算中展现出领先 IPU 10-50 倍的性能优势。在数据以及计算密集的情况下,GPU 表现非常好,但是随着数据稀疏性的增强,到了数据稀疏以及动态稀疏时,IPU 就有了比 GPU 越来越显著的优势。
Graphcore 高级副总裁兼中国区总经理卢涛说:“现在一些全球领先的研究,像 NLP 方面,大家开始来探索一些像 sparse NLP 的算法模型。我们的技术对很多超大规模的 AI 模型非常有帮助。”
通信
通信也是目前数据中心大规模计算非常关键的问题。为此,Graphcore 专为为 AI 横向扩展设计了 IPU-Fabric。IPU-Fabric 可以做到 2.8Tbps 超低延时的结构,同时最多可以支持 64000 个 IPU 之间的横向扩展。
卢涛介绍,IPU-Fabric 是由三种网络一起组成,第一种是 IPU-Link,第二种叫 IPU Gateway Link,第三种是 IPU over Fabric。IPU-Link 是在一个机架(rack)之内提供在 IPU 之间的一个通讯的接口。IPU Gateway Link 提供了机架和机架之间横向扩展之间的网络。IPU over Fabric 能够把 IPU 的集群和 x86 的集群进行非常灵活以及低延时、高性能组合起来的网络。

将计算、数据、通信的突破结合在一起,就可以用于构建大规模可扩展的 IPU-POD 系统。一个用于超算规模的 IPU-POD 的形态是一个 IPU-POD64,这是 IPU-POD 的一个基本组件,每个 IPU-POD64的机柜里面总共有 64 颗 IPU,提供 16PFlops 的算力、58GB 的 In-Processor-Memory,总共达到了 7 个 TB 的流存储。
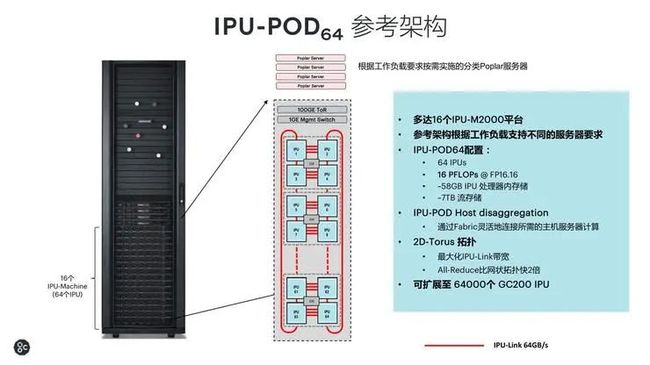
因此,在 IPU-POD 中间非常重要的是把 AI 的计算跟逻辑的控制进行了解耦,让系统易于部署,网络延时非常低,能够支持非常大型的一个算法模型,以及非常安全的多住户的使用。
卢涛表示,“IPU-Fabric 最高支持 64000 个 IPU-POD 组成的集群,总共能提供 16 EFlops FP16 的算力。日本前一阵发布的超算是 0.5 EFlops 算力。而我们基于 64000 个 IPU 总共可以组建 16 个 EFlops 算力,这非常惊人。”
3
Graphcore为什么值得英伟达关注?
“目前超大规模 IPU-POD 技术主要的应用场景还是大规模 AI 训练,包括自然语言处理以及机器视觉的应用,IPU-POD 都有优势。”卢涛指出,“譬如说做一个模型的训练, GPU 的性能是1,可能一个单机有 8 张卡,性能比 0.7 高。但如果把场景扩展到 1000 个 GPU 或者几千个 GPU,性能可能会下降到 0.7、0.6,好一点可能到 0.8,而超大规模的 IPU-POD 很重要的是要帮助大家解决大规模集群可扩展性的问题。
另外,从功耗的角度看,不同的场景会有一些差别。总体来看,单片 M2000 的整机系统功耗为 1.1KW,折合到每颗 IPU 处理器的性能功耗比 0.9TFlops/W,在同类面向数据中心高性能 AI 计算的产品中,比 A100 GPU 的 0.7Flops/W,华为 Ascend 910 的 0.71TFlops/W的能效比都高一些。
也就是说,在大规模数据中心,Graphcore 将会与英伟达进行正面的竞争。雷锋网认为,相比于来自类 GPU 的竞争,英伟达不应该忽视 Graphcore 的 IPU,特别是 Graphcore 一直都在强调其是为 AI 而生,面向的应用也是 CPU、GPU 不那么擅长的 AI 应用。

这从 Graphcore 的软件以及生态建设中也能看出。IPU 作为一款通用处理器能够同时支持训练和推理也提供统一的软件平台。最新的是 POPLAR SDK1.2 有三个特性:第一,会与比较先进的机器学习框架做好集成。第二,进一步开放低级别的 API,让开发者针对网络的性能做一些特定的调优。第三,增加框架支持,包括对 PyTorch 和 Keras 的支持。还会优化化了卷积库和稀疏库。
另外,通过支持全面的开发框架的三个主流操作系统 ubuntu、RedHat、CentOS,降低开发者的使用难度,同时通过进一步开放低级别 API,开源 POPLAR PopLibs 源代码。这些工作,正是想要让开发者利用 IPU 去创新,在新的应用领域构建 IPU 的竞争优势。

更进一步,Graphcore 面向商业用户、高校及研究机构、个人开发者都提供不同时长的免费 IPU 使用。在国内,Graphcore IPU 开发者云部署在金山云上,这里面使用了三种 IPU 产品,一种是 IPU-POD64,还有浪潮的 IPU 服务器(NF5568M5),以及戴尔的 IPU 服务器(DSS8440)。
雷锋网了解到,目前申请使用 Graphcore IPU 开发者云的主要是商业用户和高校,个人研究者比较少。
IPU 开发者云支持当前一些最先进和最复杂的 AI 算法模型的训练和推理。比如,高级计算机视觉类主要以分组卷积为代表的一些机器视觉的应用模型,像 ResNeXt、EfficientNet 等。基于时序分析类的应用,像 LSTM、GRU 等大量应用在自然语音应用、广告推荐、金融算法等方面的模型。排名和推荐类像 Deep Autoencoder,在概率模型方面,基于 MCMC 的一些算法交易的模型方面都有非常好的一些表现。

卢涛表示:“Graphcore 找到了自己的赛道,我们首要思考的是 IPU 如何帮助客户与合作伙伴解决他们目前使用 CPU 或者 GPU 上解决不了的问题。从全球看,我们最快落地的应用还是在超大规模数据中心,在金融、医疗健康领域进展非常大。”
还有一个影响 IPU 大规模商用非常关键的问题,片内存储高达 900M 的第二代 IPU 良率的成本如何?
卢涛对雷锋网表示,“成本分为几个部分,包括人员、工具、IP、流片成本。所以要考虑两个部分。第一部分,芯片生产的 BOM 成本,这部分基本是固定的。所以,第二部分的良率就是非常重要,我们从第一代产品到第二代产品都采用分布式存储架构,就会非常好地控制产品的良率,所以即使是 900M 处理器内存储,也不会对成本产生特别大的影响。”
已经有多家云合作伙伴的 Graphcore,正在通过硬件以及软件打造起中国创新社区来发展生态,接下来通过与 OEM、渠道合作伙伴的合作,将会如何与英伟达竞争呢?