用python的selenium模块,自动获取同花顺的利好和利空公告。
准备工作:
一、安装chrome浏览器(自行百度)。
二、下载chrome浏览器对应的chromedriver.exe (chrome浏览器的驱动,能通过selenium模块自动打开chrome浏览器)。

下载链接:http://npm.taobao.org/mirrors/chromedriver/
举例:如果是最新版的chrome浏览器,点击下图的2.40/![]()
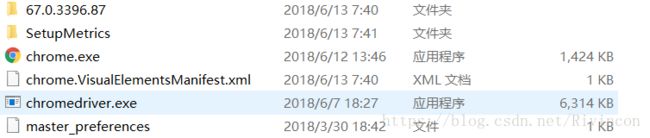
点击chromedriver_win32.zip开始下载,下载完成后解压。最后将解压的chromedriver.exe
![]()
放到\Google\Chrome\Application目录下
导入必要的模块
import re
from bs4 import BeautifulSoup
from selenium import webdriver
import os
import time有部分人导入以上模块时会报一下错误:
一、pip版本号太低的错误。
# 如果版本低的话使用如下命令更新pip
pip install --upgrade pip二、Microsoft Visual C++ 14.0 is required
打开 https://www.lfd.uci.edu/~gohlke/pythonlibs/ 找到

下载自己python版本号对应的Twisted,然后用pip安装
pip install C:\Users\Rivincon\Downloads\Twisted-18.4.0-cp36-cp36m-win_amd64.whl
代码部分:
# 获取driver
def get_driver():
chromedriver = "C:/Program Files (x86)/Google/Chrome/Application/chromedriver"
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
return driver# 获取soup以便更好地对标签进行管理
def get_soup(driver):
time.sleep(0.5)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
return soupdef open_file(file_name, driver, click_text):
try:
f = open(file_name, 'w')
except:
print("文件打开失败")
# 找到网页中a标签里面innerHTML内容为click_text的元素并模拟鼠标的点击事件
driver.find_element_by_link_text(click_text).click()
soup = get_soup(driver)
use_write(soup, f)
# 通过正则表达式获取网页中尾页的页数
last_page = re.findall(r'尾页',
driver.page_source, re.S)
last_page = int(last_page[0])
for i in range(2, last_page + 1):
# 找到网页中a标签里面innerHTML内容为下一页的元素并模拟鼠标点击事件
driver.find_element_by_link_text("下一页").click()
# time.sleep()的作用是因为代码执行的速度太快如果不用time.sleep()的花下面获取的soup将是点击之前的网页的源码
time.sleep(0.5)
soup = get_soup(driver)
use_write(soup, f)
f.close()# 将传过来的stock_data(日期),stock_code(股票代码), stock_name(股票名称),stock_web(股票的公告地址),stock_rise_or_down(股票的最新价和涨幅)写入到文件f中
def write_data_to_file(stock_date, stock_code, stock_name, stock_web, stock_rise_or_down, f):
for i in range(len(stock_date)):
f.write("日期:")
f.write(stock_date[i])
f.write('\t\t')
f.write("股票代码:")
f.write(stock_code[i])
f.write('\t\t')
f.write("股票简称:")
f.write(stock_name[i])
f.write('\t\t')
j = i * 2
f.write("最新价:" + stock_rise_or_down[j])
f.write('\t\t')
f.write("涨跌幅:" + stock_rise_or_down[j + 1])
f.write('\n')
f.write("相关公告:")
f.write('\n')
for k in stock_web:
stock_notice = k[1].replace(' ', '')
stock_notice = stock_notice.replace('A', 'A')
if stock_name[i] in stock_notice or stock_name[i][0:2] in stock_notice:
stock_info = k[0]
f.write(stock_notice)
f.write('\t\t')
f.write(stock_info)
f.write('\n')
else:
continue
f.write('\n')# 调用上面的write_data_to_file()
def use_write(soup, f):
# 获取div中id为J-ajax-main的内容
get_div_content = soup.find_all(id='J-ajax-main')
# 利用正则表达式匹配时间
stock_date = re.findall(r'(\d{4}-\d{2}-\d{2}) ', str(get_div_content), re.S)
# 利用正则表达式匹配股票代码
stock_code = re.findall(r'>(\d{6})<', str(get_div_content), re.S)
# 获取a标签中class属性为J_showCanvas的内容
get_a_content = soup.find_all('a', attrs={'class': 'J_showCanvas'})
# 利用正则表达式匹配股票名称(\u4e00-\u9fa5 是匹配中文)
stock_name = re.findall(r'>([\u4e00-\u9fa5*0-9a-zA-Z]{2,5})<', str(get_a_content), re.S)
soup = BeautifulSoup(str(get_div_content), 'html.parser')
get_div_clearfix = soup.find_all('div', attrs={'class': 'clearfix'})
# 利用正则表达式匹配股票的公告的网址和公告的标题
stock_web = re.findall(r'(.*?)', str(get_div_clearfix), re.S)
stock_rise_or_down = re.findall(r'([0-9.\u4e00-\u9fa5-]{1,6}) ', str(get_div_content), re.S)
time.sleep(0.5)
write_data_to_file(stock_date, stock_code, stock_name, stock_web, stock_rise_or_down, f)if __name__ == '__main__':
url = 'http://data.10jqka.com.cn/market/ggsd/ggtype/2/'
driver = get_driver()
driver.get(url)
open_file("同花顺利好公告.txt", driver, "利好公告")
open_file("同花顺利空公告.txt", driver, "利空公告")