对象存储简介
一 导读
计算机系统是图灵机的高效实现,即根据输入数据的规则得到输出数据。现在的计算机系统由CPU、内存、总线、外设(如网络设备、存储设备)等组成,其中,存储是非常重要的一部分。
近年来,随着存储设备的高速发展,存储设备价格不断降低,加上信息的载体由2G时代的文本转变为3G时代的图片、4G时代的视频,信息、数据的爆炸式增长促使分布式存储的诞生。
二 存储分类
按照服务或接口,存储大体上可分为三类:块存储、文件存储,以及对象存储。
2.1 块存储
块存储,是将物理盘划分为逻辑盘,再将逻辑盘映射给主机使用的存储方式。一般而言,一块逻辑盘由多块物理盘虚构而来,因此往一块逻辑盘读写数据时,多块物理盘能同时工作,可以实现并行读写。块存储使用DAS架构,对于DAS来说,存储只能通过与之连接的主机进行访问,不能跨机访问数据,因此块存储的共享能力是比较差的。对比文件存储和对象存储,块存储有最低级别的延时和最高级别的IOPS,适合对延时要求极低的系统,例如数据库、中间件、虚拟机等,很少直接面向用户。
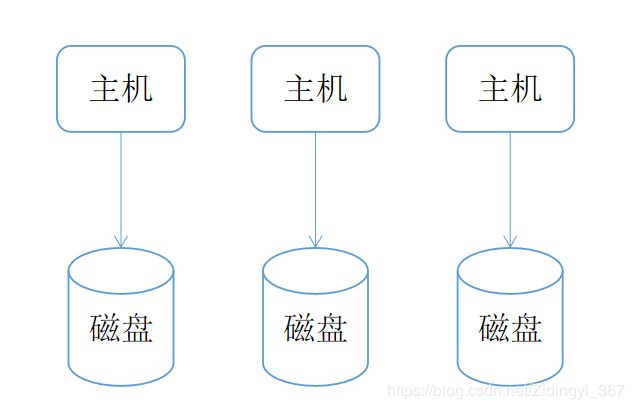 DAS
DAS
2.2 文件存储
文件存储,通常指的是遵循POSIX协议,同时具备并行化访问和冗余机制的存储方式,现在也将非POSIX协议的GFS、HDFS、FastDFS等归为文件存储。文件存储使用NAS架构,NAS指的是通过网络协议将多个存储设备和一群计算机想连接,因此不存在共享问题。与较底层的块存储不同,文件存储上升到了应用层,由于通过网络,且采用上层协议,因此开销大,延时对比块存储有所升高。同时文件存储引进了目录,十分类似我们平时Windows的文件结构,当单个目录文件数量过大时,文件查找效率会急剧下降。
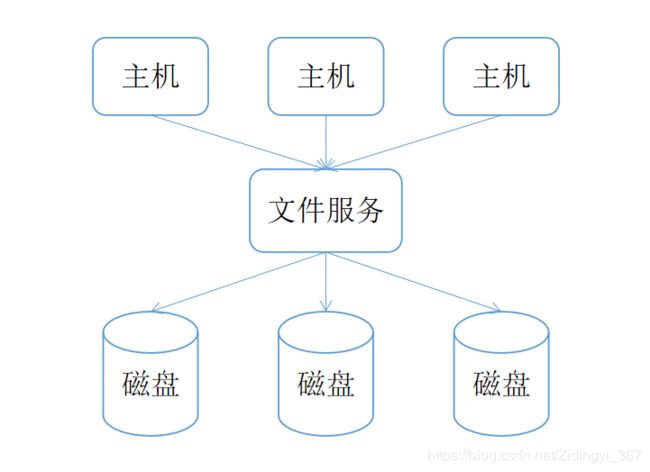 NAS
NAS
2.3 对象存储
对象存储相比文件存储更加简洁,抛弃了命名空间、文件目录等结构,更加扁平化,在使用、扩展、维护方面更加符合大众化思想。操作主体由文件变为对象,对象的操作主要以Put、Get和Delete为主,十分类似Java的HashMap,只不过对象存储中的对象不支持修改。总体来说,对象存储是为了克服块存储和文件存储的缺点,并发挥它们各自的优点而出现的。块存储的优点是读写速度快,不太适合共享。文件存储的优点是利于共享,缺点是读写速度慢。对象存储不仅读写速度快,而且适用于分布式系统,利于共享。常见的开源对象存储有Ceph、Swift,目前阶段,Ceph比Swift更加成熟、稳定。
三 Ceph
Ceph是一个去中心化、强一致性、易扩展性的分布式存储系统,目前业界自研商业存储例如阿里云存储、华为云存储、七牛云存储等或多或少都借鉴Ceph的设计思想和物理架构。
3.1 核心组件与重要概念
Ceph架构要比大多数文件存储复杂得多,组件也比大多数文件存储多得多。对于一般用户而言,理解核心组件Monitor和OSD,以及重要概念PG和CRUSH,足以对Ceph有一个比较深的印象。
3.1.1 Monitor
监视器,负责监控Ceph的运行状况。Ceph需要多个Monitor组成小集群,它们通过Paxos同步数据,用来保存OSD的元数据。
3.1.2 OSD
数据存储单元,负责将数据以对象的形式存储到集群中每个节点的物理盘。OSD会与其余OSD进行心跳检查,并将一些变化情况上报给Monitor。一般情况下,一块磁盘对于一个OSD。一般而言,Ceph一般包含多个OSD,只有当OSD、PG数量足够多时,CRUSH才能实现数据均匀分布。
3.1.3 PG
PG是为了更好地、更快地分配、定位数据而引入的逻辑概念,一个PG包含多个OSD。Object要先定位到PG,再由PG定位到对于的OSD。
3.1.4 CRUSH
CRUSH是Ceph使用的数据分布算法,类似一致性哈希,但是比一致性哈希更优越、更先进,CRUSH除了让数据分配到预期的地方之外,还有数据均匀分布、灵活应对集群伸缩、合理控制数据失效域等功能,可以说CRUSH算法是Ceph的精髓所在。
3.2 数据寻址
分布式存储系统,必须要能够解决两个最基本的问题,即现在应该把数据写到什么地方与之前把数据写到什么地方了,因此会涉及数据如何寻址的问题。Ceph的数据寻址要经历以下三个阶段:
3.2.1 File->Object
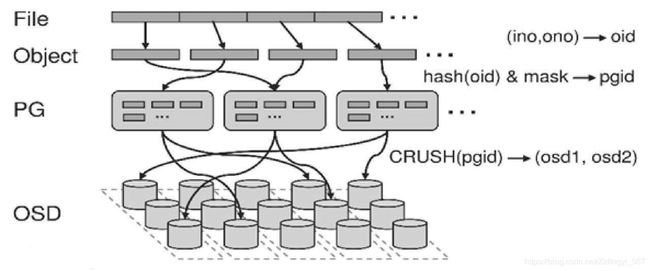
Ceph条带化之后,将获得N个带有唯一oid的Object。oid是进行线性映射生成的,即由File的元数据ino以及Ceph条带化产生的Object序号ono连缀而成,举例而言,如果1个ID为filename的File被切分为3个Object,则Object序号依次为0、1和2,最终得到的oid依次为filename0、filename1和filename2。
3.2.2 Object->PG
在File被映射为一个或者多个Object之后,就需要将每个Object独立地映射到PG中,这个映射过程也很简单,其计算公式pgid=hash(oid)&mask,其中mask=PG总数-1,PG总数需要设置为2的整数幂。在Object、PG数量较多时,以上计算结果近似从所有PG中均匀选择一个。
3.2.3 PG->OSD
在得到pgid之后,就需要将PG映射到数据实际存储单元OSD上,其计算过程CRUSH(PGId)=(OSD1,OSD2,OSD3)。CRUSH算法的结果是得到一组OSD,在PG数量、OSD数量、以及存储策略不变的情况下,其结果一般不会变化。
3.3 冗余方式
数据冗余能在分布式系统发生故障时起到恢复数据的作用,也是分布式系统可靠性的常用手段。数据冗余方式有两种,一种是多副本,一种是纠删码。
3.3.1 多副本
多副本是分布式系统常见的冗余方式,简单易用,可靠性极高。多副本相对纠删码更加成熟、稳定,也是大部分中间件冗余数据的常见手段,例如Kafka分区副本。缺点是磁盘利用率低,在N副本模式下,磁盘利用率只有1/N。在分布式存储中,除了可靠性要考虑之外,磁盘利用率也是要考虑的一个指标。
3.3.2 纠删码
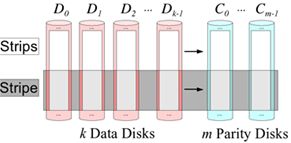
纠删码主要是通过利用算法将原始的数据进行编码得到校验,并将数据和校验一并存储起来,以达到容错的目的。其基本思想是将k块原始数据元素通过一定的编码计算,得到m块校验元素。当其中任意m块元素出错(包括数据和校验出错),均可以通过对应的重构算法恢复出原来的k块数据。生成校验的过程被成为编码,恢复丢失数据块的过程被称为解码。
纠删码能够基于更少的冗余设备,提供和多副本近似的可靠性,但是纠删码也带来了计算量和网络负载的额外负担,磁盘利用率越高,就需要花费更多的计算量和网络负载。在对象存储中,需要在磁盘利用率和可靠性之间做一个平衡。在纠删码模式下,磁盘利用率为k/(k+m),远比多副本1/N高。一般而言,纠删码模式下,磁盘利用率推荐在75%(k=9,m=3)较为合适,磁盘利用率更高的话,可靠性会进一步降低,进而影响对象存储的稳定性。
在对象存储实际生产环境中,对于热数据会使用多副本策略来冗余,冷数据使用纠删码来冗余。
四 结语
存储方式没有好坏之分,只有适合与不适合之分,满足当前业务系统需求的存储方式就是最好的存储方式。这就好像现在机械硬盘已经存在这么多年了,磁带仍然没有消失的原因,因为它用一种最廉价的方式解决了大容量离线数据的存储问题,尽管它是很慢的。