八、Python创建目录文件夹
Python对文件的操作还算是方便的,只需要包含os模块进来,使用相关函数即可实现目录的创建。
主要涉及到三个函数
1、os.path.exists(path) 判断一个目录是否存在
2、os.makedirs(path) 多层创建目录
3、os.mkdir(path) 创建目录
def mkdir(path):
# 引入模块
import os
# 去除首位空格
path=path.strip()
# 去除尾部 \ 符号
path=path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
print path+' 创建成功'
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print path+' 目录已存在'
return False
# 定义要创建的目录
mkpath="d:\\qttc\\web\\"
# 调用函数
mkdir(mkpath)
上面没有使用os.mkdir(path)函数,而是使用了多层创建目录函数os.makedirs(path)。
这两个函数之间最大的区别是当父目录不存在的时候os.mkdir(path)不会创建,os.makedirs(path)则会创建父目录。
Python3写入文件常用方法
all_the_text = 'hello python'
# 最简单的方法
open('d:/text.txt', 'w').write(all_the_text)
all_the_data = b'abcd1234'
open('d:/data.txt', 'wb').write(all_the_data)
# 更好的办法
file_object = open('d:/text2.txt', 'w')
file_object.write(all_the_text)
file_object.close()
# 分段写入
list_of_text_strings = ['hello', 'python', 'hello', 'world']
file_object = open('d:/text3.txt', 'w')
for string in list_of_text_strings:
file_object.writelines(string)
list_of_text_strings = ['hello', 'python', 'hello', 'world']
file_object = open('d:/text4.txt', 'w')
file_object.writelines(list_of_text_strings)
九、文件写入简介
在这里,我们有写入图片和写入文本两种方式
1)写入图片
#传入图片地址,文件名,保存单张图片
def saveImg(self,imageURL,fileName):
u = urllib.urlopen(imageURL)
data = u.read()
f = open(fileName, 'wb')
f.write(data)
print(u"正在悄悄保存她的一张图片为",fileName)
f.close()
2)写入文本
def saveBrief(self,content,name):
fileName = name + "/" + name + ".txt"
f = open(fileName,"w+")
print(u"正在偷偷保存她的个人信息为",fileName)
f.write(content.encode('utf-8'))
3)创建新目录
def mkdir(self,path):
path = path.strip()
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
print(u"偷偷新建了名字叫做",path,u'的文件夹')
# 创建目录操作函数
os.makedirs(path)
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(u"名为",path,'的文件夹已经创建成功')
return False
发送请求时带Header:
import urllib,urllib2
url = 'http://www.super-ping.com/ping.php?node='+node+'&ping=www.google.com'
headers = { 'Host':'www.super-ping.com',
'Connection':'keep-alive',
'Cache-Control':'max-age=0',
'Accept': 'text/html, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.89 Safari/537.36',
'DNT':'1',
'Referer': 'http://www.super-ping.com/?ping=www.google.com&locale=sc',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,ja;q=0.6'
}
data = None
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
compressedData = response.read()
反盗链
某些站点有所谓的反盗链设置,其实说穿了很简单,
就是检查你发送请求的header里面,referer站点是不是他自己,
所以我们只需要像把headers的referer改成该网站即可,以cnbeta为例:
headers = {
'Referer':'http://www.cnbeta.com/articles'
}
headers是一个dict数据结构,你可以放入任何想要的header,来做一些伪装。
例如,有些网站喜欢读取header中的X-Forwarded-For来看看人家的真实IP,可以直接把X-Forwarde-For改了。
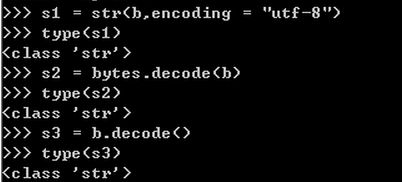
编码:
使用encode()函数对字符串进行编码,转换成二进制字节数据
可用decode()函数将字节解码成字符串
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘utf-8’),表示将unicode编码的字符串转换成utf-8编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘utf-8’),表示将utf-8编码的字符串转换成unicode编码。
http://www.cnblogs.com/284628487a/p/5584714.html
Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
==================================================================
1、多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠(\)来实现多行语句,例如:
total = item_one + \
item_two + \
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(\),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
2、字符串
python中单引号和双引号使用完全相同。
使用三引号('''或""")可以指定一个多行字符串。
转义符 '\'
自然字符串, 通过在字符串前加r或R。 如 r"this is a line with \n" 则\n会显示,并不是换行。
python允许处理unicode字符串,加前缀u或U, 如 u"this is an unicode string"。
字符串是不可变的。
先说1双引号与3个双引号的区别,双引号所表示的字符串通常要写成一行
如:
s1 = "hello,world"
如果要写成多行,那么就要使用/ (“连行符”),如
s2 = "hello,/
world"
s2与s1是一样的。如果你用3个双引号的话,就可以直接写了,如下:
s3 = """hello,
world,
hahaha."""
那么s3实际上就是"hello,/nworld,/nhahaha.", 注意“/n”,所以,如果你的字符串里/n很多,你又不想在字符串中用/n的话,那么就可以使用3个双引号。而且使用3个双引号还可以在字符串中增加注释,如下:
s3 = """hello, #hoho, this is hello, 在3个双引号的字符串内可以有注释哦
world, #hoho, this is world
hahaha."""
不过在print s3的时候连注释内容会一起给打印出来。这就是3个双引号和1个双引号表示字符串的区别了
实际上python支持单引号是有原因的,下面我来比较1个单引号和1个双引号的区别:
当我用单引号来表示一个字符串时,如果要表示 Let's go 这个字符串,必须这样:
s4 = 'Let/'s go'
注意没有,字符串中有一个',而字符串又是用'来表示,所以这个时候就要使用转义符 / , 如果你的字符串中有一大堆的转义符,看起来肯定不舒服,python也很好的解决了这个问题,
如下:s5 = "Let's go"
这时,我们看,python知道你是用 " 来表示字符串,所以python就把字符串中的那个单引号 ' , 当成普通的字符处理了,是不是很简单。
对于双引号,也是一样的,下面举个例子
s6 = 'I realy like "python"!'
这就是单引号和双引号都可以表示字符串的原因了
同一行显示多条语句
Python可以在同一行中使用多条语句,语句之间使用分号(;)分割
import sys; x = 'runoob'; sys.stdout.write(x + '\n')
字符串格式化
字符串格式化符号与C语言一样,查下即可
print ("我叫 %s 今年 %d 岁!" % ('小明', 10) )
结果:
我叫 小明 今年 10 岁!
python字符串连接的N种方式
最原始的字符串连接方式:str1 + str2
python 新字符串连接语法:str1, str2
奇怪的字符串方式:str1 str2
% 连接字符串:‘name:%s; sex: ’ % ('tom', 'male')
字符串列表连接:str.join(some_list)
第一种,有编程经验的人都知道,直接用 “+” 来连接两个字符串:
'Jim' + 'Green' = 'JimGreen'
第二种比较特殊,如果两个字符串用“逗号”隔开,那么这两个字符串将被连接,但是,字符串之间会多出一个空格:
'Jim', 'Green' = 'Jim Green'
第三种也是 python 独有的,只要把两个字符串放在一起,中间有空白或者没有空白:两个字符串自动连接为一个字符串:
'Jim''Green' = 'JimGreen'
'Jim' 'Green' = 'JimGreen'
第四种功能比较强大,借鉴了C语言中 printf 函数的功能,如果你有C语言基础,看下文档就知道了。这种方式用符号“%”连接一个字符串和一组变量,字符串中的特殊标记会被自动用右边变量组中的变量替换:
'%s, %s' % ('Jim', 'Green') = 'Jim, Green'
第五种就属于技巧了,利用字符串的函数 join 。这个函数接受一个列表,然后用字符串依次连接列表中每一个元素:
var_list = ['tom', 'david', 'john']
a = '###'
a.join(var_list) = 'tom###david###john'
其实,python 中还有一种字符串连接方式,不过用的不多,就是字符串乘法,如:
a = 'abc'
a * 3 = 'abcabcabc'
=================================
3、多个语句构成代码组
像if、while、def和class这样的复合语句,首行以关键字开始,以冒号( : )结束,该行之后的一行或多行代码构成代码组。
if expression :
suite
elif expression :
suite
else :
suite
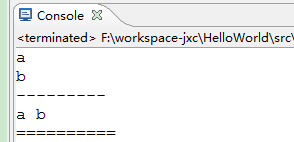
print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end=""
x="a"
y="b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
print("==========")
结果:注意空白行没显示,print()也没显示
4、Python3 基本数据类型
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
多个变量赋值
Python允许你同时为多个变量赋值。例如:
a = b = c = 1
以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
您也可以为多个对象指定多个变量。例如:
a, b, c = 1, 2, "runoob"
以上实例,两个整型对象 1 和 2 的分配给变量 a 和 b,字符串对象 "runoob" 分配给变量 c
Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Sets(集合)
Dictionary(字典)
Number(数字)
Python3 支持 int、float、bool、complex(复数)。
在Python 3里,只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
内置的 type() 函数可以用来查询变量所指的对象类型。
>>> a, b, c, d = 20, 5.5, True, 4+3j
>>> print(type(a), type(b), type(c), type(d))
还可以用 isinstance 来判断:
>>> a = 111
>>> isinstance(a, int)
True
class A:
pass
isinstance(A(), A) # returns True
type(A()) == A # returns True
注意:
1、Python可以同时为多个变量赋值,如a, b = 1, 2。
2、一个变量可以通过赋值指向不同类型的对象。
3、数值的除法(/)总是返回一个浮点数,要获取整数使用//操作符。
4、在混合计算时,Python会把整型转换成为浮点数。
complex:
3.14j
45.j
3e+26J
Python还支持复数,复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型
String(字符串)
Python中的字符串用单引号(')或双引号(")括起来,同时使用反斜杠(\)转义特殊字符
字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
加号 (+) 是字符串的连接符, 星号 (*) 表示复制当前字符串,紧跟的数字为复制的次数
str = 'Runoob'
print (str) # 输出字符串 Runoob
print (str[0:-1]) # 输出第一个个到倒数第二个的所有字符 Runoo
print (str[0]) # 输出字符串第一个字符 R
print (str[2:5]) # 输出从第三个开始到第五个的字符 noo
print (str[2:]) # 输出从第三个开始的后的所有字符 noob
print (str * 2) # 输出字符串两次 RunoobRunoob
print (str + "TEST") # 连接字符串 RunoobTEST
Python 使用反斜杠(\)转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串:
>>> print('Ru\noob')
Ru
oob
>>> print(r'Ru\noob')
Ru\noob
注意:
1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变。
与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如word[0] = 'm'会导致错误。
List(列表)
列表是写在方括号[ ]之间、用逗号分隔开的元素列表。
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
tinylist = [123, 'runoob']
print (list + tinylist) # 连接列表
['abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob']
截取方式和字符串一样。
与字符串不一样的是,列表中的元素是可以改变的:
>>> a = [1, 2, 3, 4, 5, 6]
>>> a[0] = 9

#删除列表元素
用 del 语句来删除列表的的元素:
list = ['Google', 'Runoob', 1997, 2000]
print (list)
del list[2]
print ("删除第三个元素 : ", list)
结果:
删除第三个元素 : ['Google', 'Runoob', 2000]
注意:我们会在接下来的章节讨论remove()方法的使用
#列表截取与拼接
Python的列表截取与字符串操作类型,如下所示:
L=['Google', 'Runoob', 'Taobao']
L[2] 'Taobao' 读取第三个元素
L[-2] 'Runoob' 从右侧开始读取倒数第二个元素: count from the right
L[1:] ['Runoob', 'Taobao'] 输出从第二个元素开始后的所有元素
拼接
>>> squares = [1, 4, 9, 16, 25]
>>> squares + [36, 49, 64, 81, 100]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
#嵌套列表
使用嵌套列表即在列表里创建其它列表,例如:
>>> a = ['a', 'b', 'c']
>>> n = [1, 2, 3]
>>> x = [a, n]
>>> x
[['a', 'b', 'c'], [1, 2, 3]]
>>> x[0]
['a', 'b', 'c']
>>> x[0][1]
'b'

>>> a = [66.25, 333, 333, 1, 1234.5]
>>> print(a.count(333), a.count(66.25), a.count('x'))
2 1 0
>>> a.insert(2, -1)
>>> a.append(333)
>>> a
[66.25, 333, -1, 333, 1, 1234.5, 333]
>>> a.index(333)
1
>>> a.remove(333)
>>> a
[66.25, -1, 333, 1, 1234.5, 333]
>>> a.reverse()
>>> a
[333, 1234.5, 1, 333, -1, 66.25]
>>> a.sort()
>>> a
[-1, 1, 66.25, 333, 333, 1234.5]
将列表当做堆栈使用
列表方法使得列表可以很方便的作为一个堆栈来使用,堆栈作为特定的数据结构,最先进入的元素最后一个被释放(后进先出)。用 append() 方法可以把一个元素添加到堆栈顶。用不指定索引的 pop() 方法可以把一个元素从堆栈顶释放出来。例如:
>>> stack = [3, 4, 5]
>>> stack.append(6)
>>> stack.append(7)
>>> stack
[3, 4, 5, 6, 7]
>>> stack.pop()
7
>>> stack
[3, 4, 5, 6]
>>> stack.pop()
6
>>> stack.pop()
5
>>> stack
[3, 4]
将列表当作队列使用
也可以把列表当做队列用,只是在队列里第一加入的元素,第一个取出来;但是拿列表用作这样的目的效率不高。在列表的最后添加或者弹出元素速度快,然而在列表里插入或者从头部弹出速度却不快(因为所有其他的元素都得一个一个地移动)。
>>> from collections import deque
>>> queue = deque(["Eric", "John", "Michael"])
>>> queue.append("Terry") # Terry arrives
>>> queue.append("Graham") # Graham arrives
>>> queue.popleft() # The first to arrive now leaves
'Eric'
>>> queue.popleft() # The second to arrive now leaves
'John'
>>> queue # Remaining queue in order of arrival
deque(['Michael', 'Terry', 'Graham'])
列表推导式
列表推导式提供了从序列创建列表的简单途径。将一些操作应用于某个序列的每个元素,用其获得的结果作为生成新列表的元素,或者根据确定的判定条件创建子序列。
每个列表推导式都在 for 之后跟一个表达式,然后有零到多个 for 或 if 子句。返回结果是一个根据表达从其后的 for 和 if 上下文环境中生成出来的列表。如果希望表达式推导出一个元组,就必须使用括号。
这里我们将列表中每个数值乘三,获得一个新的列表:
>>> vec = [2, 4, 6]
>>> [3*x for x in vec]
[6, 12, 18]
现在我们玩一点小花样:
>>> [[x, x**2] for x in vec]
[[2, 4], [4, 16], [6, 36]]
这里我们对序列里每一个元素逐个调用某方法:
>>> freshfruit = [' banana', ' loganberry ', 'passion fruit ']
>>> [weapon.strip() for weapon in freshfruit]
['banana', 'loganberry', 'passion fruit']
我们可以用 if 子句作为过滤器:
>>> [3*x for x in vec if x > 3]
[12, 18]
>>> [3*x for x in vec if x < 2]
[]
del 语句
使用 del 语句可以从一个列表中依索引而不是值来删除一个元素。这与使用 pop() 返回一个值不同。可以用 del 语句从列表中删除一个切割,或清空整个列表(我们以前介绍的方法是给该切割赋一个空列表)。例如:
>>> a = [-1, 1, 66.25, 333, 333, 1234.5]
>>> del a[0]
>>> a
[1, 66.25, 333, 333, 1234.5]
>>> del a[2:4]
>>> a
[1, 66.25, 1234.5]
>>> del a[:]
>>> a
[]
在序列中遍历时,索引位置和对应值可以使用 enumerate() 函数同时得到:
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe
同时遍历两个或更多的序列,可以使用 zip() 组合:
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
要反向遍历一个序列,首先指定这个序列,然后调用 reversed() 函数:
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
要按顺序遍历一个序列,使用 sorted() 函数返回一个已排序的序列,并不修改原值:
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。
元组写在小括号()里,元素之间用逗号隔开
tuple = ( 'abcd', 786 , 2.23, 'runoob', 70.2 )
tinytuple = (123, 'runoob')
print (tuple + tinytuple) # 连接元组
('abcd', 786, 2.23, 'runoob', 70.2, 123, 'runoob')
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含 0 个或 1 个元素的元组比较特殊,所以有一些额外的语法规则:
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
注意:
1、与字符串一样,元组的元素不能修改。
2、元组也可以被索引和切片,方法一样。
3、注意构造包含0或1个元素的元组的特殊语法规则。
4、元组也可以使用+操作符进行拼接。

#修改元组
元组中的元素值是不允许修改的,但我们可以对元组进行连接组合
tup1 = (12, 34.56);
tup2 = ('abc', 'xyz')
tup3 = tup1 + tup2;
print (tup3)
结果:
(12, 34.56, 'abc', 'xyz')
#删除元组
元组中的元素值是不允许删除的,但我们可以使用del语句来删除整个元组,如下实例:
tup = ('Google', 'Runoob', 1997, 2000)
del tup;
#tuple(seq)
将列表转换为元组。
>>> list1= ['Google', 'Taobao', 'Runoob', 'Baidu']
>>> tuple1=tuple(list1)
>>> tuple1
('Google', 'Taobao', 'Runoob', 'Baidu')
Set(集合)
集合(set)是一个无序不重复元素的序列。
基本功能是进行成员关系测试和删除重复元素。
可以使用大括号({})或者 set()函数创建集合
注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
student = ({'Tom', 'Jim', 'Mary', 'Tom', 'Jack', 'Rose'})
print(student) # 输出集合,重复的元素被自动去掉
# 成员测试
if('Rose' in student) :
print('Rose 在集合中')
else :
print('Rose 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a - b) # a和b的差集
print(a | b) # a和b的并集
print(a & b) # a和b的交集
print(a ^ b) # a和b中不同时存在的元素
Dictionary(字典)
列表是有序的对象结合,字典是无序的对象集合。两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用"{ }"标识,它是一个无序的键(key) : 值(value)对集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
创建空字典使用 { }
dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
在字典中遍历时,关键字和对应的值可以使用 items() 方法同时解读出来:
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
5、Linux/Unix系统中,你可以在脚本顶部添加以下命令让Python脚本可以像SHELL脚本一样可直接执行:
#! /usr/bin/env python3
然后修改脚本权限,使其有执行权限,命令如下:
$ chmod +x hello.py
执行以下命令:
./hello.py
注释
单行注释用#
多行注释用三个单引号(''')或者三个双引号(""")将注释括起来,例如:
#!/usr/bin/python3
'''
这是多行注释,用三个单引号
这是多行注释,用三个单引号
这是多行注释,用三个单引号
'''
print("Hello, World!")
6、运算符
算术运算符
假设变量a为10,变量b为21
%取模 - 返回除法的余数b % a 输出结果 1
**幂 - 返回x的y次幂a**b 为10的21次方
//取整除 - 返回商的整数部分
9//2 输出结果 4 , 9.0//2.0 输出结果 4.0
赋值运算符
%=取模赋值运算符c %= a 等效于 c = c % a
**=幂赋值运算符c **= a 等效于 c = c ** a
//=取整除赋值运算符c //= a 等效于 c = c // a
a = 21
c = 2
c %= a
print ("5 - c 的值为:", c)
c **= a
print ("6 - c 的值为:", c)
c //= a
print ("7 - c 的值为:", c)
5 - c 的值为: 2
6 - c 的值为: 2097152
7 - c 的值为: 99864
逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
运算符逻辑表达式描述实例
andx and y布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。(a and b) 返回 20。
orx or y布尔"或" - 如果 x 是 True,它返回 True,否则它返回 y 的计算值。(a or b) 返回 10。
notnot x布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。not(a and b) 返回 False
成员运算符
in如果在指定的序列中找到值返回 True,否则返回 False。x 在 y 序列中 , 如果 x 在 y 序列中返回 True。
not in如果在指定的序列中没有找到值返回 True,否则返回 False。x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。
a = 10
list = [1, 2, 3, 4, 5 ];
if ( a in list ):
print ("1 - 变量 a 在给定的列表中 list 中")
else:
print ("1 - 变量 a 不在给定的列表中 list 中")
身份运算符
身份运算符用于比较两个对象的存储单元
isis是判断两个标识符是不是引用自一个对象x is y, 如果 id(x) 等于 id(y) , is 返回结果 1
is notis not是判断两个标识符是不是引用自不同对象x is not y, 如果 id(x) 不等于 id(y). is not 返回结果 1
a = 20
b = 20
if ( a is b ):
print ("1 - a 和 b 有相同的标识")
else:
print ("1 - a 和 b 没有相同的标识")
7、条件控制
while 循环
while 循环使用 else 语句
在 while … else 在条件语句为 false 时执行 else 的语句块:
注意while后没有括号,但条件后有个冒号!
count = 0
while count < 5:
print (count, " 小于 5")
count = count + 1
else:
print (count, " 大于或等于 5")
结果如下:
0 小于 5
1 小于 5
2 小于 5
3 小于 5
4 小于 5
5 大于或等于 5
for循环
for in :
else:
break和continue语句及循环中的else子句
break 语句可以跳出 for 和 while 的循环体。
如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
pass 语句
Python pass是空语句,是为了保持程序结构的完整性。
pass 不做任何事情,一般用做占位语句,如下实例
for letter in 'Runoob':
if letter == 'o':
pass
print ('执行 pass 块')
print ('当前字母 :', letter)
print ("Good bye!")
当前字母 : R
当前字母 : u
当前字母 : n
执行 pass 块
当前字母 : o
执行 pass 块
当前字母 : o
当前字母 : b
Good bye!
8、 迭代器与生成器
迭代器
迭代是是访问集合元素的一种方式
迭代器有两个基本的方法:iter() 和 next()。
字符串,列表或元组对象都可用于创建迭代器:
>>> list=[1,2,3,4]
>>> it = iter(list) # 创建迭代器对象
>>> print (next(it)) # 输出迭代器的下一个元素
1
>>> print (next(it))
2
迭代器对象可以使用常规for语句进行遍历:
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
结果如下:
1 2 3 4
也可以使用 next() 函数:
import sys # 引入 sys 模块
list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
while True:
try:
print (next(it))
except StopIteration:
sys.exit()
执行以上程序,输出结果如下:
1
2
3
4
生成器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回yield的值。并在下一次执行 next()方法时从当前位置继续运行。
9、函数
def 函数名(参数列表):
函数体
注意后面有冒号!
参数
以下是调用函数时可使用的正式参数类型:
必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
关键字参数
通过为参数命名来为它们赋值——这叫做参数关键字—
我们使用名称(关键字)而不是位置(我们一直使用的)来指定函数的参数。
def func(a, b=5, c=10):
print('a为', a, '和b为', b, '和c为', c)
func(3, 7)
func(25, c=24)
func(c=50, a=100)
输出:
a为3 和b为7 和c为10
a为25 和b为5 和c为24
a为100 和b为5 和c为50
默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值:
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name);
print ("年龄: ", age);
return;
printinfo( age=50, name="runoob" );
print ("------------------------")
printinfo( name="runoob" );
名字: runoob
年龄: 50
------------------------
名字: runoob
年龄: 35
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
for var in vartuple:
print ("=======",var)
return;
# 调用printinfo 函数
#printinfo( 10 );
printinfo( 70, 60, 50 );
输出:
70
======= 60
======= 50
注意第一个参数!
匿名函数
python 使用 lambda 来创建匿名函数。即不再使用 def 语句这样标准的形式定义一个函数。
lambda 函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
sum = lambda arg1, arg2 : arg1 + arg2;
# 调用sum函数
print ("相加后的值为 : ", sum( 10, 20 ))
print ("相加后的值为 : ", sum( 20, 20 ))
相加后的值为 : 30
相加后的值为 : 40
10、模块
模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py。模块可以被别的程序引入,以使用该模块中的函数等功能。
import sys
import sys 引入 python 标准库中的 sys.py 模块;这是引入某一模块的方法。
sys.argv 是一个包含命令行参数的列表。
from…import 语句
from语句让你从模块中导入一个指定的部分到当前命名空间中
from…import * 语句
把一个模块的所有内容全都导入到当前的命名空间
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
if __name__ == '__main__':
print('程序自身在运行')
else:
print('我来自另一模块')
说明: 每个模块都有一个__name__属性,当其值是'__main__'时,表明该模块自身在运行,否则是被引入。
dir()函数
内置的函数 dir() 可以找到模块内定义的所有名称。以一个字符串列表的形式返回
dir(sys)
如果没有给定参数,那么 dir() 函数会罗列出当前定义的所有名称
包
包是一种管理 Python 模块命名空间的形式,采用"点模块名称"。
比如一个模块的名称是 A.B, 那么他表示一个包 A中的子模块 B 。
就好像使用模块的时候,你不用担心不同模块之间的全局变量相互影响一样,采用点模块名称这种形式也不用担心不同库之间的模块重名的情况。
在导入一个包的时候,Python 会根据 sys.path 中的目录来寻找这个包中包含的子目录。
目录只有包含一个叫做 __init__.py 的文件才会被认作是一个包,主要是为了避免一些滥俗的名字(比如叫做 string)不小心的影响搜索路径中的有效模块。
最简单的情况,放一个空的 :file:__init__.py就可以了。
用户可以每次只导入一个包里面的特定模块,比如:
import sound.effects.echo
这将会导入子模块:sound.effects.echo。 他必须使用全名去访问:
sound.effects.echo.echofilter(input, output, delay=0.7, atten=4)
还有一种导入子模块的方法是:
from sound.effects import echo
这同样会导入子模块: echo,并且他不需要那些冗长的前缀,所以他可以这样使用:
echo.echofilter(input, output, delay=0.7, atten=4)
还有一种变化就是直接导入一个函数或者变量:
from sound.effects.echo import echofilter
同样的,这种方法会导入子模块: echo,并且可以直接使用他的 echofilter() 函数:
echofilter(input, output, delay=0.7, atten=4)
注意当使用from package import item这种形式的时候,对应的item既可以是包里面的子模块(子包),或者包里面定义的其他名称,比如函数,类或者变量。
import语法会首先把item当作一个包定义的名称,如果没找到,再试图按照一个模块去导入。如果还没找到,恭喜,一个:exc:ImportError 异常被抛出了。
反之,如果使用形如import item.subitem.subsubitem这种导入形式,除了最后一项,都必须是包,而最后一项则可以是模块或者是包,但是不可以是类,函数或者变量的名字。
从一个包中导入*
导入语句遵循如下规则:
如果包定义文件 __init__.py 存在一个叫做 __all__ 的列表变量,那么在使用 from package import * 的时候就把这个列表中的所有名字作为包内容导入。
作为包的作者,可别忘了在更新包之后保证 __all__也更新了啊。
这里有一个例子,在:file:sounds/effects/__init__.py中包含如下代码:
__all__ = ["echo", "surround", "reverse"]
这表示当你使用from sound.effects import * 这种用法时,你只会导入包里面这三个子模块。
如果 __all__ 真的没有定义,那么使用from sound.effects import *这种语法的时候,就不会导入包 sound.effects 里的任何子模块。他只是把包sound.effects和它里面定义的所有内容导入进来(可能运行__init__.py里定义的初始化代码)。
11、
12、