云原生在京东丨ASF顶级分布式数据库中间件项目——Apache ShardingSphere



Apache ShardingSphere 定位为开源的分布式数据库中间件解决方案组成的生态圈,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,Apache ShardingSphere 目前阶段更加关注在原有基础上的增量,而非颠覆。

在聊起 Apache ShardingSphere 历史时,还要从它的前身—— Sharding-JDBC 开始。2015 年,现任 Apache ShardingSphere 项目 VP 的张亮和他的团队决定在 Java 的 JDBC 层植入代码,来达成开发成本最小化,自研开源的分布式数据库中间件项目 Sharding-JDBC。
在那之后,Sharding-JDBC 随着市场的需求不断更新,完成到ShardingSphere,再到 Apache ShardingSphere 的转变,产品本身也从分库分表的 Java 开发框架演化为了分布式数据库生态体系。
2016 年开始 Apache ShardingSphere 正式开源,不断升级开发新功能、重构稳定微内核,并于 2018 年 11 月进入 Apache 基金会孵化器。
2020 年4月16日,Apache ShardingSphere 正式从Apache 软件基金会(Apache Software Foundation,ASF)毕业,并成为 Apache 顶级项目(Top Level Project,TLP),这也是目前 ASF 首个分布式数据库中间件项目。
Apache ShardingSphere 从成为孵化器项目,到毕业成为顶级项目用时17个月。期间,完成了产品从分库分表中间件转变为了分布式数据库生态平台的升级。目前已在 gitHub 上收获 11000+ 关注度、140+ 公司落地的成功案例。社区运营方面,从孵化前的30+贡献者,到现在有超过130个贡献者。

Apache ShardingSphere 并不是一款产品的名称,它是一套开源的分布式数据库中间件解决方案组成的生态圈,由 JDBC、Proxy 和 Sidecar(规划中) 3 款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
Apache ShardingSphere 生态圈架构如下图所示:
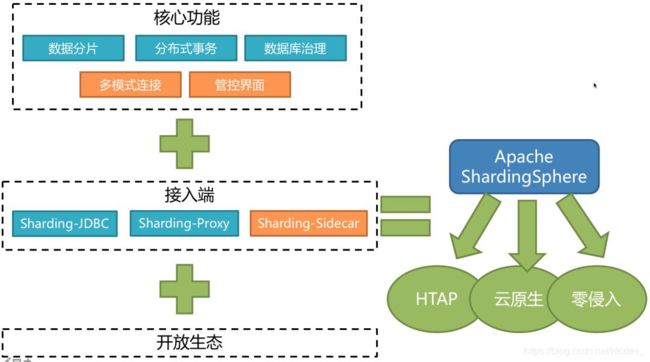
整体核心功能将组成一个闭环,它不仅为大家提供最为基础和核心的数据分片和分布式事务功能,同时针对以 ShardingSphere 为中心的整个分布式数据库系统,提供数据库治理的功能,例如配置信息动态统一管理、调用链与拓扑图、高可用管理、数据脱敏安全、权限控制等强大的管理功能。
此外,ShardingSphere 针对不同的数据库,例如 MySQL、Oracle、PostgreSQL、SQL Server 提供多模式连接的支持,真正屏蔽底层数据库选型的影响,做到无论使用何种数据库都可在用户无感知情况下进行数据分片、分布式事务、数据库治理的功能操作。
管控界面模块旨在为用户提供清晰可见的信息查看、配置更新管理、统计报表等功能。
在接入端部分,为了满足不同用户针对不同场景的需求,ShardingSphere 提供了多款接入端,包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(规划中):
Sharding-JDBC 是一款轻量级的 Java 框架,在 JDBC 层提供上述核心功能,使用方式与正常的 JDBC 方式如出一辙,面向 Java 开发的用户。
Sharding-Proxy 是一款实现了 MySQL 二进制协议的服务器端版本,大家可以把它当成升级版的 MySQL 数据库使用。独立部署后,即可按照正常 MySQL 操作方式来使用上述所有的核心功能。
Sharding-Sidecar 从 Service Mesh 的理念中应用而生,面向于云原生架构。
Apache ShardingSphere 是一个生态,它的开源基因注定它的发展开放自由、社区参与贡献。所以在设计它的架构时,会更加注意营造微内核与开发生态。
我们提供各个方面的开放接口,以方便所有对此感兴趣的朋友能参与其中,贡献代码,成为 Apache 基金会项目的提交者。
Github地址:
https://github.com/apache/shardingsphere

当前, ShardingSphere 已在京东落地很多大小业务,涉及到的业务场景复杂多样,这里只列举较为大型的系统,这些业务系统有的是重要程度较高,有的是业务较为新颖,如下图所示:
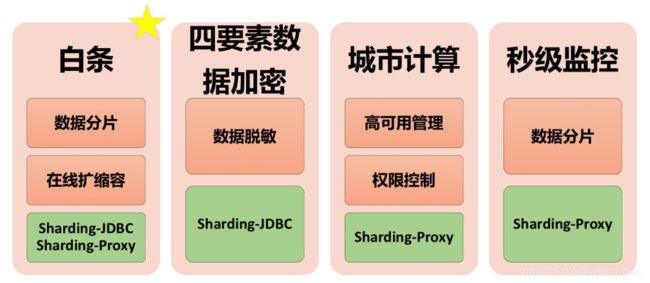
其中,京东白条是京东金融的杀手级应用。由于业务体量巨大,数据库不可避免地进行了水平拆分。拆分之后的数据节点规模达到了十万级别,是极度少见的金融级、高并发、海量数据并存的应用系统。为了追求性能极致以及代码的可控性,京东白条之前是在业务框架中,根据分片键替换数据库和表名称进行分片的。
随着业务的发展,通过业务框架进行分片的方式,使得代码的维护成本不断攀升。ShardingSphere 在经过了大量系统的验证之后,理所当然的成为了京东白条的数据分片中间件的首选方案,ShardingSphere 团队也非常愿意帮助京东白条团队解耦业务和底层技术代码,缓解开发工程师肩上的重担。
虽然 ShardingSphere 经历了大量系统的检验,项目已经相对成熟,但面对国内乃至世界上屈指可数的京东金融王牌级产品,仍将是一次严峻的考验。面对京东白条这个量级的应用,ShardingSphere 为了满足白条业务对 TPS/QPS 的强制要求,做了多方面优化,主要为:
SQL 解析结果缓存;
JDBC 元数据信息缓存;
Bind 表 & 广播表的使用;
自动化执行引擎 & 流式归并;
经过了一次次的优化与重构,现在 ShardingSphere 已经平稳地在白条生产环境运行,性能与原生 JDBC 几乎一致,GC 次数、资源消耗也未见异常。经历了京东白条的挑战,ShardingSphere 的稳定性也得到了进一步的提升。关注 ShardingSphere 的小伙伴们,你们对 ShardingSphere 更有兴趣了吗?
2020 年 7 月 30 日- 8月 1 日,2020 年Cloud Native + Open Source Virtual Summit China 中国峰会将首次以线上形式召开。作为 CNCF 云原生基金会白金会员,今年京东智联云将继续在大会中亮相,不仅带来多场精彩演讲,还将通过京东智联云云上展厅,近一步展示京东云原生技术动态与前沿技术。您可以来云上展厅更近一步了解 ShardingSphere 以及京东在云原生方面的技术实践。
参考资料:
https://www.oschina.net/question/4489239_2316036?sort=time
https://github.com/apache/shardingsphere/issues/650
点击"阅读原文",了解更多京东云原生之路
