Mybatis 二级缓存
Mybatis 二级缓存
- Mybatis一级缓存、二级缓存异同
- Mybatis缓存存储和淘汰策略
- 存储
- 缓存存储大致可以分为3大类:
- 内存
- 磁盘
- 第三方集成
- Mybatis存储方案
- 淘汰策略
- Mybatis缓存淘汰策略:
- 二级缓存结构
- 缓存类组装
- 执行链
- 缓存执行链创建
- 执行链展示
- 缓存核心组件解释
- PerpetualCache
- LoggingCache
- FifoCache
- LruCache
- LinkHashMap
- LruCache实现
- LruCache算法总结
- SoftCache
- WeakCache
- BlockingCache
- ScheduledCache
- SerializedCache
- SynchronizedCache
- TransactionalCacheManager
- TransactionalCache
- 总结
Mybatis一级缓存、二级缓存异同
前面我们分析了Mybatis一级缓存的一些特性,现在我们开始分析Mybatis的二级缓存。二级缓存设置思路很巧妙,看起来很难,只要你耐心看下去就会发现其实你也会开发。
| 缓存类型 | 命中 | 失效 | 作用域 | 跨线程使用 | 设计复杂度 | 淘汰策略 |
|---|---|---|---|---|---|---|
| 一级缓存 | 相同的statement id、相同的Session、相同的Sql与参数、返回行范围相同 | 执行update语句、手动清空、查询清空、提交,回滚清空 | SqlSession | 否 | 设计清晰,直接使用HashMap | 无 |
| 二级缓存 | 相同的statement id、会话提交后、相同的Sql与参数、返回行范围相同 | 配置flushCache=true查询刷新策略、在做commit有设置提交刷新策略 | 全局的 | 是 | 设置复杂,对缓存一系列策略做了处理。 | 有 |
从上述的图表中我们可以很清楚的看到一级缓存和二级缓存的区别。
下面我们来看下Mybatis一级缓存及二级缓存整个执行流程:
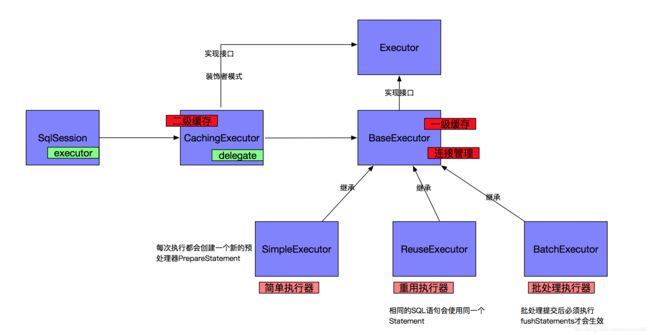
Mybatis缓存存储和淘汰策略
存储
缓存存储大致可以分为3大类:
内存
最简单就是在内存当中,不仅实现简单,而且速度快。内存弊端就是不能持久化,且容易有限。
磁盘
可以持久化,容量大。但访问速度不如内存,一般会结合内存一起使用。
第三方集成
第三方集成:在分布式情况,如果想和其它节点共享缓存,只能第三方软件进行集成。比如Redis.
Mybatis存储方案
Mybatis就是居于内存进行存储。
淘汰策略
淘汰策略是为了保证缓存能够持续高效的提供服务,防止因为存储内容太多导致内存被占满。每一种缓存有会有自己的淘汰策略,例如Redis就有6种淘汰策略。我们这里分析下常用淘汰策略。
Mybatis缓存淘汰策略:
FIFO:先进先出
LRU:最近最少使用
WeakReference: 弱引用,将缓存对象进行弱引用包装,当Java进行gc的时候,不论当前的内存空间是否足够,这个对象都会被回收。
SoftReference:软件引用,基机与弱引用类似,不同在于只有当空间不足时GC才才回收软引用对象。
二级缓存结构

从上图中我们可以看到Mybatis中Cache有很多实现,给我们提供了丰富的缓存操作。这里先对PerpetualCache进行分析,因为Mybatis二级缓存最终是存储在PerpetualCache中。
缓存类组装
在Mybatis缓存组装类中每一个功能都会对应一个组件类,并基于装饰者加责任链的模式,将各个组件进行串联。在执行缓存的基本功能时,其它的缓存逻辑会沿着这个责任链依次往下传递。接下来我先看源码(FifoCache为例),然后在运行是截图给大家分析。
// 这里提供了基本操作获取、移除、刷新、获取缓存数量
//我们可以很清楚的看到FifoCache有个属性delegate,
//Mybatis就是通过delegate来完成对缓存的装饰及缓存操作向下传递的过程。
//这个设置在Mybatis执行器Executor中也采用了这种设计。
public class FifoCache implements Cache {
private final Cache delegate;
private final Deque<Object> keyList;
private int size;
public FifoCache(Cache delegate) {
this.delegate = delegate;
this.keyList = new LinkedList<Object>();
this.size = 1024;
}
@Override
public String getId() {
return delegate.getId();
}
@Override
public int getSize() {
return delegate.getSize();
}
public void setSize(int size) {
this.size = size;
}
@Override
public void putObject(Object key, Object value) {
cycleKeyList(key);
delegate.putObject(key, value);
}
@Override
public Object getObject(Object key) {
return delegate.getObject(key);
}
@Override
public Object removeObject(Object key) {
return delegate.removeObject(key);
}
@Override
public void clear() {
delegate.clear();
keyList.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
private void cycleKeyList(Object key) {
keyList.addLast(key);
if (keyList.size() > size) {
Object oldestKey = keyList.removeFirst();
delegate.removeObject(oldestKey);
}
}
}
执行链
缓存执行链创建
在Mybatis在启动加载启动解析XMLMapper文件时,会解析XMLMapper的Namespace对应的Mapper文件是创建。这样讲可能很多人会比较迷糊,下面我们直接上时序图。
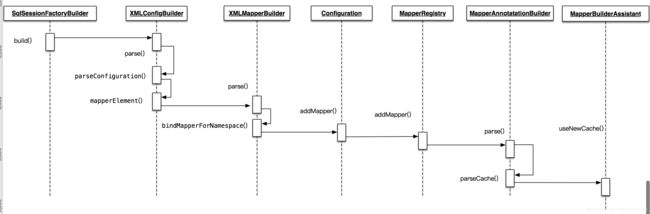
整个调用链路非常长,需要自己断点调试去看源码。这里分享个人看源码的一个小技巧,直接断点打到需要源码的地方,Debugger模式启动程序,接口来看堆栈信息可以直接点到整个调用过程。下面给大家看下调用栈信息:

接下来我们来看下Mybatis二级缓存执行链路创建核心源码。
// An highlighted block
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
//创建Cache并设置Namespace我本地的Namespace为
//com.wwl.mybatis.dao.UserMapper
Cache cache = new CacheBuilder(currentNamespace)
//设置PerpetualCache,这个Cache实现Mybatis底层存储
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
//设置缓存淘汰策略,使用最近最少使用策略
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
//缓存是否刷新
.clearInterval(flushInterval)
//缓存大小
.size(size)
//是否序列化
.readWrite(readWrite)
//是否启用BlockingCache
.blocking(blocking)
.properties(props)
.build();
//把创建好的缓存对象关联到configuration中,
//configuration的生命周期和Mybatis程序生命周期是一致
//的,从这里我们也可以看出Mybatis二级缓存的生命。
configuration.addCache(cache);
currentCache = cache;
return cache;
}
至此我们已经分析完了Mybatis缓存执行链的创建过程。
执行链展示
现在先看看Mybatis整个执行链路的情况,接下来我们看下整个链路展示。

我们可以很清楚的看到每一个Cache里面都有一个属性叫delegate,而这个delegate就是个Cache,外层的Cache都是对delegate的一个修饰,组成一个链路,链路的末端为PerpetualCache,PerpetualCache实现了Mybatis二级缓存的存储。
缓存核心组件解释
咋一看Mybatis二级缓存好复杂,实现了线程安全、淘汰策略、序列化等一系列的牛逼操作,那我们来分析一下,分析完了你也可以做到这么牛逼。接下来我们会由浅入深的带大家去看下Mybatis二级缓存核心组件。
PerpetualCache
Mybatis最终存储缓存是在PerpetualCache里面完成,其实Mybaits二级缓存和一级缓存存储都是用HashMap来实现的。是不是很惊讶,没错,就是HashMap。接下来我们来上源码。
// 这里提供了Mybatis二级缓存的最终存储,很多人可能会有疑问,Mybatis二级缓存不是跨线程的吗?
//直接使用HashMap能保证线程安全吗?别急,后面会给大家分析。
//这里简单看下PerpetualCache提供了缓存的基本操作。
//对于缓存的获取、移除、刷新、获取缓存数量都是对HashMap的操作,这个相对简单不做过多分析。
public class PerpetualCache implements Cache {
private final String id;
//Mybatis二级缓存就存储在这个HashMap中,好像也没有想象中那么神秘。
private Map<Object, Object> cache = new HashMap<Object, Object>();
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
return null;
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
LoggingCache
缓存日志操作,如果开启打印日志,在获取缓存的时候打印出缓存的id及缓存的命中率。这个类里面就getObject做了一些处理逻辑,其他都是调用delegate交给别的缓存处理器去处理。
接下来我们来看看源码。
首先在LoggingCache中有2个属性requests、hits。
// 请求查询的其次
protected int requests = 0;
//命中缓存的次数
protected int hits = 0;
再看看getObject方法。
// 这打印了日志及缓存的命中率计算逻辑
@Override
public Object getObject(Object key) {
//每查询一次都+1
requests++;
final Object value = delegate.getObject(key);
if (value != null) {
//如果命中缓存,则命中次数+1
hits++;
}
if (log.isDebugEnabled()) {
//打印缓存Id及命中率其中getHitRatio()是命中率方法。
log.debug("Cache Hit Ratio [" + getId() + "]: " + getHitRatio());
}
return value;
}
我们看下命中率的算法
// 哈哈,原来牛逼的命中率算法就是:命中次数/查询总数,好像很简单耶。
private double getHitRatio() {
return (double) hits / (double) requests;
}
FifoCache
先进先出淘汰策略,这个缓存淘汰策略和上面LoggingCache一样简单。我们就分析设置缓存和缓存清楚方法,其他方法都是通过delegate委托给下个缓存组件实现。
FifoCache有2个属性,一个是队列Deque、一个是size。
// 这个用来存储缓存Key的队列
private final Deque<Object> keyList;
//缓存的大小,默认为1024
private int size;
我们再看看设置缓存的方法
// 设置缓存方法
@Override
public void putObject(Object key, Object value) {
//设置缓存key
cycleKeyList(key);
//具体的put操作委托给其他的缓存装饰器执行
delegate.putObject(key, value);
}
// 缓存key的核心操作
private void cycleKeyList(Object key) {
//把Key添加到队列中
keyList.addLast(key);
//判断队列中的key是否超过阈值
if (keyList.size() > size) {
//超过阈值直接清除队列的投元素
Object oldestKey = keyList.removeFirst();
//委托给其他缓存装饰器执行移除操作,看到这里是不是发现这个缓存淘汰策略好简单啊。
//这个以后也可以运用到我们工作中,其实就是这么简单
delegate.removeObject(oldestKey);
}
}
// 缓存的清除操作也同样简单
public void clear() {
//委托其他缓存装饰器去执行清除操作
delegate.clear();
//清除keyList
keyList.clear();
}
看完源码了是不是发现自己也会实现先进先出的淘汰策略。
LruCache
Mybatis的Lru算法是居于LinkHashMap的Lru算法来实现的。这里先介绍下LinkHashMap。
LinkHashMap
LinkHashMap维护了个双向链表,这个链表维护插入的顺序。同时还提供了个属性accessOrder,accessOrder为true则实现Lru算法顺序,否则按照插入顺序。
// 列表的头节点
transient LinkedHashMap.Entry<K,V> head;
//列表的为节点
transient LinkedHashMap.Entry<K,V> tail;
//为true是则实现Lru顺序,否则为插入顺序
final boolean accessOrder;
那LinkhashMap是如何实现插入顺序和lru算法的呢?在HashMap中提供了3个空方法给子类实现他们分别是afterNodeAccess、afterNodeInsertion、afterNodeRemoval。这个3个方法正是LinkHashMap实现了节点的顺序算法和Lru算法的核心。这个3个方法大致介绍调用场景,具体代码自己去看下。
// 在往HashMap中put值的时候,如果当前key存在的情况下会调用此方法。
void afterNodeAccess(Node<K,V> p) { }
//在往HashMap中put值的时候,如果当前key不存在的情况下会调用此方法。
void afterNodeInsertion(boolean evict) { }
//在粗发removeNode方法时候会调用此方法。
void afterNodeRemoval(Node<K,V> p) { }
LinkHashMap除了对这3个方法进行了实现还提供了个空方法removeEldestEntry。
// 这个方法默认返回false,如果返回true则会删除掉对应的节点。
//在LruCache中创建的LinkHashMap就会根据缓存容量来做判断。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
// An highlighted block
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
afterNodeInsertion 方法根据removeEldestEntry方法返回值来判断是否需要移除元素,如果为true,则移除列表的投元素。
// An highlighted block
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
现在研究下afterNodeAccess方法,这个方法判断当前的是否采用Lru算法,如果为true,则采用Lru算法。
// 主要逻辑就是如果采用了Lru算法,把节点放到队列的尾部
// 里面的细节自己去看下就明白了
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeRemoval 方法就是移除列表中的元素
// An highlighted block
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
我们在看看LinkHashMap的get方法
// An highlighted block
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
//如果是Lru算法,则把当前节点方法放到队列的尾部
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
LruCache实现
前面对HashMap、LinkHashMap做了这里多的分析和解释,现在我们的主角要登场了。
首先我们看看LruCache创建LinkHashMap时候做了些什么事情。
// 创建LinkHashMap并设置先关属性,并重写removeEldestEntry方法。
public void setSize(final int size) {
//我们可以看到构造方法的最后一个参数为true,true就是采用Lru算法
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
//重写了removeEldestEntry方法,这个里面对是否移除做了判断
//这里我们需要对eldest这个值解释下,在HashMap做Put方法时候调用LinkHashMap的
//afterNodeInsertion方法时候传入的头结点。就是我们上面分析的afterNodeInsertion
//方法里面调用了改方法。
@Override
protected boolean removeEldestEntry(Map.Entry<Object, Object> eldest) {
//判断当前的容量是否超过缓存的容量,如果超过了就返回true,并保存当前的Key值。
boolean tooBig = size() > size;
if (tooBig) {
//获取头节点的key值,方便后面做缓存删除
eldestKey = eldest.getKey();
}
return tooBig;
}
};
}
现在我们来看下缓存获取的方法。
// 获取缓存的方法很简单,一看就2行代码,正是第一行这不起眼的代码里面暗藏着玄机。
public Object getObject(Object key) {
//调用LinkHashMap的get方法,在LinkHashMap的get方法里会把当前节点放到队列的尾部。
keyMap.get(key); //touch
return delegate.getObject(key);
}
接下来我们看看LruCache的put方法
// 在put方法中先调用缓存装饰器来时间缓存的保存,然后调用cycleKeyList方法
public void putObject(Object key, Object value) {
delegate.putObject(key, value);
cycleKeyList(key);
}
private void cycleKeyList(Object key) {
//同样这里也是暗藏杀机,这个put方法主要实现了2块逻辑
//1.如果key存在,则会把当前key对应的则放到LinkHashMap的尾部
//2.如果key不存在,把元素放入队列尾部,判断容量是否满,如果满了直接移除队列的头结点
keyMap.put(key, key);
if (eldestKey != null) {
delegate.removeObject(eldestKey);
eldestKey = null;
}
}
接下来的clear和removeObject方法就相对简单些,这里就不赘述啦。Mybatis二级缓存Lru算法理解了不难,这里做个小总结。
LruCache算法总结
Mybatis二级缓存的Lru算法是居于LinkHashMap的Lru算法来实现的,只需要研究下LinkHashMap的Lru算法就可以很好理解。前面也对HashMap、LinkHashMap做了写分析,相信很多朋友看到这都会比较模糊,非常正常,因为我写的不太清楚,但是大家在看看源码其实很好理解。Lru这块也是二级缓存中比较难理解的。
SoftCache
SoftCache也是Mybatis缓存淘汰策略的一种,在分析SoftCache之前我们先回顾一下java的=软引用的特性。
软引用是用来描述一些还有用但并非必须的对象。对于软引用关联着的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围进行第二次回收。如果这次回收还没有足够的内存,才会抛出内存溢出异常。
从上面定义我们可以猜到SoftCache的作用了吧。只有在快要发生内存溢出的时候才会对缓存进行清理。
接下来我们分析下WeakReference的一个特性,下面我们看下这个构造方法。
// ReferenceQueue 在GC回收对象时,对象的包装类会被放入队列。其实弱引用也有这个特性
public WeakReference(T referent, ReferenceQueue<? super T> q) {
super(referent, q);
}
至于其他的一些属性大家自己去分析。
WeakCache
WeakCache和SoftCache实质是一样,差异就在于GC对软引用和弱引用的差异性回收机制。大家自己去了解下就ok啦。
BlockingCache
很多博友把BlockingCache叫阻塞缓存,其实我个人理解这个应该不是为了阻塞。BlockingCache存在的意义是为了防止缓存穿透。这个缓存装饰器相比LruCache来讲要简单些。
我们主要分析putObject、getObject、acquireLock、releaseLock这四个方法和locks属性。
先对locks进行解释下。
// 很熟悉吧,ConcurrentHashMap,并发安全的HashMap,key是当前缓存对应的key值,
//value就是ReentrantLock,这里就是为了保证线程安全。
private final ConcurrentHashMap<Object, ReentrantLock> locks;
对锁进行释放
// 根据当前的key来获取
private void releaseLock(Object key) {
//通过缓存key获取到锁
ReentrantLock lock = locks.get(key);
//判断持有锁的线程和当前执行线程是否为同一线程,如果是直接释放锁资源。
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
acquireLock 分析
private void acquireLock(Object key) {
//获取锁
Lock lock = getLockForKey(key);
//如果设置了超时时间,则通过tryLock来获取锁,获取锁失败直接异常
if (timeout > 0) {
try {
boolean acquired = lock.tryLock(timeout, TimeUnit.MILLISECONDS);
if (!acquired) {
throw new CacheException("Couldn't get a lock in " + timeout + " for the key " + key + " at the cache " + delegate.getId());
}
} catch (InterruptedException e) {
throw new CacheException("Got interrupted while trying to acquire lock for key " + key, e);
}
} else {
//直接获取锁,这里面很多juc的知识,如果对这块不太了解的可以看看juc
lock.lock();
}
}
获取缓存方法
// 获取缓存方法比较核心下面会慢慢解释
public Object getObject(Object key) {
//获取缓存锁
acquireLock(key);
//委托给其他缓存装饰器去获取缓存
Object value = delegate.getObject(key);
//获取到数据,直接解锁,否则一直阻塞在这里,这就是防止缓存击穿的的很新逻辑。
//我们知道Mybatis在查询二级缓存的时候查询不到数据会去一级缓存中找数据。
//如果一级缓存也没有数据则会去数据库中进行查询,然后把数据数据。
//查完数据库会把数据put到缓存中去。接下来我们看看put方法做了什么逻辑。
if (value != null) {
releaseLock(key);
}
return value;
}
缓存的put方法
// An highlighted block
public void putObject(Object key, Object value) {
try {
//委托给其他的缓存装饰器去做缓存的保存。
delegate.putObject(key, value);
} finally {
//刚才我们上面已经看过get方法了,在get方法中如果没有缓存数据会被阻塞,
//在这方法里面会释放get时候的锁,并且唤醒其他线程来执行相关的操作。(这里涉及到并发编程JUC下面lock的)
releaseLock(key);
}
}
这里对BlockingCache就分析到这里,其他方法自己看下,很简单。
ScheduledCache
ScheduledCache是Mybatis定时清理缓存功能的装饰器,他主要实现定时清理缓存。ScheduledCache是定定时清理缓存是一种惰性清理方式,只有对缓存进行操作的时候才会去判断缓存是否超过过期时间,如果超过过期时间直接清理。ScheduledCache有3个属性,缓存装饰器、上去清理世界、缓存过期时间。接下来看源码。
//缓存装饰器
private final Cache delegate;
//缓存过期时间
protected long clearInterval;
//上一次缓存清理时间
protected long lastClear;
定时缓存清理主要实现逻辑是在put、get、removeObject操作调用缓存清理机制,接下来我们removeObject是如何实现的。
private boolean clearWhenStale() {
//系统时间 - 上次缓存清理时间 > 缓存定时清理时间则进行清理。
if (System.currentTimeMillis() - lastClear > clearInterval) {
clear();
return true;
}
return false;
}
接下来我们看看clear()方法。
public void clear() {
//设置当前缓存清理时间
lastClear = System.currentTimeMillis();
//调用缓存装饰器执行缓存的清理
delegate.clear();
}
SerializedCache
Mybatis一级缓存是没有序列化操作,二级缓存却要序列换操作,为什么呢?我们都知道序列化是需要时间的,那Mybatis为什么还要牺牲性能去序列化呢 ?那为什么一级缓存不做序列化操作呢?接下来带着这些疑问我们来分析一下一级缓存和二级缓存的一些差异性。
| 缓存类型 | 作用域 | 跨线程使用 | 序列化 |
|---|---|---|---|
| 一级缓存 | SQLSession | 否 | 不系列化 |
| 二级缓存 | 全局 | 是 | 是(可以通过设计来关闭) |
通过上图我们可以很清晰的看到,一级缓存的作用域是SqlSession,其实可以简单理解为单线程使用,故不会出现多线性来共享资源问题,当前线程中有对获取的缓存对象进行修改任何信息线程都是有感知的。所以没有问题。然而二级缓存是全局的、跨线程使用的。那问题来了,如果不做序列化操作,A线程获取到缓存并对缓存进行修改是,B线程来获取缓存就是A修改后的值,显然不是线程安全的,为了保证B线程拿到的缓存和A刚开始拿的缓存数据是一致的,所以多缓存进行了序列化操作。
Mybatis也提供了配置,关闭序列化缓存装饰器。关闭缓存序列化装饰器就可能存在数据不一致的情况,这要结合实际项目中的场景来使用。对时间和安全做个平衡。
SerializedCache缓存装饰器就是在putObject时候进行序列化操作,在getObject进行反序列化操作。
SerializedCache序列化和反序列化就是调用JDK的序列化和反序列化操作。其他代码相对简单大家自己瞄一眼就好。
// 序列化
private byte[] serialize(Serializable value) {
try {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(value);
oos.flush();
oos.close();
return bos.toByteArray();
} catch (Exception e) {
throw new CacheException("Error serializing object. Cause: " + e, e);
}
}
//反序列化
private Serializable deserialize(byte[] value) {
Serializable result;
try {
ByteArrayInputStream bis = new ByteArrayInputStream(value);
ObjectInputStream ois = new CustomObjectInputStream(bis);
result = (Serializable) ois.readObject();
ois.close();
} catch (Exception e) {
throw new CacheException("Error deserializing object. Cause: " + e, e);
}
return result;
}
SynchronizedCache
SynchronizedCache线程安全缓存装饰器,这个缓存装饰器就更简单,直接在缓存操作的方法上加上synchronized关键字。我们简单过一个方法,其他方法自己去看。
// 在getSize()方法上直接加上同步关键字,就是这么简单。
public synchronized int getSize() {
return delegate.getSize();
}
TransactionalCacheManager
在创建CachingExecutor的时候会初始化一个TransactionalCacheManager,所以TransactionalCacheManager的生命周期和执行器的生命周期是一致的。TransactionalCacheManager就是用来管理事物缓存的。CachingExecutor对缓存的操作都是交由TransactionalCacheManager来完成的。下面我来看看TransactionalCacheManager这个类。
// 事物缓存管理类
public class TransactionalCacheManager {
//保存这事物开启之后所有操作过的缓存信息。
//key为缓存,value为事物缓存装饰器TransactionalCache
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
TransactionalCache txCache = transactionalCaches.get(cache);
if (txCache == null) {
txCache = new TransactionalCache(cache);
transactionalCaches.put(cache, txCache);
}
return txCache;
}
}
我们可以很清楚的看到事物缓存管理类就是根据缓存来获取事物缓存装饰器对缓存进行操作,所有对缓存操作都是交给TransactionalCache来处理。
TransactionalCache
前面我们对事物缓存管理类进行了分析,现在我们来看事物缓存装饰器。这2个类的名字很像。大家注意区分。
这里先给大家看下Mybatis事物缓存装饰器的暂存区、和缓存区的区别,只有了解了这2块的区别才可以更好的分析下面的代码逻辑。

上图中黄色代表暂存区、红色代表二级缓存区、浅绿色代码具体缓存数据。从上图中我们可以得知。
1.所有的查询都是从二级缓存查询。
2.查询出来的缓存数据都是放在会话的暂存区。
3.事物会话中所有多缓存put、remove操作都是操作暂存区。
4.当事物提交或回滚会把暂存区的数据同步到二级缓存。
5.暂存区和会话生命周期一致。
居于上面的几点,我们现在来分析一下源码。先看看TransactionalCache的几个属性。
// 缓存装饰器
private final Cache delegate;
//提交时候是否清楚二级缓存的标记,如果设置了MappedStatement设置了flushCache为true,每次查询都会清空缓存。
private boolean clearOnCommit;
//所有的对缓存操作都暂存在这里,如果事物提交,则把暂存区的数据写入到二级缓存中,如果发生事物回滚
private final Map<Object, Object> entriesToAddOnCommit;
//存放未命中缓存的数据。
private final Set<Object> entriesMissedInCache;
下面我们对TransactionalCache里面的方法进行分析(一定要看懂上面图的含义)。我先分析个简单方法。removeObject方法。
// 初一看,诶奇怪,之前看到谁有的缓存装饰器都实现了这个removeObject方法来删除缓存元素,这里为什么没有呢?
//博主个人分析有原因有2
//1.removeObject是为了提供缓存过期是对过期缓存进行删除操作的,TransactionalCache不是缓存淘汰装饰器
//2.TransactionalCache作为最外层的缓存装饰器,只给TransactionalCacheManager,不会被任何缓存装饰器装饰。
public Object removeObject(Object key) {
return null;
}
// clear操作没用对缓存进行实质性的删除,只是设置了clearOnCommit=true,并清除entriesToAddOnCommit暂存去的所暂存信息。
//注意看这里并没有对实际的二级缓存进行清除。clearOnCommit标记在后续的getObject操作中会使用此标记。
//该方法是听过CachingExecutor的flushCacheIfRequired方法来触发的。
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
// 缓存获取操作
public Object getObject(Object key) {
// 通过缓存装饰器获取缓存
Object object = delegate.getObject(key);
//如果没有获取到缓存直接丢到未命中列表
if (object == null) {
entriesMissedInCache.add(key);
}
// 如果当前缓存已经是提交清除操作,直接返回null,至于clearOnCommit标记上面已经介绍了。
//如果当前缓存是刷新操作,直接返回Null。
if (clearOnCommit) {
return null;
} else {
return object;
}
}
// putObject只是把缓存数据放入到暂存去,并没有交给缓存装饰器进行存储。那是为什么呢?我们想下,
//如果我们提交到缓存中,其他线程就可以访问到这个数据,如果此时发生了数据回滚操作,其他线程读到的数据
//就变成了脏数据,会产生脏读。
public void putObject(Object key, Object object) {
entriesToAddOnCommit.put(key, object);
}
// 提交方法
public void commit() {
//判断是否需要做提交刷新操作
if (clearOnCommit) {
//刷新二级缓存
delegate.clear();
}
//1.把暂存区的数据提交到缓存中
//2.把未命中的数据也提交到缓存中value为null
flushPendingEntries();
//重置数据状态
reset();
}
``````javascript
// 回滚
public void rollback() {
//清除未命中的的数据,并把未命中的数据设置缓存为null
unlockMissedEntries();
//重置所有的参数
reset();
}
// 这里就是把暂存区的数据提交到缓存
private void flushPendingEntries() {
//喜欢暂存区,把暂存区的数据同步到缓存区
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValu());
}
//循环所有的未命中的缓存key,设置缓存为null
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
// 把未命中的缓存的key刷新到缓存中,value为null
private void unlockMissedEntries() {
for (Object entry : entriesMissedInCache) {
try {
delegate.removeObject(entry);
} catch (Exception e) {
log.warn("Unexpected exception while notifiying a rollback to the cache adapter."
+ "Consider upgrading your cache adapter to the latest version. Cause: " + e);
}
}
}
总结
Mybatis二级缓存体系相对比较复杂,里面涉及的知识点很多。大家可以自己根据上文慢慢体会。