elasticsearch搜索服务各组件kibana、xpack、dataX等搭建全过程
一、效果预览

二、 资源分配及集群角色分配:尽量负载均衡
| 1xx.xx.xxxxx |
node1 (data+master角色) dataX crontab任务 |
| 1xx.xx.xxxxx |
node2 (data+master角色) kibana(开发运维web工具) |
| 1xx.xx.xxxxx |
node4 (data+master角色) node3(ingest角色) |
| 1xx.xx.xxxxx |
node5 (data+master角色) node6(ingest角色) |
三、软件准备
JDK8:http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz
elasticsearch-6.2.4:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.4.tar.gz
kibana:https://www.elastic.co/downloads/past-releases/kibana-6-2-4
dataX:https://github.com/alibaba/DataX
xpack:https://artifacts.elastic.co/downloads/packs/x-pack/x-pack-6.2.4.zip
pinyin分词器:https://github.com/medcl/elasticsearch-analysis-pinyin
ik分词器:https://github.com/medcl/elasticsearch-analysis-ik
四、各组件安装
4.1、JDK8安装:JDK8安装(略,网上到处可找到),然后配置环境vi /etc/profile ,最后source /etc/profile生效。profile增加内容:
export JAVA_HOME=/usr/local/apps/jdk1.8.0_141
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
也可不设置JDK环境变量,但需要
在ES的启动脚本bin/elasticsearch中指定JDK环境:
export JAVA_HOME=/opt/jdk1.8.0_181
export JRE_HOME=/opt/jdk1.8.0_181/jre/
4.2、ES单机版安装(安装到~/es目录下)
4.2.1 解压:tar -zxvf elasticsearch-6.2.4.tar.gz
4.2.2 移动到~/es目录下并重命名 :mv elasticsearch-6.2.4 ~/es/elasticsearch-node1
递归修改文件夹所有者:chown elasticseatch:elasticsearch es -R
4.2.3 bin目录下前台启动:./elasticsearch,后台启动 ./elasticsearch -d
4.2.4 简单测试:curl localhost:9200
注意:如果是全新机器安装启动可能会有以下几个坑:

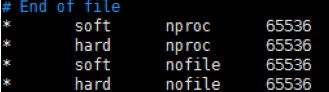
错误1:解决 vi /etc/security/limits.conf , shift+g在最后的两个配置soft nofile 与hard nofile 值修改到65536以上,(重启SSH服务,或重启主机生效systemctl restart sshd.service),* 号最好精确到具体系统用户
错误2:vi /etc/sysctl.conf 再末尾增加配置 vm.max_map_count=262144 或更高,并执行sysctl -p
错误3:centos7 不会报该错,centos6报错或报警告,需要elasticsearch.yml中配置bootstrap.system_call_filter=false,参考:https://blog.csdn.net/liangzhao_jay/article/details/56840941
4.3、ES集群安装
修改单机版node1节点的配置:vi ~/es/elasticsearch-node1/config/elasticsearch.yml
(注意:yml配置文件每个key的value前必有一个空格),修改后的配置文件如下:
查看去注释后的配置:grep '^[a-z]' ~/es/elasticsearch-node1/config/elasticsearch.yml 或egrep '^#' ~/xxx.yml
******************************************************************************************
Node1:date+master节点
******************************************************************************************
cluster.name: emall_search #集群名
node.name: node-1 #节点名
node.master: true #有成为master资格
node.data: true #为数据节点
node.ingest: false #非数据预处理节点
bootstrap.memory_lock: false #禁止锁定内存
bootstrap.system_call_filter: false #禁用系统调用过滤器
network.host: 1XX.XX.XX.X93 #绑定本节点网络地址本机IP
http.port: 9200 #http访问端口
discovery.zen.ping.unicast.hosts: ["1XX.XX.XX.X93:9300","1XX.XX.XX.X94:9300","1XX.XX.XX.X95:9300", "1XX.XX.XX.X92:9300","1XX.XX.XX.X95:9301","1XX.XX.XX.X92:9301"] #所有节点通讯列表
discovery.zen.minimum_master_nodes: 2 #至少2个master资格节点存活才选主
discovery.zen.fd.ping_timeout: 200s #集群心跳检查超时时间
discovery.zen.fd.ping_interval: 30s #集群心跳检查周期
discovery.zen.fd.ping_retries: 5 #集群心跳检查重试次数
transport.tcp.port: 9300 # 集群内部通讯端口
transport.tcp.compress: true #开启TCP数据压缩压缩传输
http.cors.enabled: true #开启跨域请求
http.cors.allow-origin: "*" #允许所有来源的跨域请求
******************************************************************************************
重启node1,可能报错如下,进入报错中的目录删除之前单机启动生成的一些数据即可

再次启动会根据配置的集群通信端口9300进行心跳检查,这时发现只有一个自己一个master节点,但配置的是discovery.zen.minimum_master_nodes: 2,需要两个master节点才进行选主。(并不是配置文件中配的node.master: true 就是master,只是有成为master的资格)

整体copy整个node1 5份,按node1的配置及(二、 资源分配及集群角色分配:尽量负载均衡)配置即可,只需要修改node1配置文件中红字部分。然后启动这5个节点。
检查集群健康状态:curl -XGET -i http://1XX.XX.XX.X93:9200/_cat/health?v
检查节点分配情况: curl -i -XGET 1XX.XX.XX.X93:9200/_cat/nodes
*表主节点,md表示节点角色为master+data,i表示角色ingest

到这里其实集群已经安装好了,下面安装其它组件
4.4 安装插件x-pack(不关闭集群),还是先在node1安装,6.3+版本的es默认集成xpack,不用单独下载。
可以自己去官网下载一个x-pack-6.2.4.zip ,破解参考https://www.cnblogs.com/wajika/p/9010032.html
破解(只是做好破解准备工作)。完后进行xpaxk安装与破解:分别到node1~node6的bin目录下执行安装命令(file://+xpack的绝对路径) ./elasticsearch-plugin install file:///home/es/x-pack-6.2.4.zip;在线安装
./elasticsearch-plugin install https://artifacts.elastic.co/downloads/packs/x-pack/x-pack-6.2.2.zip ;将之前的elasticsearch安装目录下的plugins config bin 三个目录copy到新的elasticsearch也是可以的
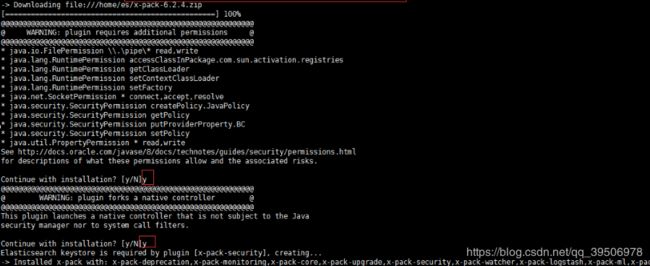
重启使用节点,看到如下加载xpack插件

启动node1会报错缺失认证token,这时检查集群健康也会报这个错
![]()
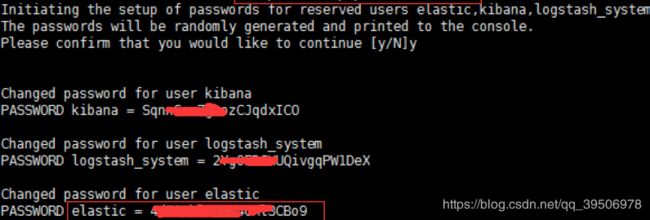
到node1的bin下执行xpack的一个命令来生成认证token,执行./x-pack/setup-passwords auto,会生成三个账号和密码(ELK)。Elastic即ES的 密码是 4XXXXXXXXo9(重要!)
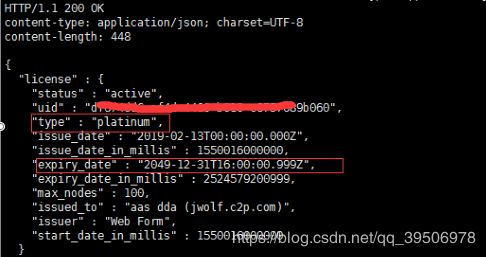
接下来破解要用到这个密码。首先需要申请一个证书https://license.elastic.co/registration。然后会在申请证书填的邮箱收到一个邮件,到邮件连接去下载下来这个证书。将许可证改一下名,如license.json,将json里的如下两项修改一下,即修改许可证有效期①"type":"platinum" ②"expiry_date_in_millis":2524579200999。然后放到一个目录如~/es/ ,然后到这个目录下执行请求curl -XPUT -u elastic:6esDhSTr8lINSgjaliQf 'http://localhost:9200/_xpack/license' -H "Content-Type: application/json" -d @license.json 这就算破解好node1了,其它几个节点同理安装好xpack也执行一个curl请求来进行破解,如下可以用几十年了。如果不破解只能用1个月,到期后xpack监控功能会被禁用。但不影响一般的业务搜索。也可以kibana界面进行许可破解更新。
curl -i -XGET -H "Content-Type: application/json" -u elastic:4XXXXo9 'http://1xx.xx.xx167:9200/_xpack/license' -d @license.json
4.5、Xpack其它配置。参考https://blog.csdn.net/wfs1994/article/details/80411047,最后在elasticsearch.yml配置ssl相关配置。重启再次访问集群健康、节点分配,能正常访问即可。transportClient或elasticsearchTemplate访问配置了账户密码及SSL的ES集群需要配置账户密码及SSL=》https://mp.csdn.net/postedit/88653138

4.6、IK及拼音分词器:直接将解压后拼音及IK分词器copy到ES每个节点的plugin目录里,重启就会自动加载
4.7 、同步组件dataX。github下载https://github.com/alibaba/DataX ,700M+,解压后达1G,可以删除其不必要的redear/writer相关组件,如图只保留了mysqlreader及eswriter,整个解压后包就30M左右了。dataX同步脚本怎么写可以github或csdn查看相关文章,注意SQL语句的field与映射到ES的field要顺序要一一对应。写好后的同步脚本都放在dataX的job目录中,进入bin目录执行python datax.py ../job/XX.json 就可以进行同步了,一个索引一般有两套脚本,一条手动执行的全量同步脚本,另一套是增量同步脚本,跟全量同步脚本不同的是脚本中的SQL语句where条件有限制,只查询一定时间内有改动的MySQL的数据行(可根据设置有自动更新的update_time),然后用crontab 来定时执行这个脚本。
4.8、集群操作与可视化工具kibana安装:解压修改配置启动即可,前台启动./kibana ,后台启动使用通用的nohup ./kibana &,关闭方式fuser -n tcp 5601 或netstat -anp |grep 5601 找出进程kill掉或其它方式。
可以下载Kibana_Hanization-master.zip 解压后的old下汉化命令 python main.py kibanan目录,7.X版本在kibana.yml配置一下就可以汉化
*************************************************************************************************************
vi config/kibana.yml,主要配置一下kibana服务host、port及要连接的ES账号密码及URL。
server.host: "1XX.XX.XX.X94"
server.port: 5601
elasticsearch.url: "http://1XX.XX.XX.X94:9200"
elasticsearch.username: "elastic"
elasticsearch.password: "4XXXXXXXXXo9"

浏览器访问kibana的ip:port,,输入用户名elastic,密码4XXXXXXXXXo9 ,如有网络隔离需要配置nginx转发,
是kibana请求 _cat/nodes与命令curl -i -u elastic:4XXXXXXXXXo9 -XGET 1XX.XX.XX.X93:9200/_cat/nodes等效的,方便很多,关键是还有不错的代码提示。kibana的图表、仪表盘做的也挺好看。

4.9 beat+ELK+elasticalert/sentinl实现监控报警
喜欢玩ES得童靴可以试试beat+ELK+elastic alert实现监控报警,这几个组件都是elastic官方的,beat分为filebeat、Metricbeat、packetbeat。。等用于采集日志、指标、网络等数据的轻量级agent 安装在客户端,用于周期性采集数据发送到logstash,进过logstash filter过滤后发送ES在经kibana显示,如采集到的内存CPU指标超过elastic alert设定的阈值就可以通过elastic alert报警发邮件等,有点像zabix,但个人赶脚比zabix强,至少可视化效果更好。具体怎么玩可以CSDN看看一些大佬的博客。