Python---正则表达式
正则表达式的基本语法我这里就不再叙述了,网上一大堆,我就不一一列举了,用到的正则表达式我会在分析中列举。
1. 写一个正则表达式判断一个字符串是否是ipv4地址。规则:一个ip地址由4个数字组成,每个数字之间用.连接。每个数字的大小是0-255 例如:255.189.10.37 正确,256.189.89.9 错误。
思路:首先可知ip是由四部分组成,但是前三部分可以同样对待,最后一个由于少一个. 故分开对待处理。而且每个数字必须在0-255之间,其中处理0-255,可以按位数处理,三位即2、5、5,第一位[0-2],第二位[0-5],第三位[0-5]
import re
re_str =r'(([0-1]?\d?\d?|2[0-4]\d|25[0-5])\.){3}([0-1]?\d?\d?|2[0-4]\d|25[0-5])'
result = re.fullmatch(re_str,'255.183.10.37')
print(result)
运行效果图如下:
![]()
import re
re_str =r'(([0-1]?\d?\d?|2[0-4]\d|25[0-5])\.){3}([0-1]?\d?\d?|2[0-4]\d|25[0-5])'
result = re.fullmatch(re_str,'256.189.89.9')
print(result)
运行效果图如下:
![]()
分析:
r'(([0-1]?\d?\d?|2[0-4]\d|25[0-5])\.){3}([0-1]?\d?\d?|2[0-4]\d|25[0-5])'
用到的正则表达式:
r‘xxxx’ --- 单引号里面的xxx原样对待
[0-1] --- []表示范围,匹配位于[]中的任意字符 --- [0-1]即匹配0或1
[0-4] --- []表示范围,匹配位于[]中的任意字符 --- [0-4]即匹配0或1或2或3或4
[0-5] --- []表示范围,匹配位于[]中的任意字符 --- [0-5]即匹配0或1或2或3或4或5
\d --- 匹配任意数字,相当于[0-9]
? --- 匹配位于?之前的0个或1个字符
| --- 匹配位于|之前或之后的内容
{m,n} --- {}前的字符或子模式重复至少m次,最多n次
() --- 将位于()中的内容作为一个整体对待,表示一个子模式
fullmatch(pattern,string[,flags]) --- 从字符串的开始处匹配模式,返回match对象或None
现在开始分解正则表达式:以()分隔符分解三部分子模式如下
([0-1]?\d?\d?|2[0-4]\d|25[0-5])\.) ---
再以|为分隔符细分:
[0-1]?\d?\d? --- [0-1][0-9][0-9] 即000-199
2[0-4]\d --- 2[0-4][0-9] 即200-249
25[0-5])\. --- 25[0-5]. 即250-255. 这里有个.要注意
最终表示000-255. 最后有个.
{3} --- 表示{}前的字符或子模式重复3次,即上面的子模式重复执行3次
([0-1]?\d?\d?|2[0-4]\d|25[0-5]) --- 与第一部分一样,只不过少个.
最后的结果为000-255.000-255.000-255.000-255
即正则表达式搜索属于该范围的内容。
2.使用正则表达式查找文本中最长的数字字符串。
首先,分两种方法通过两个不同的函数来实现。longest1(s):查找所有连续数字 、longest2(s):使用非数字作为分隔符。其中查找所有连续数字是\d来处理分割的、而使用非数字作为分隔符则通过[^\d]来分割实现的
import re
def longest1(s):#查找所有连续数字
t = re.findall('\d+',s)#findall(pattern,string[,flag])返回包含字符串中所有的与给定模式匹配的项的列表
#print(t) #['123456789', '123', '456789']
print(max(t,key = len))#max函数有两个参数:一个可迭代对象(a)和一个可选的“key”函数。 Key功能将用于评估a中最大的项目的值。
if t:
return max(t,key = len)#max() 方法返回给定参数的最大值,参数可以为序列。
return -1
def longest2(s):#使用非数字作为分隔符
t = re.split("[^\d+]",s)#split(pattern,string[,maxsplit=0])根据模式匹配项分隔字符串
#print(t) #['123456789', '', '123', '', '456789']
if t:
return max(t,key = len)
return -1
m = "123456789ss123dd456789"
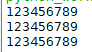
print(longest1(m))
print(longest2(m))
效果图如下:
分析:
代码关键有这三个:
findall(pattern,string[,flag]) --- 返回包含字符串中所有的与给定模式匹配的项的列表
findall('\d+',s) --- 匹配s字符串中的[0-9]字符
split(pattern,string[,maxsplit=0]) --- 根据模式匹配项分隔字符串
split("[^\d+]",s) --- 匹配s字符串中以非[0-9]字符为分割符分割s字符串
max(t,key = value) --- max函数有两个参数:一个可迭代对象(t)和一个可选的“key”函数,key功能将用于评估t中最大的项目的值。key可以接受一个函数,这个函数对key之前出现的参数进行运算。
max(t,key = len) --- 按t这个列表中的每个元素的长度为参数,返回列表中长度最大的那个元素
用到的正则表达式:
\d --- 匹配任意数字,相当于[0-9]
+ --- 匹配位于+之前的字符或子模块的1次或多次的出现
[^\d] --- [^\d] 反向字符集,即除[0-9]之外的其他字符
3.将一句英语文本中的单词进行倒置,标点不倒置,假设单词之间使用一个或多个空格进行分割。比如I like beijing. 经过函数后变为:beijing. like I。
首先,通过\s分割,分割之后存放到一个列表中,然后通过反转输出即可。这里为了格式的需求通过.join(t)以空格为分割来进行连接
import re
def reverse(s):
t = re.split("\s+",s.strip())#split(pattern,string[,maxsplit=0])根据模式匹配项分隔字符串
t.reverse()#对列表的元素进行反向排序
return ' '.join(t)#将序列中的元素以指定的字符连接生成一个新的字符串,这里是通过空格来连接t这个列表中的所有元素
print(reverse('I like beijing.'))
print(reverse('Simple is better than complex.'))
效果图如下:

分析:
代码关键有这三个:
split(pattern,string[,maxsplit=0])根据模式匹配项分隔字符串
strip()方法 用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
split("\s+",s.strip()) --- 首先s.strip()去掉首位空格,然后匹配任意空白字符(这里主要是通过空格区分不同字母,当然这里不会对最后的.进行分割的,这里的.归属与与它前面相邻的字母)
reverse() --- 对列表的元素进行反向排序
' '.join(t) --- 将序列中的元素以指定的字符连接生成一个新的字符串
用到的正则表达式:
\s --- 匹配任意空白字符,包括空格、制表符、换页符,与[\f\n\r\t\v]等效
4.编写程序,使用正则表达式提取另一个Python程序中的所有函数名。
import re
fileName = input('请输入一个 Python 程序文件名:')
pattern = r'def (\w+)'
funcNames = []
with open(fileName, encoding='utf8') as fp:
for line in fp:
result = re.findall(pattern, line)#findall(pattern,string[,flag])返回包含字符串中所有的与给定模式匹配的项的列表
if result:
funcNames.extend(result)
print(funcNames)
该程序分析过几天会更新的
5.假设有一句英文,其中某个单词中有个不在两端的字母误写作大写,编写程序使用正则表达式进行检查和纠正为小写。注意不要影响每个单词两端的字母。
主要通过sub,将真个英文句子中分成三部分,开头、中间、结尾,其中处理中间部分时,通过lower()方法处理一下即可
import re
def checkModify(s):
return re.sub(r'\b(\w)(\w+)(\w)\b',lambda x:x.group(1)+x.group(2).lower()+x.group(3),s)
print(checkModify('aBc ABBC D eeee fFFFfF'))
运行效果如下:
![]()
分析:
代码关键有这一个:sub(r'\b(\w)(\w+)(\w)\b',lambda x:x.group(1)+x.group(2).lower()+x.group(3),s)
主要是sub的三个参数,现在开始分解,一个一个解释:
sub(pat,repl,string[,count=0]) 将字符串中所有与pat匹配的项,用repl替换,返回新字符串,repl可以是字符串或返回字符串的可调用对象,作用于每个匹配的match对象
\b(\w)(\w+)(\w)\b 很简单也就是先看两端即匹配时以[a-zA-Z0-9]开头和结尾,之间内容也是[a-zA-Z0-9],其中里面有三个子模式,开头(group(1))、中间(group(2))、结尾(group(3))。
lambda x:x.group(1)+x.group(2).lower()+x.group(3) 这里的含义就是此时的x为x.group(1)+x.group(2).lower()+x.group(3),也就是将中间的内容字符串中所有大写字符为小写,首尾的字符串不动(其中字符串的分割是以非[a-zA-Z0-9]为分割符的,该题主要是以空格为分隔符)
lower()方法 转换字符串中所有大写字符为小写
用到的正则表达式:
r‘xxxx’ --- 单引号里面的xxx原样对待
\b --- 匹配单词头或单词尾
\w --- 匹配任意字母、数字、以及下划线,相当于[a-zA-Z0-9]
() --- 将位于()中的内容作为一个整体对待,表示一个子模式
6.编写程序,使用正则表达式提取另一个Python程序中的所有变量名。
import re
fileName = input('请输入一个 Python 程序文件名:')
patterns = (r'(.+?)\s=',
r'for (.+?) in',
r'def \w+?\((.*?)\)',
r' as (\w+?):')
funcNames = []
with open(fileName, encoding='utf8') as fp:
for line in fp:
line = line.strip()
for p in patterns:
t = re.findall(p, line)
if t:
for item in t:
funcNames.extend(item.split(','))
print(funcNames)
分析:
代码关键有这些个:
findall(pattern,string[,flag]) --- 返回包含字符串中所有的与给定模式匹配的项的列表
findall(p, line) --- 匹配line字符串中的p,其中p为 r'(.+?)\s=',r'for (.+?) in',r'def \w+?\((.*?)\)',r' as (\w+?):'
strip()方法 移除字符串头尾指定的字符(默认为空格或换行符)或字符序列
用到的正则表达式:
r‘xxxx’ --- 单引号里面的xxx原样对待
() --- 将位于()中的内容作为一个整体对待,表示一个子模式
\w --- 匹配任意字母、数字、以及下划线,相当于[a-zA-Z0-9]
? --- 匹配位于?之前的0个或1个字符
+ --- 匹配位于+之前的字符或子模块的1次或多次的出现
. --- 匹配除换行符以外的任意单个字符
* --- 匹配位于*之前的字符或子模式0次或多次出现