python3——集合(set)
目录
- 1. 集合的基本描述
- 2.集合的基本操作
- 2.1、添加元素
- 2.2、移除元素
- 2.3、计算集合元素个数
- 2.4 、清空集合
- 3.集合内置方法完整列表
1. 集合的基本描述
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
parame = {1,2,3,'haha'}
s=set([]) #空集合
print(type(parame))
print(type(s))

实例:
basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'} #去除功能
print(basket)
print('pear' in basket) #快速判断元素是否在集合内
for i in basket:
print(i,';') #循环迭代
for i ,v in enumerate(basket): #枚举
print(i+1,v)
# 下面展示两个集合间的运算.
a = set('abracadabra')
b = set('alacazam')
print(a-b) # 集合a中包含而集合b中不包含的元素
print(a|b) # 集合a或b中包含的所有元素
print(a&b) # 集合a和b中都包含了的元素
print(a^b) # 不同时包含于a和b的元素

2.集合的基本操作
2.1、添加元素
语法格式如下:
s.add( x )
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
thisset = {'Google', 'Runoob', 'Taobao'}
thisset.add('Facebook')
thisset.add('Runoob')
print(thisset)
![]()
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:
s.update( x )
x 可以有多个,用逗号分开。
thisset1 = set(("Google", "Runoob", "Taobao"))
thisset1.update({1,3})
print(thisset1)
thisset1.update([1,4],[5,6])
print(thisset1)

2.2、移除元素
语法格式如下:
s.remove( x )
将元素 x 从集合 s 中移除,如果元素不存在,则会发生错误。
thisset2={"Google", "Runoob", "Taobao"}
print(thisset2)
thisset2.remove("Taobao")
print(thisset2)
thisset2.remove("Facebook") # 不存在会发生错误

此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:
thisset3= set(("Google", "Runoob", "Taobao","baidu"))
thisset3.discard("Facebook") # 不存在不会发生错误
print(thisset3)
![]()
我们也可以设置随机删除集合中的一个元素,语法格式如下:
s.pop() ##set 集合的 pop 方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除。
实例:
thisset4= {"Google", "Runoob", "Taobao", "Facebook"}
x=thisset4.pop()
print(thisset4)
print("随机删除的元素为:",x)

2.3、计算集合元素个数
语法格式如下:len(s)
thisset5= {"Google", "Runoob", "Taobao", "Facebook"}
print(len(thisset5))
![]()
2.4 、清空集合
语法格式如下:s.clear()
thisset5= {"Google", "Runoob", "Taobao", "Facebook"}
#print(len(thisset5))
thisset5.clear()
print(thisset5)
![]()
3.集合内置方法完整列表
| 方法 | 作用 | 语法 |
|---|---|---|
| copy() | 拷贝一个集合 | set.copy() |
| difference() | 返回多个集合的差集 | set.difference(set) |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在 | set.difference_update(set) |
| intersection() | 返回集合的交集 | set.intersection(set1, set2 … etc) |
| intersection_update() | 用于获取两个或更多集合中都重叠的元素,即计算交集,在原始的集合上移除不重叠的元素。 | set.intersection_update(set1, set2 … etc) |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False | set.isdisjoint(set) |
| issubset() | 用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False | set.issubset(set) |
| issuperset() | 方法用于判断指定集合的所有元素是否都包含在原始的集合中,如果是则返回 True,否则返回 False | set.issuperset(set) |
| symmetric_difference() | 方法返回两个集合中不重复的元素集合,即会移除两个集合中都存在的元素 | set.symmetric_difference(set) |
| symmetric_difference_update() | 方法移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中 | set.symmetric_difference_update(set) |
| union() | 方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次 | set.union(set1, set2…) |
实例1:
fruits = {"apple", "banana", "cherry"}
h = fruits.copy() #复制集合
print(h)
y = {"google", "microsoft", "apple"}
z = h.difference(y) #返回一个集合,元素包含在集合 h ,但不在集合 y :
print(z)
h.difference_update(y) #移除h,y都包含的元素:
print(h)

实例2:
x = {"apple", "banana", "cherry"}
y = {"google", "runoob", "apple"}
z = x.intersection(y) #返回一个新集合,该集合的元素既包含在集合 x 又包含在集合 y 中:
print(z)
print(x)
x.intersection_update(y) #在x基础上移除不与y重叠的元素
print(x)
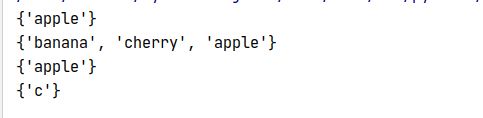
a= {"a", "b", "c"}
b = {"c", "d", "e"}
c = {"f", "g", "c"}
a.intersection_update(b, c) #计算多个集合的并集:
print(a)
实例3:
d= {"apple", "banana", "cherry"}
e = {"google", "runoob", "facebook"}
f = {"apple", "runoob", "facebook"}
h = d.isdisjoint(e) #判断集合e中是否包含集合d的元素
j = d.isdisjoint(f) #如果不包含返回 True,否则返回 False
print(h,j)
![]()
实例4:
x = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b", "a"}
z= {"f", "e", "d", "c", "b"}
h = x.issubset(y) #判断集合x的所有元素是否都包含在集合y中:
print(h)
i= x.issubset(z) #判断集合x的所有元素是否都包含在集合z中:
print(i)
a = {"f", "e", "d", "c", "b", "a"}
b = {"a", "b", "c"}
c= {"f", "e", "d", "c", "b"}
d= a.issuperset(b)#判断集合b的所有元素是否都包含在集合a中:
e= c.issuperset(b)#判断集合b的所有元素是否都包含在集合c中:
print(d,e)

实例5:
x = {"apple", "banana", "cherry"}
y = {"google", "runoob", "apple"}
z = x.symmetric_difference(y) #返回两个集合组成的新集合,但会移除两个集合的重复元素:
print("集合z:",z)
a= {"apple", "banana", "cherry"}
b = {"google", "runoob", "apple"}
a.symmetric_difference_update(b)#在原始集合 a中移除与 b集合中的重复元素,并将不重复的元素插入到集合 a中:
print("集合a",a)

实例6:
x = {"a", "b", "c"}
y = {"f", "d", "a"}
z = {"c", "d", "e"}
result = x.union(y, z) #合并多个集合
print(result)
![]()