oracle学习笔记
第一部分,基础概念
Oracle 数据库的特点:¨支持大数据库、多用户的高性能的事务处理¨ORACLE遵守数据存取语言、操作系统、用户接口和网络通信协议的工业标准¨实施安全性控制和完整性控制¨支持分布式数据库和分布处理¨具有可移植性、可兼容性和可连接性

process 过程
instance 实例
PGA
Oracle之内存结构(SGA、PGA)
PMON
PMON进程负责处理异常结束进程相关资源的释放。PMON周期性地被唤醒,可以对"_PKT_PMON_INTERVAL"这个隐藏参数来进行修改。也可以通过查找出进程的PID,然后在oradebug中,发布 oradebug wakeup orapid(oracle进程的PID,不是OS的PID)来手动唤醒PMON进程。可以用alter session set events '100246 trace name conext forever,level 4'来查看PMON的相关
操作。
SMON是Oracle数据库至关重要的一个后台进程,SMON 是System Monitor 的缩写,意即:系统监控。
SMON负责系统监视已经一些系统清理及恢复工作,这些工作主要包括:
1.清理临时空间以及临时段
SMON负责在数据库启动时清理临时表空间中的临时段,或者一些异常操作过程遗留下来的临时段,例如,当创建索引过程中,创建期间分配给索引的Segment被标志为TEMPORARY,如果Create Index (或rebuild Index等)会话因某些原因异常中断,SMON负责清理这些临时段。
2.接合空闲空间
在DMT(字典管理表空间)中,SMON负责把那些在表空间中空闲的并且互相是邻近的Extent接合成一个较大的空闲扩展区,这需要表空间的pctincrease设置为非零值。
3.执行实例恢复(Instance recovery)
在实例恢复过程中,SMON的工作包括三个环节:应用Redo执行前滚、打开数据库提供访问、回滚未提交数据
4.离线(Offline)回滚段
5.执行并行恢复
实例数据库实例( instance)也称作服务器(server),
是用来访问数据库文件的存储结构及后台进程的集合。在ORACLE 系统中,首先是实例启动,然后由实例装配(MOUNT)一个数据库。实例使用一组所有用户共享的后台进程和一些存储结构来访问数据库中的数据。
数据库
数据库是磁盘上数据的整合,位于收集和维护相关信息的数据库服务器上的一个或多个文件中。数据库由各种物理和逻辑结构组成。

进程:
数据库书写器( Database Writer, 缩写DBWR)
从数据库告诉缓冲存储器中写入数据文件
日志书写器(Log Writer,缩写LGWR)
将重做日志纪录写入磁盘
检查点(Checkpoint,缩写CKPT)
在特定的时间,所有修改的系统全局区数据库缓冲器由DBWn将它们写入数据文件;这种情况叫做检查点。
系统监控器 (System Monitor, 缩写SMON)
系统监控器在一个失败的实例再次启动是执行崩溃恢复。
进程监视器(Process Monitor,缩写PMON)
进程监视器是在用户进程失败是执行进程恢复。
存档器(Archiver, 缩写ARCn)
一个或多个存档器进程在联机重做日志满了或日志切换发生时,将它们拷贝到归档存储中。
恢复器(Recover, 缩写RECO)
恢复器用来解决在分布数据库中由于网络或系统失败而挂起的分布事务。
调度器(Dispatcher,缩写Dnnnn)
调度器是后台进程的选项,只有在多线程服务器(MTS)配置使用时才给出。
表空间是数据库中的基本逻辑结构,一系列数据文件的集合。一个表空间可以包含多个数据文件,但是一个数据文件只能属于一个表空间。Oracle基本的表空间有以下几种:
系统表空间,主要存放数据字典和内部系统表和基表
临时表空间,顾名思义,这是用来存放临时数据的,例如排序操作所需要的临时空间,它的空间会在下次系统启动时全部释放
撤销表空间,主要用来存放一些回滚的信息
数据 表空间,主要存放数据信息。
SGA(System Global Area) 在实例启动时分配, 是数据库实例最基本的组成部件
PGA(Process Global Area 在后台进程启动时分配
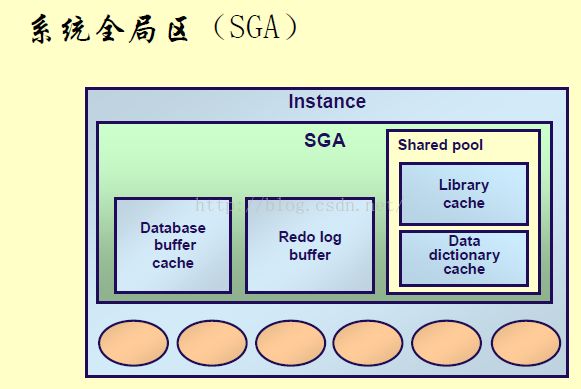
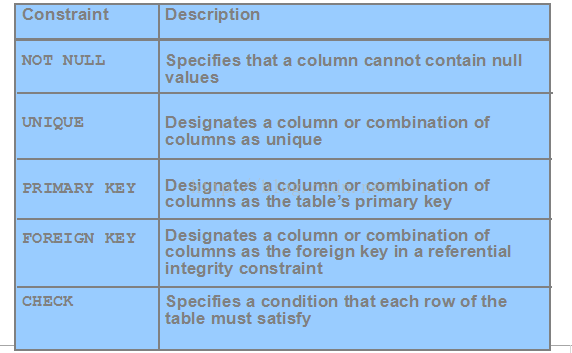
表 (table) 是数据库中的基本存储单位,表中的数据总是存储在行和列中。
索引(index)是与表和簇相关的一种选择结构。索引是为提高数据检索的性能而建立,利用它可快速地确定指定的信息。
约束(constraints)是为了在该数据库中实施所谓的"业务规则"其实就是防止非法信息进入数据库,满足管理员和应用开发人员所定义的规则集.
视图允许用户查看单独表或者多个连接表中数据的的自定义表示。它是原始数据库数据的一种变换,查看表中数据的另外一种方式。
Oracle同义词只是数据库对象的别名,用于简化对数据库对象的引用,并且隐藏数据库对象源的细节。同义词可以赋给表,视图,函数,程序包等等。
第二部分,SQL学习
关系型 数据库
关系型数据库简而言之就是关系/二维表的集合。
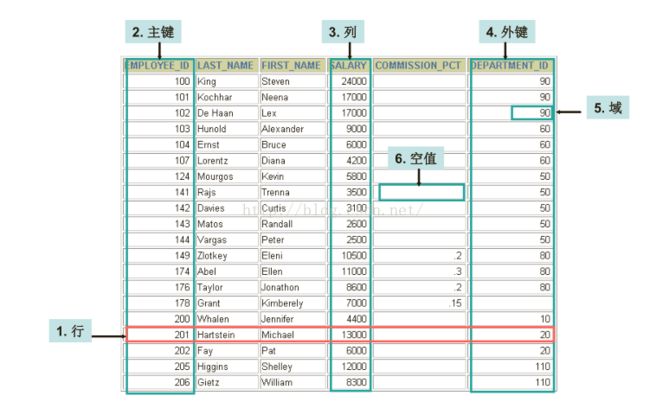
SQL:结构化查询语言
是访问Oracle数据库中数据的描述方法
SQL语言主要提供下述功能:
查询表中数据行
插入、修改、删除表中的数据行
创建、修改、删除数据库对象
保证数据库的一致性和完整性
控制数据库及其访问

merge
用来合并
UPDATE
和INSERT语句。根据一张表(
原数据表,source table
)或
子查询
的连接条件对另外一张(
目标表,target table
)表进行查询,连接条件匹配上的进行UPDATE,无法匹配的执行INSERT。
在Select的时候给列起个别名(注意双引号的作用:有空格特殊字符记得用双引号)
字符串连接操作符: “||”
DISTINCT 去除重复行
| <> | 不等于 |
可使用% 或者_ 作为通配符:% 代表 0个或者多个 字符. _ 代表一个单个字符.
要求找出含有%的记录
select * from t_char where a like ‘%\%%' escape '\';
ASC:升序 DESC:倒序 可以按照字段别名排序
SQL函数类型: 单行函数和多行函数
SQL大小写转换:
| 函数 | 结果 |
| LOWER('SQL Course') | sql course |
| UPPER('SQL Course') | SQL COURSE |
| INITCAP('SQL course') | Sql Course |
字符串操作函数:
| 函数 | 结果 |
| CONCAT('Hello', 'World') | HelloWorld |
| SUBSTR('HelloWorld',1,5) | Hello |
| LENGTH('HelloWorld') | 10 |
| INSTR('HelloWorld', 'W') | 6 |
| LPAD(salary,10,'*') | *****24000 |
| RPAD(salary, 10, '*') | 24000***** |
| TRIM('H' FROM 'HelloWorld') | elloWorld |
| TRIM(' HelloWorld') | HelloWorld |
| TRIM('Hello World') | Hello World |
数字操作函数:
| 函数 | 结果 |
| ROUND(45.926, 2) | 45.93 |
| TRUNC(45.926, 2) | 45.92 |
| MOD(1600, 300) | 100 |
日期操作函数:
| 函数 | 结果 |
| MONTHS_BETWEEN ('01-SEP-95','11-JAN-94') | 19.6774194 |
| ADD_MONTHS ('11-JAN-94',6) | 11-Jul-94 |
| NEXT_DAY ('01-SEP-95','FRIDAY') | 8-Sep-95 |
| NEXT_DAY ('01-SEP-95',1) | 2-Sep-95 |
| NEXT_DAY ('1995-09-01',1) | ORA-01861:literal does not match format string |
| NEXT_DAY (to_date('1995-09-01','YYYY-MM-DD'),1) | 2-Sep-95 |
| LAST_DAY('01-FEB-95') | 28-Feb-95 |
| ROUND('25-JUL-95','MONTH') | 1-Aug-95 |
| ROUND('25-JUL-95' ,'YEAR') | 1-Jan-96 |
| TRUNC('25-JUL-95' ,'MONTH') | 1-Jul-95 |
| TRUNC('25-JUL-95','YEAR') | 1-Jan-95 |
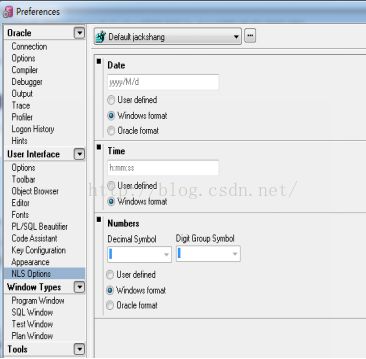
SELECT last_name, (SYSDATE-hire_date)/7 AS WEEKS, sysdate+1 as tomorrow , hire_date + 8/24 FROM employeesWHERE department_id = 90;
Oracle 数据类型的 隐式转换规则:
| 从 | 到 |
| VARCHAR2 or CHAR | NUMBER |
| VARCHAR2 or CHAR | DATE |
| NUMBER | VARCHAR2 |
| DATE | VARCHAR2 |
对于表达式比较操作仅可以:
| 从 | 到 |
| VARCHAR2 or CHAR | NUMBER |
| VARCHAR2 or CHAR | DATE |
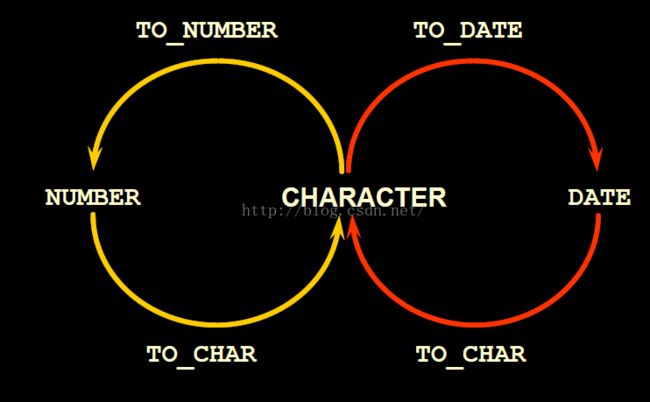
TO_CHAR() 函数:日期到字符串的转换
TO_CHAR(date, 'format_model') ;
| 日期格式化元素 | 意义 |
| YYYY | 4位数字表示的年份 |
| YEAR | 英文描述的年份 |
| MM | 2位数字表示的月份 |
| MONTH | 英文描述的月份 |
| MON | 三个字母的英文描述月份简称 |
| DD | 2位数字表示的日期 |
| DAY | 英文描述的星期几 |
| DY | 三个字母的英文描述的星期几简称 |
| HH24:MI:SS AM | 时分秒的格式化 |
| DDspth | 英文描述的月中第几天 |
| fm | 格式化关键字,可选 |
TO_NUMBER() 函数:字符串到数字的转换
TO_NUMBER(char[, 'format_model']) ;
TO_DATE() 函数:字符串到日期的转换
| TO_DATE应用 | 正确与否 |
| select to_date ('22-FEB-11') from dual; | √ |
| select to_date('2011-2-22') from dual; | Ⅹ |
| select to_date('2011-2-22','YYYY-MM-DD') from dual; | √ |
| select to_date('2-22-2011','MM-DD-YYYY') from dual; | √ |
| select to_date('2011-FEB-22','YYYY-MON-DD') from dual; | √ |
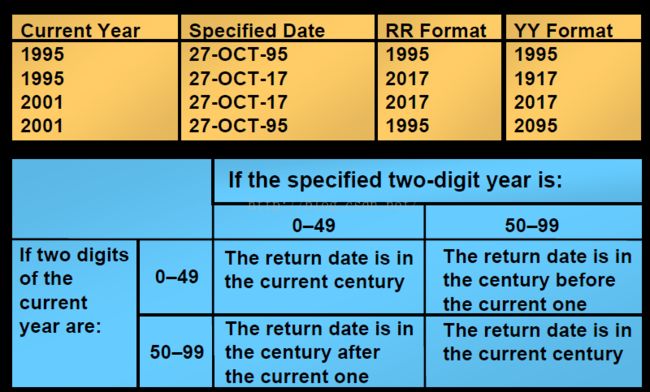
TO_DATE() 函数:日期转换时使用RR格式的注意事项
| 函数 | 用途 |
| NVL (expr1, expr2) | 如果expr1为空,这返回expr2 |
| NVL2 (expr1, expr2, expr3) | 如果expr1为空,这返回expr3(第2个结果)否则返回expr2 |
| NULLIF (expr1, expr2) | 如果expr1和expr2相等,则返回空 |
| COALESCE (expr1, expr2, ..., exprn) | 如果expr1不为空,则返回expr1,结束;否则计算expr2,直到找到一个不为NULL的值 或者如果全部为NULL,也只能返回NULL了 |
CASE 语句:
CASE expr WHEN comparison_expr1 THEN
return_expr1
[WHEN comparison_expr2 THEN
return_expr2
WHEN comparison_exprn THEN
return_exprnELSE else_expr]
END
DECODE函数:(
将查询结果翻译成其他值)
举例说明:
现定义一table名为output,其中定义两个column分别为monthid(var型)和sale(number型),若sale值=1000时翻译为D,=2000时翻译为C,=3000时翻译为B,=4000时翻译为A,如是其他值则翻译为Other;
SQL如下:
Select monthid , decode (sale,1000,'D',2000,'C',3000,'B',4000,'A',’Other’) sale from output
若只与一个值进行比较
Select monthid ,decode(sale, NULL,‘---’,sale) sale from output
另:decode中可使用其他函数,如nvl函数或sign()函数等;
NVL(EXPR1,EXPR2)
若EXPR1是NULL,则返回EXPR2,否则返回EXPR1.
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1,
如果取较小值就是
select monthid,decode(sign(sale-6000),-1,sale,6000) from output,即达到取较小值的目的。
“外链接” 语法: 包括左外连接,右外连接
哪面数据显示全。哪面放+号
SELECT table1.column, table2.columnFROM table1, table2WHERE table1.column(+) = table2.column;(左)
SELECT table1.column, table2.columnFROM table1, table2WHERE table1.column = table2.column (+);(右)
“自链接” : 其实是一种概念,某个table和自己本身链接 ,比如:table1给另一个“自己”起别名为table2
SELECT table1.column, table2.columnFROM table1, table1 table2WHERE table1.column1 = table2.column2;
SELECT worker.last_name || ' works for ' || manager.last_name FROM employees worker, employees manager WHERE worker.manager_id = manager.employee_id ;
CROSS JOIN 返回的是笛卡尔积
全外连接 FULL OUTER JOIN departments d ON (e.department_id = d.department_id)
分组计算函数(常用):包括
1、求和 (SUM)
2、求平均值(AVG)
3、计数(COUNT)
4、求标准差(STDDEV)
5、求方差(VARIANCE)
6、求最大值(MAX)
7、求最小值(MIN)
COUNT 函数说明 :
| 函数用法 | 意义 |
| COUNT(*) | 返回满足选择条件的所有行的行数,包括值为空的行和重复的行 |
| COUNT(expr) | 返回满足选择条件的且表达式不为空行数。 |
| COUNT(DISTINCT expr) | 返回满足选择条件的且表达式不为空,且不重复的行数。 |
使用GROUP BY 子句进行分组: 2、SELECT 查询语句中同时选择分组计算函数表达式和其他独立字段时 ,其他字段必须出现在Group By子句中,否则不合法。
MERGE 语句: 比较整合语句, 语法:
MERGE INTO copy_emp c
USING employees e
ON (c.employee_id = e.employee_id)
WHEN MATCHED THEN
UPDATE SET c.first_name = e.first_name, c.last_name = e.last_name, ... c.department_id = e.department_id
WHEN NOT MATCHED THEN
INSERT VALUES(e.employee_id, e.first_name, e.last_name, e.email, e.phone_number, e.hire_date, e.job_id, e.salary, e.commission_pct, e.manager_id, e.department_id);
锁:
select a.*, C.type, C.LMODE from v$locked_object a, all_objects b, v$lock c where a.OBJECT_ID = b.OBJECT_ID and a.SESSION_ID = c.SID and b.OBJECT_NAME = 'TESTTAB3'
| 数据类型 | 描述 |
| VARCHAR2(size) | 可变长字符串 |
| CHAR(size) | 定长字符串 |
| NUMBER(p,s) | 可变长数值 |
| DATE | 日期时间 |
| LONG | 可变长大字符串,最大可到2G |
| CLOB | 可变长大字符串数据,最大可到4G |
| RAW and LONG RAW | 二进制数据 |
| BLOB | 大二进制数据,最大可到4G |
| BFILE | 存储于外部文件的二进制数据,最大可到4G |
| ROWID | 64进制18位长度的数据,用以标识行的地址 |
| TIMESTAMP | 精确到分秒级的日期类型(9i以后提供的增强数据类型) |
| INTERVAL YEAR TO MONTH | 表示几年几个月的间隔(9i以后提供的增强数据类型-极其少见) |
| INTERVAL DAY TO SECOND | 表示几天几小时几分几秒的间隔(9i以后提供的增强数据类型-极其少见) |
只想保留表结构,但不想要数据,可以
CREATE TABLE as select * from tableb where 1=2
改表名:
RENAME oldtablename to newtableName;
一次性清空一张表中的所有内容,但保留表结构
TRUNCATE TABLE tableName;
注意TRUNCATE 与DELETE FROM table 的区别: 1)没有Rollback机会 2)HWM标记复位
约束
CREATE TABLE employees( employee_id NUMBER(6), first_name VARCHAR2(20), ... job_id VARCHAR2(10) NOT NULL,
CONSTRAINT emp_emp_id_pk PRIMARY KEY (EMPLOYEE_ID));
ALTER TABLE CUX_LES_JE_LINES ADD CONSTRAINT CUX_LES_JE_LINES_PK PRIMARY KEY(JE_LINE_ID);
唯一性约束举例:
CONSTRAINT emp_email_uk UNIQUE(email))
外键约束举例:也称为引用数据完整性约束
CONSTRAINT emp_dept_fk FOREIGN KEY (department_id) REFERENCES departments(department_id),
外键约束类型:
REFERENCES: 表示列中的值必须在父表中存在
ON DELETE CASCADE: 当父表记录删除的时候自动删除子表中的相应记录.
ON DELETE SET NULL: 当父表记录删除的时候自动把子表中相应记录的值设为NULL
查询系统中存在哪些约束:
SELECT constraint_name, constraint_type, search_conditionFROM user_constraintsWHERE table_name = 'EMPLOYEES';