【大数据干货】数据进入阿里云数加-大数据计算服务MaxCompute(原ODPS)的N种方式...
免费开通大数据服务:https://www.aliyun.com/product/odps
想用阿里云大数据计算服务(MaxCompute),对于大多数人首先碰到的问题就是数据如何迁移到MaxCompute中。按照数据迁移场景,大致可以分为批量数据、实时数据、本地文件、日志文件等的迁移,下面我们针对每种场景分别介绍几种常用方案。
 大数据计算服务(MaxCompute)
大数据计算服务(MaxCompute)

一、 异构数据源批量数据迁移到MaxCompute
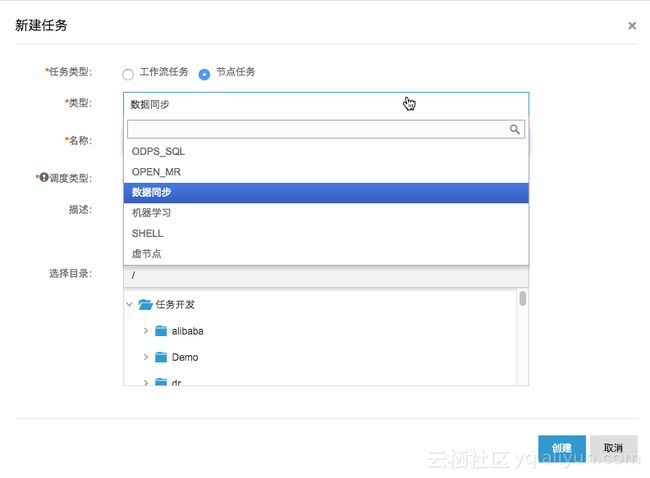
1、通过大数据开发套件(DataIDE)- 数据开发做数据同步
i. 开通大数据开发套件,进入项目管理-数据源管理中将数据源配置到DataIDE中,并保证连通性。目前MaxCompute支持的数据源如下图:

MaxCompute产品地址:https://www.aliyun.com/product/odps
ii.创建数据同步任务,配置数据映射
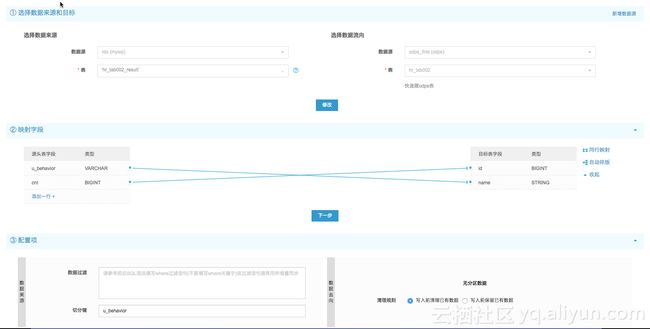
iii.保存后提交运行,可以通过执行日志监控执行成功与否。
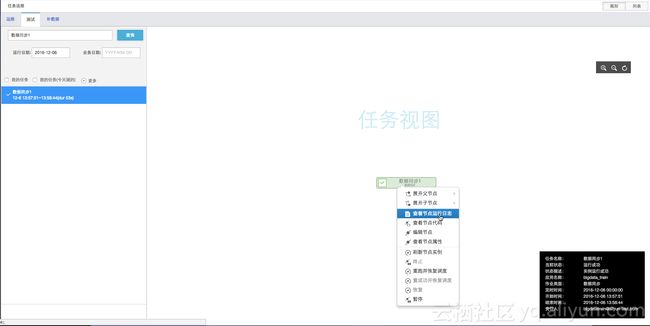
适用场景:这种方式通过界面向导逐步配置,操作简单容易上手,对于大数据开发套件(DataIDE)已经支持的数据源之间同步数据非常方便,但是要确保数据源连通性,同时对数据同步的速度也有限制,最高10M/s。
2、通过DataX实现数据同步
DataX 是阿里巴巴集团内被广泛使用的异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、MaxCompute(原ODPS)、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
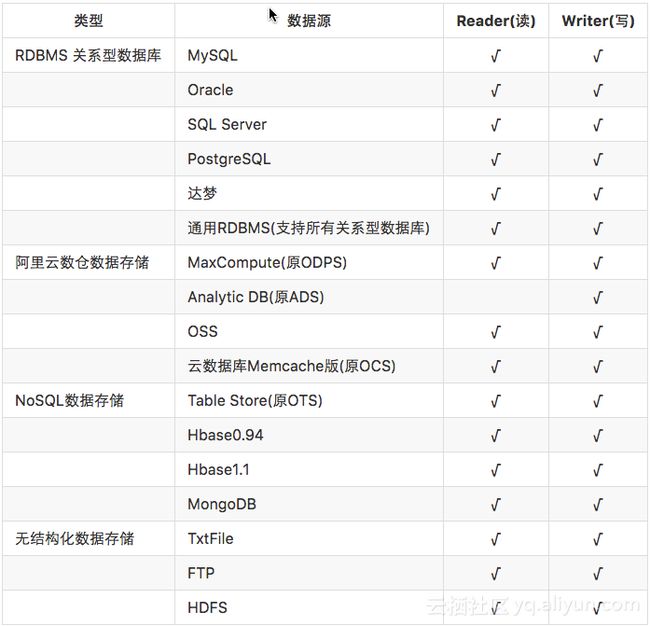
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
使用示例(从MySQL读取数据 写入ODPS):
i.直接下载DataX工具包,下载后解压至本地某个目录,修改权限为755。下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
ii.创建作业配置文件
python datax.py -r mysqlreader -w odpswriter
iii.根据配置文件模板填写相关选项(源和目标数据库的用户名、密码、URL、表名、列名等),如下图:

iv. 启动DataX同步任务
python datax.py ./mysql2odps.json
适用场景:DataX通过plugin的方式实现对异构数据源的支持,支持的数据源种类更丰富,对于暂不支持的数据源用户也可以自己扩展plugin实现。另外这种方式通过配置文件做源和目标的映射非常灵活,同时也很容易跟其他的任务做集成。
3、通过Sqoop实现数据同步
请参考https://github.com/aliyun/aliyun-odps-sqoop
二、本地文件上传到MaxCompute
1、通过大数据开发套件(DataIDE)导入本地文件
i.登陆“大数据开发套件-数据开发”,点击“导入-导入本地数据”
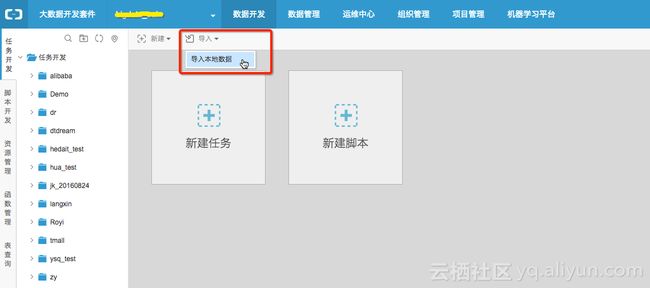
ii. 配置分隔符、数据文件字符编码等
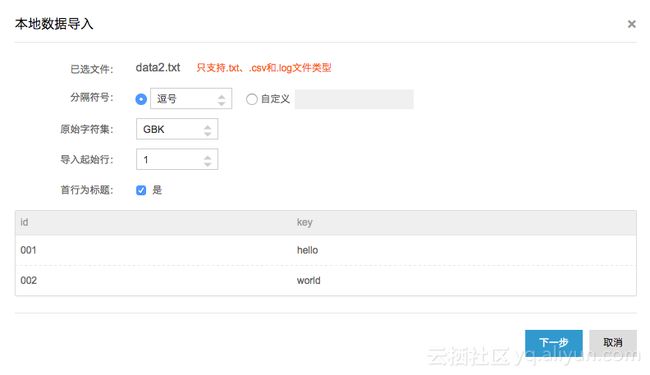
iii.选择目标表后即可导入
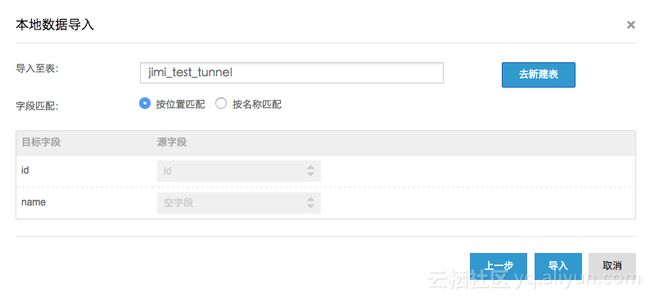
适用场景:这种方式适用于一些简单场景验证,通过向导方式上传本地文件简单易用,但是对于文件大小限制不能超过10M。
2、通过MaxCompute客户端上传数据
i.下载MaxCompute客户端
下载路径:http://repo.aliyun.com/download/odpscmd/0.24.1/odpscmd_public.zip
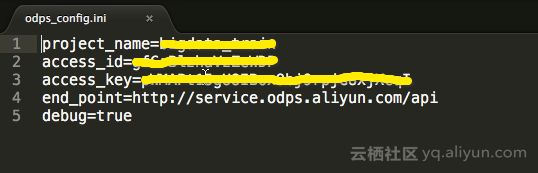
ii.解压并配置客户端
解压后进入到conf目录,用编辑器打开odps_config.ini,配置相应的access_id、access_key、project_name等。
iii.运行MaxCompute客户端
odpscmd –config=../conf/odps_config.ini
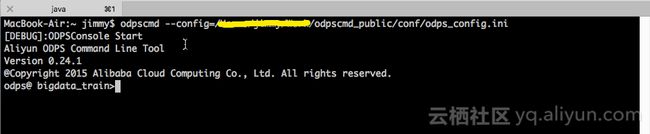
iv.通过tunnel 可以上传下载数据,详情可以通过tunnel help查看帮助
v.通过tunnel upload上传本地文件到MaxCompute,详情可以通过tunnel help upload查看帮助
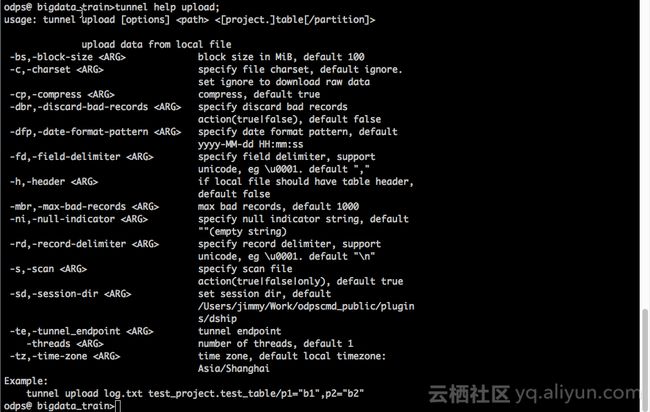
命令示例:
tunnel upload ./data.txt test_tunnel -fd "," -rd "\n";
解读:
data.txt – 数据文件,导入时注意指定路径
test_tunnel – MaxCompute中数据表
-fd "," – 指定逗号为数据列分隔符
-rd "\n" – 指定换行符为数据行分隔符
命令行使用请参考
https://help.aliyun.com/document_detail/27833.html
另外有个性化需求的也可以通过Tunnel SDK的方式做数据同步,详见:https://help.aliyun.com/document_detail/27837.html
适用场景:通过Tunnel上传数据适合数据文件大小适中的场景(比如单表上百GB可能会由于数据本身或者网络不稳定导致数据导入失败),并且可以指定线程数等来提升效率,充分发挥硬件性能。
三、 实时数据归档到MaxCompute
1.通过DataHub将流式数据归档到MaxCompute
用户通过创建DataHub Connector,指定相关配置,即可创建将Datahub中流式数据定期归档的同步任务。请参考https://datahub.console.aliyun.com/intro/advancedguide/connector.html
2.通过DTS将数据实时同步到MaxCompute
目前实时同步只能支持RDS MySQL实例,暂不支持其他数据源类型。请参考https://help.aliyun.com/document_detail/26614.html
3.通过OGG将数据实时同步到MaxCompute
这种方式要通过OGG将实时数据先同步到DataHub,再在DataHub中通过创建DataHub Connector将数据实时归档到MaxCompute。请参考https://datahub.console.aliyun.com/intro/guide/plugins/ogg.html
四、日志数据同步到MaxCompute
目前日志类型的数据实时同步到MaxCompute的需求也非常强。市面上也有很多成熟的日志收集工具,比如Fluentd、Logstash。日志数据实时同步到MaxCompute的方案也是要借助于这些成熟的日志收集工具,将日志数据同步到DataHub中后,再通过DataHub将数据归档到MaxCompute,数据链路:

1.通过Logstash采集日志数据到MaxCompute
请参考https://help.aliyun.com/document_detail/47451.html
归档到Max Compute https://help.aliyun.com/document_detail/47453.html
2.通过Fluentd采集日志数据到MaxCompute
请参考https://help.aliyun.com/document_detail/47450.html
归档到Max Compute https://help.aliyun.com/document_detail/47453.html