Python自学第6周反馈:爬取某城市企业黄页信息(1)-- --分析该地区产业结构
为了知道在某个城市什么行业比较好做,所以这里的目标时对某黄页网站的信息进行爬取,获得在录的企业数据,用来反应当地的产业结构
目标:抓取各行各业的企业数量(在录)
来源:某企业黄页网站
步骤1:解析URL
步骤2:编写爬取代码
步骤3:导出信息并简单分析
备注:文末会分享本次自学过程中的完整代码内容,
下一篇博客将会分享爬取某城市行业在录公司的信息(公司名、法人、注册时间、产品、联系方式等)
零、 首先,写一个工具:
用来重复尝试请求url中特定元素的信息(含注释解析)
from retrying import retry #从retrying库中导入retry模块,获取网页时连接超时重复尝试
@retry(stop_max_attempt_number=10) #设置最大尝试次数
def huoqu(url,yuansu,time_out): #写一个获取网页中关键信息的函数huoqu(获取)
try: #如果失败,重复尝试以下程序
from urllib import request #从urllib库中导入request模块
#编写请求头User-Agent,用来避免一些反爬,可以从自己的后台获取
qingqiutou_UA = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN;rv:1.8.1.14) Gecko/20080404 Firefox/2.0.0.14'}
URL = request.Request(url, headers=qingqiutou_UA) #对url装载请求头User-Agent
shuju_1 = request.urlopen(URL, timeout=time_out) #把URL请求到的数据装入一个变量shuju_1中,设置请求时长timeout,超时就会进行重新尝试
shuju_2 = shuju_1.readlines() #把得到的数据按行读取成行数据列表,装进新变量shuju_2
guodu = [] #设置一个过渡列表
for a in shuju_2: #遍历shuju_2内的行数据列表
if yuansu in a.decode('utf-8').strip(): #如果行数据列表中的元素进行utf-8解码后包含指定的信息元素(yuansu)
guodu.append(a.decode('utf-8').strip()) #就把这个解码后的元素用strip()函数排除前后空白后放入过渡列表
if len(guodu) <= 1: #判断过渡列表中含有的元素个数是否小于等于1
for i in guodu: #如果是,说明只有小于一行符合要求,那么单独抽出这个元素
shuju_3 = i #把这个元素给新变量shuju_3
else: #如果不是,过渡列表含有多个符合元素
shuju_3 = guodu #则让新变量shuju_3等于这个过渡列表
except: #如果反复尝试5次之后仍然连接超时
shuju_3 = '' #则让新变量shuju_3等于空值''
return shuju_3 #对调用函数huoqu返回shuju_3(可能是单个字符串,也可能是列表或者None)
一、 解析URL首页:

这个页面的源码中含有所有下级页面的URL,只需要调用上面写好的获取函数,对这个页面的特定信息进行提取,即可获得装有所有下级URL 的列表
url = 'http://b2b.huangye88.com/huizhou/' #目标网址是某黄页网站某地区的‘首页’,从这个网址获取其他下级页面的URL
url_1 = huoqu(url,'.com',30) #调用获取函数,对‘首页’获取其中包括'.com'元素即为网址的行信息,设置时间为30S
url_2 = [] #建立一个空白的列表url_2
for a in url_1: #遍历得到的含有下级url的列表
if '名录">惠州' in a: #通过查看网页源码可以发现下级网页所在都包含有'名录">惠州',通过这个成分对信息进行一次过滤
url_2.append(a) #过滤后放入准备好的列表url_2
url_3 = [] #建立一个空白的列表url_3
for b in url_2: #遍历上一次过滤后得到的列表
C = re.split(r'"',b) #对列表元素进行切割,所有的下级url都用"双引号括起来,用split()在"所在地方切割获得单独的url
for c in C: #从这种切割后获得的列表中遍历
if '.com' in c: #如果含有 '.com'即为url,提取出来
url_3.append(c) #放入准备好的列表url_3
二、 对得到的二级URL列表发送请求获取主要信息
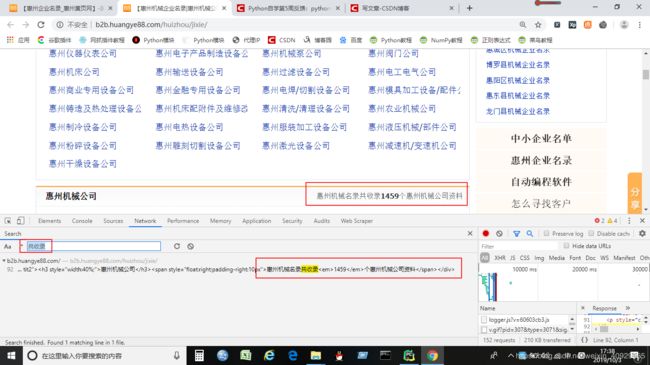
<span style="float:right;padding-right:10px">惠州机械名录共收录<em>1459</em>个惠州机械公司资料</span>
可以看到:
“>” 和 “ 符号之间:
包括了收录个数 “1459” ,和行业词条 “个惠州机械公司资料”
其中:
“个惠州机械公司资料” 的行业名:“机械” 被包含在 “惠州” 和 “公司” 之间
所以:
1.用写好的获取函数,单独获取含有‘共收录’元素的行信息;
2.并按照符号 “>” 和 “ 用re库下的split()函数进行切割,指定位置即为收录数量
3.再对 “个惠州机械公司资料” 按照 “惠州” 和 “公司” 进行切割,获得指定位置的行业名称
4.排列装载进字典中即可输出
Xinxi = [] #建立一个空白的列表Xinxi用来放信息
for d in list(range(1,len(url_3)+1)): #建立一个列表用来表示url_3的序数并遍历这个序数列表
url_4 = url_3[d-1] #把url_3指定位置的元素给变量url_4(这里是循环放入url字符串)
xinxi = huoqu(url_4, '共收录', 30) #目标是找到某城市某行业收录了多少条公司信息,所以依据源码,对'共收录'调用获取函数
Xinxi.append(xinxi) #把获取的信息xinxi放入专门的列表Xinxi中
# 这一步用来显示系统循环的进程
sys.stdout.write('\r[ === [%d/%d] %d%% === ]' % ((d), len(url_3), int((d) /len(url_3) * 100)))
xinxi = {} #准备一个空字典xinxi,这里的信息个循环内的xinxi不一致不影响
for e in range(0,len(Xinxi)): #建立一个列表用来表示Xxinxi的序数并遍历这个序数列表
E = re.split(r'>|,str(Xinxi[e])) #对遍历到的序数位置的元素进行切割,解析源码后知道主要信息被包括在>,
#print(E)
xinxi['第'+str(e+1)+'行'] = {} #每个行业建立一个行键,显示为第几行数据
jian = re.split(r'惠州|公司',str(E[2])) #对切割后的E列表中的第三个元素按照惠州,公司两个进行再切割,得到的新列表第二个元素包含了行业名称
#print(jian)
xinxi['第'+str(e+1)+'行']['第'+str(1)+'列']=str(jian[1])#把行业名称放到当行第一列
xinxi['第'+str(e+1)+'行']['第'+str(2)+'列'] = int(E[6])#把E列表中第7个元素即收录数量放入当行第二列
for a,b in xinxi.items(): #遍历一下这个xinxi列表查看下信息是否正确
print(a,b)
最受显示出来的效果即为:
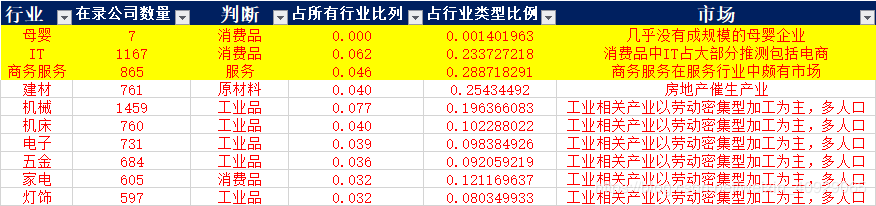
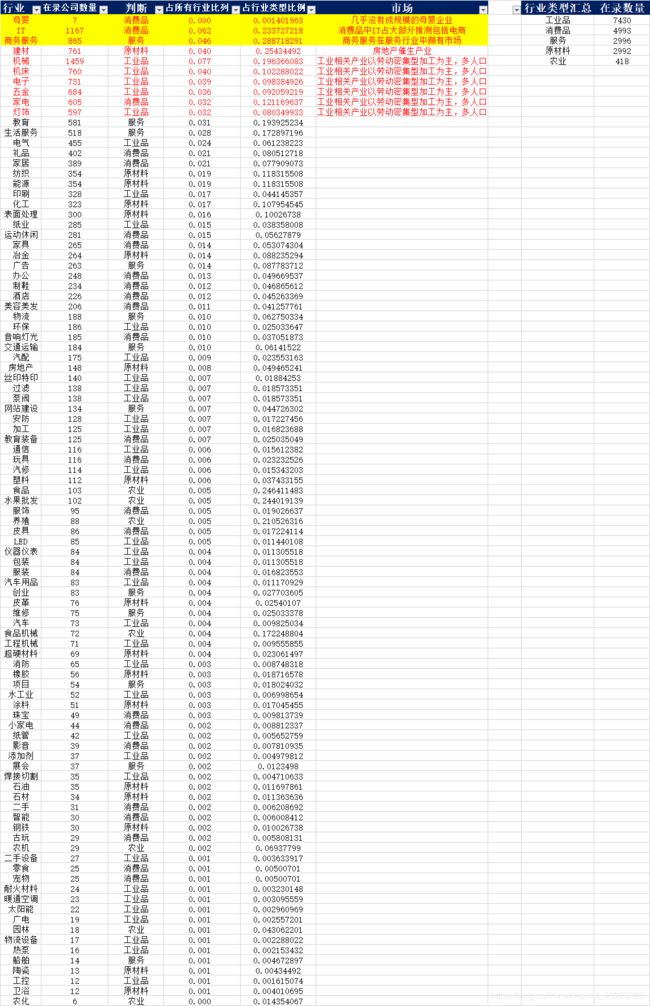
第1行 {'第1列': '机械', '第2列': 1459}
第2行 {'第1列': '机床', '第2列': 760}
第3行 {'第1列': '电子', '第2列': 731}
第4行 {'第1列': '五金', '第2列': 684}
第5行 {'第1列': '灯饰', '第2列': 597}
第6行 {'第1列': '电气', '第2列': 455}
第7行 {'第1列': '印刷', '第2列': 328}
第8行 {'第1列': '纸业', '第2列': 285}
第9行 {'第1列': '环保', '第2列': 186}
第10行 {'第1列': '汽配', '第2列': 175}
第11行 {'第1列': '丝印特印', '第2列': 140}
第12行 {'第1列': '过滤', '第2列': 138}
第13行 {'第1列': '泵阀', '第2列': 138}
第14行 {'第1列': '安防', '第2列': 128}
第15行 {'第1列': '加工', '第2列': 125}
第16行 {'第1列': '通信', '第2列': 116}
第17行 {'第1列': '汽修', '第2列': 114}
第18行 {'第1列': 'LED', '第2列': 85}
第19行 {'第1列': '汽车用品', '第2列': 83}
第20行 {'第1列': '仪器仪表', '第2列': 84}
第21行 {'第1列': '包装', '第2列': 84}
第22行 {'第1列': '汽车', '第2列': 73}
第23行 {'第1列': '工程机械', '第2列': 71}
第24行 {'第1列': '消防', '第2列': 65}
第25行 {'第1列': '水工业', '第2列': 52}
第26行 {'第1列': '纸管', '第2列': 42}
第27行 {'第1列': '添加剂', '第2列': 37}
第28行 {'第1列': '焊接切割', '第2列': 35}
第29行 {'第1列': '二手设备', '第2列': 27}
第30行 {'第1列': '耐火材料', '第2列': 24}
第31行 {'第1列': '暖通空调', '第2列': 23}
第32行 {'第1列': '太阳能', '第2列': 22}
第33行 {'第1列': '广电', '第2列': 19}
第34行 {'第1列': '物流设备', '第2列': 17}
第35行 {'第1列': '热泵', '第2列': 16}
第36行 {'第1列': '工控', '第2列': 12}
第37行 {'第1列': 'IT', '第2列': 1167}
第38行 {'第1列': '家电', '第2列': 605}
第39行 {'第1列': '礼品', '第2列': 402}
第40行 {'第1列': '家居', '第2列': 389}
第41行 {'第1列': '运动休闲', '第2列': 281}
第42行 {'第1列': '家具', '第2列': 265}
第43行 {'第1列': '办公', '第2列': 248}
第44行 {'第1列': '制鞋', '第2列': 234}
第45行 {'第1列': '酒店', '第2列': 226}
第46行 {'第1列': '美容美发', '第2列': 206}
第47行 {'第1列': '音响灯光', '第2列': 185}
第48行 {'第1列': '教育装备', '第2列': 125}
第49行 {'第1列': '玩具', '第2列': 116}
第50行 {'第1列': '服饰', '第2列': 95}
第51行 {'第1列': '皮具', '第2列': 86}
第52行 {'第1列': '服装', '第2列': 84}
第53行 {'第1列': '珠宝', '第2列': 49}
第54行 {'第1列': '小家电', '第2列': 44}
第55行 {'第1列': '影音', '第2列': 39}
第56行 {'第1列': '二手', '第2列': 31}
第57行 {'第1列': '智能', '第2列': 30}
第58行 {'第1列': '古玩', '第2列': 29}
第59行 {'第1列': '零食', '第2列': 25}
第60行 {'第1列': '宠物', '第2列': 25}
第61行 {'第1列': '母婴', '第2列': 7}
第62行 {'第1列': '商务服务', '第2列': 865}
第63行 {'第1列': '教育', '第2列': 581}
第64行 {'第1列': '生活服务', '第2列': 518}
第65行 {'第1列': '广告', '第2列': 263}
第66行 {'第1列': '物流', '第2列': 188}
第67行 {'第1列': '交通运输', '第2列': 184}
第68行 {'第1列': '网站建设', '第2列': 134}
第69行 {'第1列': '创业', '第2列': 83}
第70行 {'第1列': '维修', '第2列': 75}
第71行 {'第1列': '项目', '第2列': 54}
第72行 {'第1列': '展会', '第2列': 37}
第73行 {'第1列': '船舶', '第2列': 14}
第74行 {'第1列': '建材', '第2列': 761}
第75行 {'第1列': '纺织', '第2列': 354}
第76行 {'第1列': '能源', '第2列': 354}
第77行 {'第1列': '化工', '第2列': 323}
第78行 {'第1列': '表面处理', '第2列': 300}
第79行 {'第1列': '冶金', '第2列': 264}
第80行 {'第1列': '房地产', '第2列': 148}
第81行 {'第1列': '塑料', '第2列': 112}
第82行 {'第1列': '皮革', '第2列': 76}
第83行 {'第1列': '超硬材料', '第2列': 69}
第84行 {'第1列': '橡胶', '第2列': 56}
第85行 {'第1列': '涂料', '第2列': 51}
第86行 {'第1列': '石油', '第2列': 35}
第87行 {'第1列': '石材', '第2列': 34}
第88行 {'第1列': '钢铁', '第2列': 30}
第89行 {'第1列': '陶瓷', '第2列': 13}
第90行 {'第1列': '卫浴', '第2列': 12}
第91行 {'第1列': '食品', '第2列': 103}
第92行 {'第1列': '水果批发', '第2列': 102}
第93行 {'第1列': '养殖', '第2列': 88}
第94行 {'第1列': '食品机械', '第2列': 72}
第95行 {'第1列': '农机', '第2列': 29}
第96行 {'第1列': '园林', '第2列': 18}
第97行 {'第1列': '农化', '第2列': 6}
分享两个写好的工具函数用于导出标准字典(第几行第几列)数据:
#把表格字典转化成表格样式的一整个字符串 返回字符串
def write_excel(A): #创建一个转换字典为特定字符表的函数
for B,C in A.items(): #遍历表字典内的行:列键值对
Hang = int(len(A)) #获得行数
Lie = int(len(C)) #获得列数
Lie_Biao = [] #创建中转列:值对的列表
Zuizhong = [] #创建最终所有列值对字符串列表
for hhh in A.values(): #遍历表中的列字典
for lll in hhh.values(): #遍历列字典的值
Lie_Biao.append(str(lll)) #把值字符串化添加到值列表
for hangshu in range(0, Hang + 1): #定义行数为跳转步长
guodu = Lie_Biao[hangshu * Lie:hangshu * Lie + Lie] #定义按每行转化成过渡切片
jiange_1 = '\t' #定义一个制表符
meiyihang = jiange_1.join(guodu) #用制表符来连接切片中的每一列
Zuizhong.append(meiyihang) #把由每一列连起来的每一行添加到最终列表
jiange_2 = '\n' #定义一个换行符
zhenggebiao = jiange_2.join(Zuizhong) #用换行符来连接最终列表内每个行元素
return zhenggebiao #返回一个表示整个表的字符串
#把特定的字符串写入特定路径按特定名和格式保存
def save_excel(baocunduixiang,wenjianjialujing,baocunming,geshihouzhui):
baocunming = str(baocunming) #指定保存名
LUJING_NEW = wenjianjialujing + '\\' + baocunming + '.'+ geshihouzhui #拼装最终路径
f = open(LUJING_NEW, 'w',encoding='utf-8') # 在目的路径声明一个文件及格式并打开
f.write(baocunduixiang) # 把处理好的信息写入这个文件
f.close() # 关闭写入操作
调用这两个工具函数对上面的数据进行保存即可:
qiye = write_excel(xinxi)
lujing = input("路径:")
baocun = input("保存文件名:")
save_excel(qiye,lujing,baocun,'xls')
得到的数据如图标所示:
这里分享下本次学习中的完整代码,如果抓取失败可能是因为超时导致没有信息可供切割导致的:
from retrying import retry #从retrying库中导入retry模块,获取网页时连接超时重复尝试
@retry(stop_max_attempt_number=10) #设置最大尝试次数
def huoqu(url,yuansu,time_out): #写一个获取网页中关键信息的函数huoqu(获取)
try: #如果失败,重复尝试以下程序
from urllib import request #从urllib库中导入request模块
#编写请求头User-Agent,用来避免一些反爬,可以从自己的后台获取
qingqiutou_UA = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN;rv:1.8.1.14) Gecko/20080404 Firefox/2.0.0.14'}
URL = request.Request(url, headers=qingqiutou_UA) #对url装载请求头User-Agent
shuju_1 = request.urlopen(URL, timeout=time_out) #把URL请求到的数据装入一个变量shuju_1中,设置请求时长timeout,超时就会进行重新尝试
shuju_2 = shuju_1.readlines() #把得到的数据按行读取成行数据列表,装进新变量shuju_2
guodu = [] #设置一个过渡列表
for a in shuju_2: #遍历shuju_2内的行数据列表
if yuansu in a.decode('utf-8').strip(): #如果行数据列表中的元素进行utf-8解码后包含指定的信息元素(yuansu)
guodu.append(a.decode('utf-8').strip()) #就把这个解码后的元素用strip()函数排除前后空白后放入过渡列表
if len(guodu) <= 1: #判断过渡列表中含有的元素个数是否小于等于1
for i in guodu: #如果是,说明只有小于一行符合要求,那么单独抽出这个元素
shuju_3 = i #把这个元素给新变量shuju_3
else: #如果不是,过渡列表含有多个符合元素
shuju_3 = guodu #则让新变量shuju_3等于这个过渡列表
except: #如果反复尝试5次之后仍然连接超时
shuju_3 = '' #则让新变量shuju_3等于空值''
return shuju_3 #对调用函数huoqu返回shuju_3(可能是单个字符串,也可能是列表或者None)
import time,sys #导入sys模块用来显示系统进程,time模块用来显示时间
import re #导入re模块用来调用split()函数对字符串特定位置进行切割
url = 'http://b2b.huangye88.com/huizhou/' #目标网址是某黄页网站某地区的‘首页’,从这个网址获取其他下级页面的URL
url_1 = huoqu(url,'.com',30) #调用获取函数,对‘首页’获取其中包括'.com'元素即为网址的行信息,设置时间为30S
url_2 = [] #建立一个空白的列表url_2
for a in url_1: #遍历得到的含有下级url的列表
if '名录">惠州' in a: #通过查看网页源码可以发现下级网页所在都包含有'名录">惠州',通过这个成分对信息进行一次过滤
url_2.append(a) #过滤后放入准备好的列表url_2
url_3 = [] #建立一个空白的列表url_3
for b in url_2: #遍历上一次过滤后得到的列表
C = re.split(r'"',b) #对列表元素进行切割,所有的下级url都用"双引号括起来,用split()在"所在地方切割获得单独的url
for c in C: #从这种切割后获得的列表中遍历
if '.com' in c: #如果含有 '.com'即为url,提取出来
url_3.append(c) #放入准备好的列表url_3
Xinxi = [] #建立一个空白的列表Xinxi用来放信息
for d in list(range(1,len(url_3)+1)): #建立一个列表用来表示url_3的序数并遍历这个序数列表
url_4 = url_3[d-1] #把url_3指定位置的元素给变量url_4(这里是循环放入url字符串)
xinxi = huoqu(url_4, '共收录', 30) #目标是找到某城市某行业收录了多少条公司信息,所以依据源码,对'共收录'调用获取函数
Xinxi.append(xinxi) #把获取的信息xinxi放入专门的列表Xinxi中
# 这一步用来显示系统循环的进程
sys.stdout.write('\r[ === [%d/%d] %d%% === ]' % ((d), len(url_3), int((d) /len(url_3) * 100)))
xinxi = {} #准备一个空字典xinxi,这里的信息个循环内的xinxi不一致不影响
for e in range(0,len(Xinxi)): #建立一个列表用来表示Xxinxi的序数并遍历这个序数列表
E = re.split(r'>|,str(Xinxi[e])) #对遍历到的序数位置的元素进行切割,解析源码后知道主要信息被包括在>,
#print(E)
xinxi['第'+str(e+1)+'行'] = {} #每个行业建立一个行键,显示为第几行数据
jian = re.split(r'惠州|公司',str(E[2])) #对切割后的E列表中的第三个元素按照惠州,公司两个进行再切割,得到的新列表第二个元素包含了行业名称
#print(jian)
xinxi['第'+str(e+1)+'行']['第'+str(1)+'列']=str(jian[1])#把行业名称放到当行第一列
xinxi['第'+str(e+1)+'行']['第'+str(2)+'列'] = int(E[6])#把E列表中第7个元素即收录数量放入当行第二列
for a,b in xinxi.items(): #遍历一下这个xinxi列表查看下信息是否正确
print(a,b)
#把表格字典转化成表格样式的一整个字符串 返回字符串
def write_excel(A): #创建一个转换字典为特定字符表的函数
for B,C in A.items(): #遍历表字典内的行:列键值对
Hang = int(len(A)) #获得行数
Lie = int(len(C)) #获得列数
Lie_Biao = [] #创建中转列:值对的列表
Zuizhong = [] #创建最终所有列值对字符串列表
for hhh in A.values(): #遍历表中的列字典
for lll in hhh.values(): #遍历列字典的值
Lie_Biao.append(str(lll)) #把值字符串化添加到值列表
for hangshu in range(0, Hang + 1): #定义行数为跳转步长
guodu = Lie_Biao[hangshu * Lie:hangshu * Lie + Lie] #定义按每行转化成过渡切片
jiange_1 = '\t' #定义一个制表符
meiyihang = jiange_1.join(guodu) #用制表符来连接切片中的每一列
Zuizhong.append(meiyihang) #把由每一列连起来的每一行添加到最终列表
jiange_2 = '\n' #定义一个换行符
zhenggebiao = jiange_2.join(Zuizhong) #用换行符来连接最终列表内每个行元素
return zhenggebiao #返回一个表示整个表的字符串
#把特定的字符串写入特定路径按特定名和格式保存
def save_excel(baocunduixiang,wenjianjialujing,baocunming,geshihouzhui):
baocunming = str(baocunming) #指定保存名
LUJING_NEW = wenjianjialujing + '\\' + baocunming + '.'+ geshihouzhui #拼装最终路径
f = open(LUJING_NEW, 'w',encoding='utf-8') # 在目的路径声明一个文件及格式并打开
f.write(baocunduixiang) # 把处理好的信息写入这个文件
f.close() # 关闭写入操作
huizhouqiye = write_excel(xinxi)
lujing = input("路径:")
baocun = input("保存文件名:")
save_excel(huizhouqiye,lujing,baocun,'xls')