MSSQL_7- 联接和APPLY运算符
目录
- 基本联接
- 交叉联接
- 内联接
- 外联接
- 自联接
- 多表联接
1.顺序联接
2.嵌套联接 - 联接算法
LOOP | MERGE | HASH - APPLY运算符
CROSS | OUTER APPLY
联接查询,关系数据库的主要特点,区别于其它数据库管理系统的主要标志。
将不同类型的数据存放在不同表中,可以防止产生冗余数据。
1.基本联接
1.1 语法
1.1.1 FROM子句联接
FROM table_1
join_type table_2 -- join_type 联接类型
on condition -- 联接条件
eg.
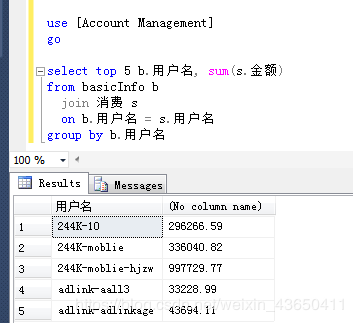
1.1.2 WHERE子句联接
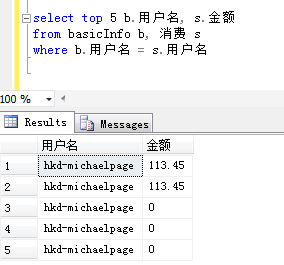
1.2 补充
- 两个表中重复存在的列名,必须通过
表名.列名的形式进行限定。另,这种限定还能提高可读性。 - 联接条件可以像指定其它库谓词一样指定其它比较运算符或关系运算符。而非仅仅适用于’=’。
- 联接条件用到的不同列,不必具有相同的名称或相同的数据类型。但如果数据类型不同,则必须兼容。如果数据类型不能隐式转换,则使用
CAST函数显示转换。
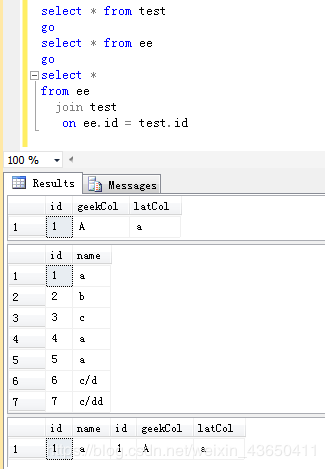
2.交叉联接(CROSS JOIN)
联接查询的第1阶段,对两个表进行笛卡尔乘积,即生成表大小为1表的行 * 2表的行。
select * from test
go
select * from ee
go
select * from test, ee -- 等效
go
select * from test CROSS JOIN ee
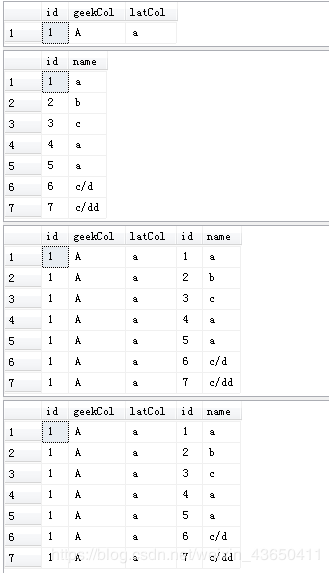
注:
- 应用1
在SELECT中使用子查询时,由于对于所引用表中的每一行理论上都要执行一次子查询,比较耗资源。可使用CROSS JOIN来优化。(编写语句时使用查询计划辅助查看优化执行结果)
3.内联接(INNER JOIN)
仅获取两个表中与联接条件匹配的记录
select *
from t1
inner join t2
on t1.col1 = t2.col2 -- <>...等
4.外联接(LEFT | RIGHT | FULL [ OUTER ] JOIN
被保留全部行的表称为保留表。
在SQL的查询逻辑中,外联接最后阶段添加外部行添加的是保留表中与联接条件不匹配的所有行。
-- LEFT 保留T1全部行
-- RIGHT 保留T2全部行
-- FULL 保留T1和T2的全部行
select *
from T1
LEFT | RIGHT | FULL [ OUTER ] JOIN T2
ON T1.col1 = T2.col2
5.自联接
除与其它表进行联接,表还可以以任意方式与自身进行联接。
eg.1 INNER JOIN
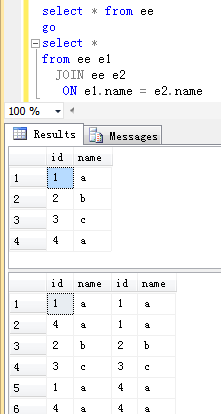
eg.2 CROSS JOIN
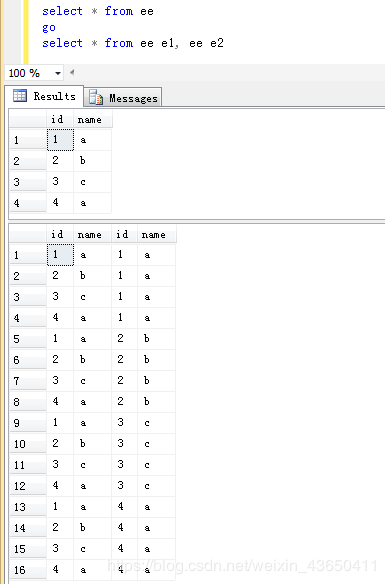
6.多表联接
可以在FROM子句中包含多个联接。但每次只联接两个表,然后再将联接结果与下一个表进行联接,因此,联接顺序不同可能产生不同的结果集。
6.1 顺序联接
按照FROM子句中联接的书写顺序依次联接。
USE tt
GO
IF OBJECT_ID('Pro', 'U') IS NOT NULL
DROP TABLE Pro
IF OBJECT_ID('Sal', 'U') IS NOT NULL
DROP TABLE Sal
IF OBJECT_ID('Spo', 'U') IS NOT NULL
DROP TABLE Spo
IF OBJECT_ID('Stock', 'U') IS NOT NULL
DROP TABLE Stock
GO
CREATE TABLE Pro
(
Pro_id INT NOT NULL,
Pro_name CHAR(20) NOT NULL,
)
CREATE TABLE Sal
(
Pro_id INT NOT NULL,
Pro_cnt INT NOT NULL
)
CREATE TABLE Spo
(
Pro_id INT NOT NULL,
Pro_cnt INT NOT NULL
)
CREATE TABLE Stock
(
Pro_id INT NOT NULL,
Pro_cnt INT NOT NULL
)
GO
INSERT INTO Pro
VALUES
(1, 'Bike-51'), (2, 'Bike-52'), (3, 'Bike-53'), (4, 'Bike-54')
INSERT INTO Sal
VALUES
(1, 100), (2, 120), (3, 130)
INSERT INTO Spo
VALUES
(1, 10), (3, 30)
INSERT INTO Stock
VALUES
(2, 20), (33, 10), (4, 100)
GO
-- 查询自行车的销量、损坏、库存
SELECT p.*
, s1.Pro_cnt salesCnt
, s2.Pro_cnt spoliatCnt
, s3.Pro_cnt stockCnt
FROM Pro p
LEFT JOIN Sal s1
ON p.Pro_id = s1.Pro_id
LEFT JOIN Spo s2
ON p.Pro_id = s2.Pro_id
LEFT JOIN Stock s3
ON p.Pro_id = s3.Pro_id
6.2 嵌套联接
最里层的联接优先执行,然后向外依次联接。
下图对比顺序联接&嵌套联接:
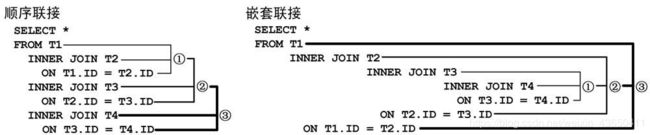
-- eg.1 顺序联接
-- 与上文使用同样的数据
-- 查询已经销售的自行车中,对应型号的损坏率
-- 损坏率 = 损坏数/(销量 + 库存 + 损坏数)
SELECT p.*
, s1.Pro_cnt saleCnt
, s2.Pro_cnt spoliatCnt
, s3.Pro_cnt stockCnt
, CONVERT(decimal(5, 2),
(ISNULL(s2.Pro_cnt, 0) * 1.
/
(ISNULL(s1.Pro_cnt, 0)
+ ISNULL(s2.Pro_cnt, 0)
+ ISNULL(s3.Pro_cnt, 0)))) spoliatRatio
FROM Pro p
LEFT JOIN Sal s1
ON p.Pro_id = s1.Pro_id
LEFT JOIN Spo s2
ON p.Pro_id = s2.Pro_id
LEFT JOIN Stock s3
ON p.Pro_id = s3.Pro_id
WHERE s1.Pro_cnt IS NOT NULL
-- eg.2 嵌套查询
SELECT p.*
, s1.Pro_cnt salesCnt
, s2.Pro_cnt spoliatCnt
, s3.Pro_cnt stockCnt
, CONVERT(decimal(5, 2),
ISNULL(s2.Pro_cnt, 0) * 1.
/
(ISNULL(s1.Pro_cnt, 0)
+ ISNULL(s2.Pro_cnt, 0)
+ ISNULL(s3.Pro_cnt, 0))) spoliatRatio
FROM Stock s3
RIGHT JOIN Spo s2
RIGHT JOIN Sal s1
RIGHT JOIN Pro p
ON p.Pro_id = s1.Pro_id
ON p.Pro_id = s2.Pro_id
ON p.Pro_id = s3.Pro_id
WHERE s1.Pro_cnt IS NOT NULL
6.3 指定联接的物理顺序(OPTION ( FORCE ORDER) )
通常情况下,查询优化器可以提供最优的执行计划。但查询优化器在执行评估计划时会考虑成本,即评估所使用的计算资源。查询优化器会评估可能的执行计划(但并不是所有方案),并选择一个成本最低的执行方案。
当我们认为执行的查询方案不是最优时,可以强制限制按语句的逻辑顺序执行。
-- 上文中 eg.2 嵌套查询
-- 对比查看
-- 图1 为查询器自由优化
-- 图2 为强制按查询顺序进行优化
SELECT *
FROM T1
JOIN T2
ON T1.col1 = T2.col2
OPTION(FORCE ORDER)
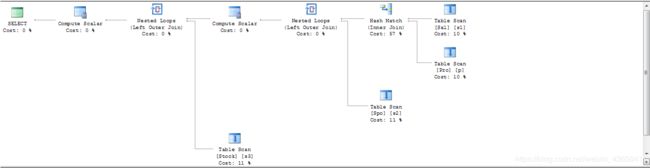

7.联接算法
7.1 嵌套循环联接
嵌套循环联接也称为“嵌套迭代”,它将一个联接输入用作外部输入表(显示为图形执行计划中的顶端输入),将另一个联接输入用作内部(底端)输入表。外部循环逐行处理外部输入表。内部循环会针对每个外部行执行,在内部输入表中搜索匹配行。简单地讲,就是扫描其中的一个联接表,并为该表中的每一行在另一个联接表中搜索匹配行。
如果外部输入较小(不到10行)而内部输入较大且预先创建了索引,则嵌套循环联接尤其有效。在许多小事务中(如那些只影响较小的一组行的事务),索引嵌套循环联接优于合并联接和哈希联接。但在大型查询中,嵌套循环联接通常不是最佳选择。
7.2 合并联接
并联接要求两个输入都在合并列上排序,合并列由联接谓词的等效(ON)子句定义。由于每个输入都已排序,因此合并联接将从每个输入获取一行并将其进行比较。例如,对于内联接操作,如果行相等则返回。如果行不相等,则废弃值较小的行并从该输入获得另一行。这一过程将重复进行,直到处理完所有的行为止。
合并联接操作可以是常规操作,也可以是多对多操作。多对多合并联接使用临时表存储行。如果每个输入中有重复值,则在处理其中一个输入中的每个重复项时,另一个输入必须重绕到重复项的开始位置。
合并联接本身的速度很快,但是如果合并列上未建立索引,选择合并联接有可能会非常费时,因为它首先要对列进行排序操作。然而,如果数据量很大且能够从索引中获得预排序的所需数据,则合并联接通常是最快的可用联接算法。
7.3 哈希联接
并联接要求两个输入都在合并列上排序,合并列由联接谓词的等效(ON)子句定义。由于每个输入都已排序,因此合并联接将从每个输入获取一行并将其进行比较。例如,对于内联接操作,如果行相等则返回。如果行不相等,则废弃值较小的行并从该输入获得另一行。这一过程将重复进行,直到处理完所有的行为止。
合并联接操作可以是常规操作,也可以是多对多操作。多对多合并联接使用临时表存储行。如果每个输入中有重复值,则在处理其中一个输入中的每个重复项时,另一个输入必须重绕到重复项的开始位置。
合并联接本身的速度很快,但是如果合并列上未建立索引,选择合并联接有可能会非常费时,因为它首先要对列进行排序操作。然而,如果数据量很大且能够从索引中获得预排序的所需数据,则合并联接通常是最快的可用联接算法。
7.4 强制联接策略
( loop | merge | hash )
-- 可单独指定联接策略
select *
from t1
inner loop | merge | hash join t2
on t1.col = t2.col
8.APPLY运算符
包含APPLY的查询分为左右两部分,对左表表达式返回的每一行都要调用一次右表表达式进行计算。右表表达式可以是一个相关子查询,或表值函数。
CROSS APPLY -- 类似于内部联接,返回右表达式能够生成结果集的行
OUTER APPLY -- 类似左外联接
use tt
go
CREATE TABLE Emp
(
emp_id int NOT NULL,
dept_id int NULL,
emp_name varchar(20) NOT NULL,
salary int NOT NULL,
CONSTRAINT PK_emp PRIMARY KEY(emp_id)
)
GO
INSERT INTO Emp
VALUES
(1, NULL, 'Nancy', $1000.00), (2, 1, 'Andrew', $5000.00),
(3, 1, 'Janet', $5000.00), (4, 1, 'Margaret', $5000.00),
(5, 2, 'Steven', $2500.00), (6, 2, 'Michael', $2500.00),
(7, 3, 'Robert', $2500.00), (8, 3, 'Laura', $2500.00),
(9, 3, 'Ann', $2500.00), (10, 4, 'Ina', $2500.00),
(11, 7, 'David', $2000.00), (12, 7, 'Ron', $2000.00),
(13, 7, 'Dan', $2000.00), (14, 11, 'James', $1500.00)
GO
CREATE TABLE Dept
(
dept_id int NOT NULL PRIMARY KEY,
dept_name varchar(25) NOT NULL
)
GO
INSERT INTO Dept
VALUES
(1, 'HR'), (2, 'Marketing'), (3, 'Finance'), (4, 'R&D'),
(5, 'Training'), (6, 'Gardening')
GO
CREATE FUNCTION dbo.fn_getDeptEmp(@dept_id int)
RETURNS TABLE
AS
RETURN
SELECT emp_id, emp_name, salary
FROM Emp
WHERE dept_id = @dept_id
GO
SELECT D.dept_name, E.emp_id, E.emp_name, E.salary
FROM Dept D
CROSS APPLY fn_getDeptEmp(D.dept_id) E
--OUTER APPLY fn_getDeptEmp(D.dept_id) E
-- 等价
SELECT *
FROM Dept D
CROSS APPLY ( SELECT *
FROM Emp E
WHERE E.dept_id = D.dept_id
) E
SELECT *
FROM Dept D
JOIN ( SELECT *
FROM Emp
) E
ON D.dept_id = E.dept_id