深度相机哪家强?
深度相机哪家强?
原文:https://zhuanlan.zhihu.com/p/28274727
深度相机的坑
原文:https://blog.csdn.net/lxy_2011/article/details/84390511
机器视觉-kinect
原文:https://blog.csdn.net/l297969586/article/details/52535986
随着机器视觉、自动驾驶、机器人的火爆,采用深度相机采集环境的深度信息然后进行物体识别、环境建模等越来普遍;相对于传统2D相机,3D相机增加了一维的深息,因而,能够更好的对真实世界进行描述;在许多领域如安防、监控、机器视觉、机器人等,拓展了更多的可能;如自动驾驶中的物体识别和障碍物检测,工业中散乱码放物体的识别、分拣、拆垛、码垛,物流场景中物体的货架抓取等等。
深度相机,顾名思义,指的是可以测量物体到相机距离(深度)的相机,如微软的Kinect, Kinect 2, Intel 的 RealSense甚至包括激光雷达也可以归为深度相机。
从原理上来讲,深度相机测量深度主要分为两大类:
1) 基于特征匹配的深度测量原理,如基于红外散斑结构光原理的Kinect 1, 基于红外条纹结构光的Intel RealSense, 基于可见条纹结构光的Enshape,甚至单纯采用双目视觉的BumbleBee等等;上述几类相机无论采用哪种结构光或者不采用结构光,其最终计算深度时本质上采用的均可以看作是特征匹配的方法;
2) 基于反射时间的深度测量原理,如Kinect 2.0, MESA 的 SR4000,SR4500,Google Project Tango 采用的PMD Tech 的相机 ,Intel 的 SoftKinect DepthSense 甚至包括无人驾驶领域L3和L4的分水量激光雷达等等;上述几类相机在计算深度信息时无一例外地均采用发射光与反射光之间的时间差计算深度;
下面分别对基于特征匹配的深度测量原理以及基于反射时间的深度测量原理进行详细的描述;
基于特征匹配的深度测量原理
无论是主动投影光斑的结构光深度相机还是基于被动双目视觉原理的深度相机,其本质上均为首先对投影仪投射的光斑与相机之间拍摄图像(或双相机拍摄图像)进行特征匹配,然后在此基础上基于三角测量原理(通过测量三角形3条边3个角中的三个量:如角边角,边角边等计算其余三个量)计算特征点距离相机的距离。如下图所示:
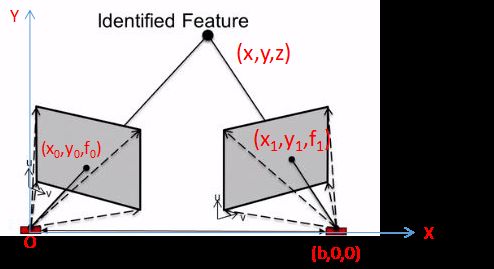
上图中O所在位置为Projector光源所在位置或者双目视觉中左相机光心,(b,0,0)所在位置为右相机光心;(x0,y0,f0)和(x1,y1,f1)分别为特征点在左相机像平面和右相机相平面中的投影;
根据成像原理,O,(x0,y0,f0),(x,y,z)共线,O,(x1,y1,f1),(x,y,z)g共线;
根据射影原理:
根据上述两式便可以计算得到:
根据上述原理,在特征点已经匹配的基础上,无论是主动投影结构光深度相机还是纯被动双目相机,均可以计算出特征点的深度信息;
然而,特征点的匹配并不是一件非常简单的事情,尤其是纯双目视觉中特征点的匹配,涉及到非常复杂的计算过程;
a) 主动投射结构光深度相机;
为了更加简单方便的对匹配特征点,许多学者和公司采用主动投影方法,提出了多种不同的方案,如投射激光散斑、投射可见光条纹、投射激光条纹、投射包含颜色信息的编码条纹等等;甚至有学者提出使用一个简单的金属杆模拟激光线条等,方法不一而足,但组中目的都是为了能够简单快速的匹配特征点;

各种不同的特征
上述基于主动投射光源的深度相机,由于特征经过特殊设计,因而,特征的提取与匹配非常简单;同时,经过合理的设计,能够在一定范围内达到较高的精度,因而,在实际应用中使用相对较多,如Kinect 1.0, Intel RealSense, Enshape, Ensenso等,采用的均为主动投射光源的x方案;但,同时,可以想见,在投射光源的特征固定的情况下,物体距离相机越远,光斑越大,因而,相对应的测量精度越差,即相机精度随着距离的增大而大幅降低;因而,基于主动投影的深度相机往往在测量距离较近时应用较多;
另外,基于主动投射光源的深度相机,由于存在外部光源,因而非常适合在黑暗环境中使用;但如果应用在室外环境中,则对主动投射光源的功率有较高要求;常见的低成本的结构光相机如Kinect 1.0, Intel RealSense, Ensenso在室外强光环境中均为产生较大的测量误差;采用较大功率的主动投射光源则意味着成本的大大增加;
再者,基于主动投射光源的深度相机,由于主动投射光影,因而,反光平面的影响不可避免;如果投射的为大面积的散斑结构光,那么不可避免的会在反光平面产生比较大的干扰;如果投射光源为线激光、条纹结构光等,影响相对较小,但同样不可避免;总而言之,采用主动投射光源的深度相机,反光影响肯定存在,但可以通过合理的设计降低其影响;
b) 被动双目深度相机
被动双目深度相机不对外投射光源,类似人类双眼不布置,通过两个位置已经标定好的2D相机观察同一环境,然后再拍摄到两幅图像根据图像内容进行特征点匹配,进而计算深度。由于不存在任何先验知识,仅依赖于环境图像进行特征匹配,因而,被动双目立体视觉方案比较适合用于光线良好、图像特征比较丰富的领域;
由于直接采用环境光采集图像,因而,其非常适合于室外环境中使用,在室内环境中使用时,则需要外部光源的辅助;同时,反光的影响大大降低;
对于一些图像特征非常不明显的领域,如平整的地面,一望无际的沙漠等,采用双目视觉进行匹配,则相对比较困难;
采用纯被动双目视觉目前最大的问题在于,分别基于两幅图像,从图像中寻找特征点,进一步的进行特征匹配,整个过程中需要大量异常复杂的算法,巨大的计算量,并且最终的计算结果并不稳定。
就目前来看,被动双目深度相机目前还正处在产品应用与开发的早期阶段,一些公司推出的如STEROLABS 推出的 ZED 2K Stereo Camera, Point Grey 公司推出的 BumbleBee,以及一些国内创业公司推出的一系列被动双目相机,目前还都处于实验结果,距离稳定可靠的产品以及大规模的应用还具有一定的距离。

基于反射时间长度的深度测量方法
反射时间测量原理(Time of Flight, 简称TOF)通过 将调制光源投射到被观测物体上,然后观察反射光与入射光之间的时间差计算物体到相机的距离。如下图所示:
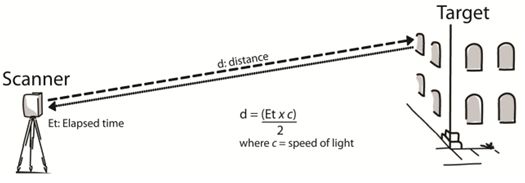
TOF相机原理
TOF相机中包含一个激光发生器和一个由光敏而激光或雪崩二极管组成的感光单元,如上图所示,激光发生器发射激光后,遇到障碍物反射回来,相机中的感光单元感受到反射光后,计算出激光从发射出去到接收到反射光所需的时间,进而根据飞行时间乘以光速得到障碍物距离相机的距离。
为了测量入射光与反射光之间的时间差,一般将光源调制为连续脉冲光源,如下图:

即如上图所示,正弦波脉冲TOF相机通过向场景平面发射一束调制频率为 正弦波信号,入射信号被场景表面反射并被传感器吸收。当信号到达被接收后,由于能量衰减,其振幅衰减,并且产生一个相位延迟,记作 根据相位延迟,便可以计算得到入射信号与反射信号的时间差,进而计算环境的深度值;
上述正弦波脉冲方法基于亮度调制光源的相位长度测量时间差,方法较为成熟,是目前主流的方案,但此方法中芯片较大,因而只能工作在较低分辨率下工作;
对于方波脉冲TOF相机,首先相机上的控制单元打开光源然后关闭,形成一束光脉冲,在同一时刻,控制单元打开芯片上的电子快门 ,由光脉冲产生的电荷存储在芯片上Q0;然后,在光源被关闭的时刻,打开快门S1,由光脉冲产生的电荷也被存储在芯片上,记作Q1;
然后,根据Q0,Q1的数值便可以计算入射光与反射光的延迟时间,进而计算环境的深度值:
2) 基于反射时间的深度测量原理,如Kinect 2.0, MESA 的 SR4000,SR4500,Google Project Tango 采用的PMD Tech 的相机 ,Intel 的 SoftKinect DepthSense 甚至包括无人驾驶领域L3和L4的分水量激光雷达等等;上述几类相机在计算深度信息时无一例外地均采用发射光与反射光之间的时间差计算深度,其差别仅仅在于发射的波不同而已;
上述方波脉冲TOF相机根据单脉冲的传播时间测量距离,因而,需要非常快速和精确的电子元件,但同时也可以达到较高的精度和分辨率,代表当前的最高水平。
值得注意的是,TOF相机对上述时间测量的精度要求非常高,即使相机的电子快门打开仅仅比预期的时间晚了33ps,那么计算出的距离也已经短了1cm,因而,即使采用最高精度的电子元器件,TOF相机也很难达到mm级的精度,这也限制了其在一些高精度领域的应用。
但根据上述原理可以看出,由于通过反射时间测量距离,因而,TOF相机可以通过调节发射脉冲的频率改变相机测量距离,因而,在测量距离要求比较大的场合,如无人驾驶领域的激光雷达,TOF相机具有非常明显的优势;
同时,与基于特征匹配的深度相机不同,TOF相机的精度不会随着测量距离的增大,误差增大,其测量误差在整个测量范围内基本上是固定的;
就目前来看,在近距的应用领域,许多公司已经基于TOF原理推出了一些列商用的产品,如微软的Kinect 2.0, MESA 的 SR4000 , Google Project Tango 中使用的PMD Tech 的TOF相机,Intel 的 SoftKinect DepthSense, Basler基于松下的芯片开发的TOF相机以及国内一些初创公司基于TI的方案开发的TOF相机等等;这些产品已经在民用的体感识别,环境建模等领域取得了大量应用;但总的来说,在近距测量领域,尤其是1m左右范围内,TOF相机的精度与基于特征匹配的精度还具有较大的差距,从而限制了其在一个高精度领域的应用。

在远距的应用领域,如无人驾驶中的激光雷达等,目前基本上所有的方案都是基于TOF原理,基于TOF原理的深度测量方法在远距领域具有明显的优势。

激光雷达
综上所属,常用的三种类型的深度相机:基于主动投射结构光的深度相机、被动双目相机以及TOF相机,其主要优缺点总结如下:

在实际应用中,应该首先确定测量范围与测量精度要求:如果测量范围较大,优先选择TOF类相机;如果测量范围较小,优先选择主动投射结构光类相机,然后根据精度要求选择不同的投射方案;如果外界环境不允许投射光线或者具有良好的外界环境光,可以选用被动双目视觉方案;
最后,强行安利一波,梅卡曼德机器人基于 3D视觉的机器人混杂分拣解决方案,可用于分拣、拆垛、码垛、上下料等应用。基于先进的算法,梅卡曼德智能分系统在保证工作节拍和可靠性的前提下,价格比市场上常见方案低一个数量级。技术详解详见媒体报道:梅卡曼德技术详解:如何做出一个智能机器人。
三种主流深度相机介绍
原文:https://www.cnblogs.com/li-yao7758258/p/11191878.html
三种主流深度相机介绍
随着机器视觉,自动驾驶等颠覆性的技术逐步发展,采用 3D 相机进行物体识别,行为识别,场景 建模的相关应用越来越多,可以说深度相机就是终端和机器人的眼睛,那么什么是深度相机呢,跟之前的普通相机(2D)想比较,又有哪些差别? 深度相机又称之为3D相机,顾名思义,就是通过该相机能检测出拍摄空间的景深距离,这也是与普通摄像头最大的区别。
普通的彩色相机拍摄到的图片能看到相机视角内的所有物体并记录下来,但是其所记录的数据不包含这些物体距离相机的距离。仅仅能通过图像的语义分析来判断哪些物体离我们比较远,哪些比较近,但是并没有确切的数据。而 深度相机则恰恰解决了该问题,通过深度相机获取到的数据,我们能准确知道图像中每个点离摄像头距离,这样加上该点在 2D 图像中的(x,y)坐标,就能获取图像中每 个点的三维空间坐标。通过三维坐标就能还原真实场景,实现场景建模等应用。
深度相机的方法分类如下表所示:

目前市面上常有的深度相机方案有以下三种。
(1)结构光(Structured-light),代表公司有奥比中光,苹果(Prime Sense),微软 Kinect-1,英特尔 RealSense, Mantis Vision 等。
(2)双目视觉(Stereo),代表公司 Leap Motion, ZED, 大疆;
(3)光飞行时间法(TOF),代表公司微软 Kinect-2,PMD,SoftKinect, 联想 Phab。
当然还有光场相机,有兴趣可以关注微信公众号文章
以下具体介绍几种这三种深度相机的原理:
结构光深度相机
结构光,英文叫做 Structured light,其原理是基本原理是,通过近红外激光器,将具有一定结构特征的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。这种具备一定结构的光线,会因被摄物体的不同深度区域,而采集不同的图像相位信息,然后通过运算单元将这种结构的变化换算成深度信息,以此来获得三维结构。简单来说就是,通过光学手段获取被拍摄物体的三维结构,再将获取到的信息进行更深入的应用。通常采用特定波长的不可见的红外激光作为光源,它发射出来的光经过 一定的编码投影在物体上,通过一定算法来计算返回的编码图案的畸变来得到物体的位置和深度信息。根据编码图案不同一般有:
条纹结构光,代表传感器 enshape ,
编码结构光,代表传感器 Mantis Vision, Realsense(F200),
散斑结构光 ,代表传感器 apple(primesense), 奥比中光。
下图是一个典型的结构光相机的示意图:
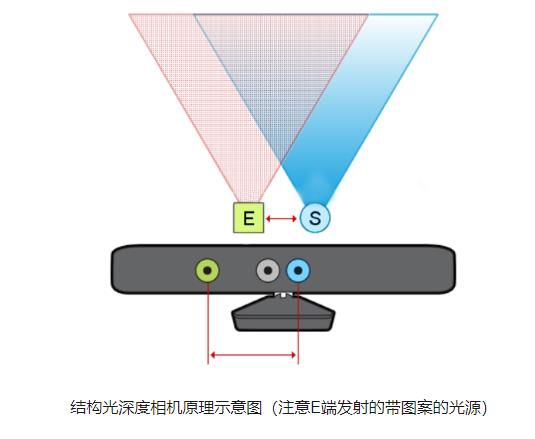

结构光(散斑)的优点主要有:
1)方案成熟,相机基线可以做的比较小,方便小型化。
2)资源消耗较低,单帧 IR 图就可计算出深度图,功耗低。
3)主动光源,夜晚也可使用。
4)在一定范围内精度高,分辨率高,分辨率可达 1280x1024,帧率可达 60FPS。
散斑结构光的缺点与结构光类似:
1)容易受环境光干扰,室外体验差。
2)随检测距离增加,精度会变差。

目前结构光技术有如下几种变种:一种是单目IR+投影红外点阵,另外一种是双目IR+投影红外点阵,这样相当于结构光+双目立体融合了,深度测量效果会比前者好一些,比如Intel RealSense R200采用的就是双目IR+投影红外点阵,不足之处就是体积较大。而单目IR+投影红外点阵的方案虽然体积较小,但是效果会差一点。
TOF
顾名思义是测量光飞行时间来取得距离,具体而言就是通过给目标连续发射激光脉冲,然后用传感器 接收从反射光线,通过探测光脉冲的飞行往返时间来得到确切的目标物距离。因为光速激光,通过直接测 光飞行时间实际不可行,一般通过检测通过一定手段调制后的光波的相位偏移来实现。 TOF 法根据调制方法的不同,一般可以分为两种:脉冲调制(Pulsed Modulation)和连续波调制 (Continuous Wave Modulation)。脉冲调制需要非常高精度时钟进行测量,且需要发出高频高强度激光,目 前大多采用检测相位偏移办法来实现 TOF 功能。简单来说就是,发出一道经过处理的光,碰到物体以后会反射回来,捕捉来回的时间,因为已知光速和调制光的波长,所以能快速准确计算出到物体的距离。
其原理示意图:

因为 TOF 并非基于特征匹配,这样在测试距离变远时,精度也不会下降很快,目前无人驾驶以及一些高 端的消费类 Lidar 基本都是采用该方法来实现。 TOF 的优点主要有:
1)检测距离远。在激光能量够的情况下可达几十米。
2)受环境光干扰比较小。
但是 TOF 也有一些显而易见的问题:
1)对设备要求高,特别是时间测量模块。
2)资源消耗大。 该方案在检测相位偏移时需要多次采样积分,运算量大。
3)边缘精度低。
4)限于资源消耗和滤波,帧率和分辨率都没办法做到较高。
目前消费类最大也就 VGA。 从上面三种主流的 3D 相机成像方案来看,各有优劣,但是从实际应用场景来看,在非无人驾驶领域,结构 光,特别是散斑结构光的用途是最广泛。因为从精度,分辨率,还有应用场景的范围来看双目和 TOF 都没 有办法做到最大的平衡。而且对于结构光容易受环境光干扰,特别是太阳光影响问题,鉴于此类相机都有 红外激光发射模块,非常容易改造为主动双目来弥补该问题。

结构光与TOF的对比
对比来看,结构光技术功耗更小,技术更成熟,更适合静态场景。而TOF方案在远距离下噪声较低,同时拥有更高的FPS,因此更适合动态场景。
目前,结构光技术主要应用于解锁以及安全支付等方面,其应用距离受限。而TOF技术主要用于智能机后置摄影,并在AR、VR等领域(包括3D拍照、体感游戏等)有一定的作用。

3D结构光和TOF两者其实各有优劣势。结构光最大的优势是发展的较为成熟,成本比较低,劣势是只适合中短距离使用。ToF优势是抗干扰性较好,视角较宽,缺陷是功耗高,造价贵,精度及深度图分辨率较低。两项技术各有侧重点和适配使用场景。
双目立体视觉
双目立体视觉(Binocular Stereo Vision)是机器视觉的一种重要形式,他是基于视差原理并利用成像设备 从不同的位置获取被测物体的两幅图像,通过计算图像对应点间的位置偏差,来获取物体三维几何信息的 方法。
当然完整的双目深度计算非常复杂,主要涉及到左右相机的特征匹配,计算会非常消耗资源。 双目相机的主要优点有:
1)硬件要求低,成本也低。普通 CMOS 相机即可。
2)室内外都适用。只要光线合适,不要太昏暗。
但是双目的缺点也是非常明显:
1)对环境光照非常敏感。光线变化导致图像偏差大,进而会导致匹配失败或精度低
2)不适用单调缺乏纹理的场景。双目视觉根据视觉特征进行图像匹配,没有特征会导致匹配失败。
3)计算复杂度高。该方法是纯视觉的方法,对算法要求高,计算量较大。
4)基线限制了测量范围。测量范围和基线(两个摄像头间距)成正比,导致无法小型化。
三种深度相机的对比

以上就是全部内容,可能存在一些错误欢迎指示,并可以发邮件交流,您可以可以关注微信公众号。加入我们翻译小组或者加入经营微信公众号群,也加入技术交流群与跟多的小伙伴一起交流。