Ubantu系统和TensorFlow安装完整教程
ubuntu16.04
软碟通的使用
左下角点中u盘
文件-打开-ubuntu安装文件
启动-写入硬盘映像
写入方式-HDD+
便携启动-这个自己查吧,好像是Syslinux
镜像地址 https://www.ubuntu.com/download/alternative-downloads
这里的版本什么都不要动,别下最新版,就这个版本,安装文件下载run文件,别下deb文件。
CUDA 8.0
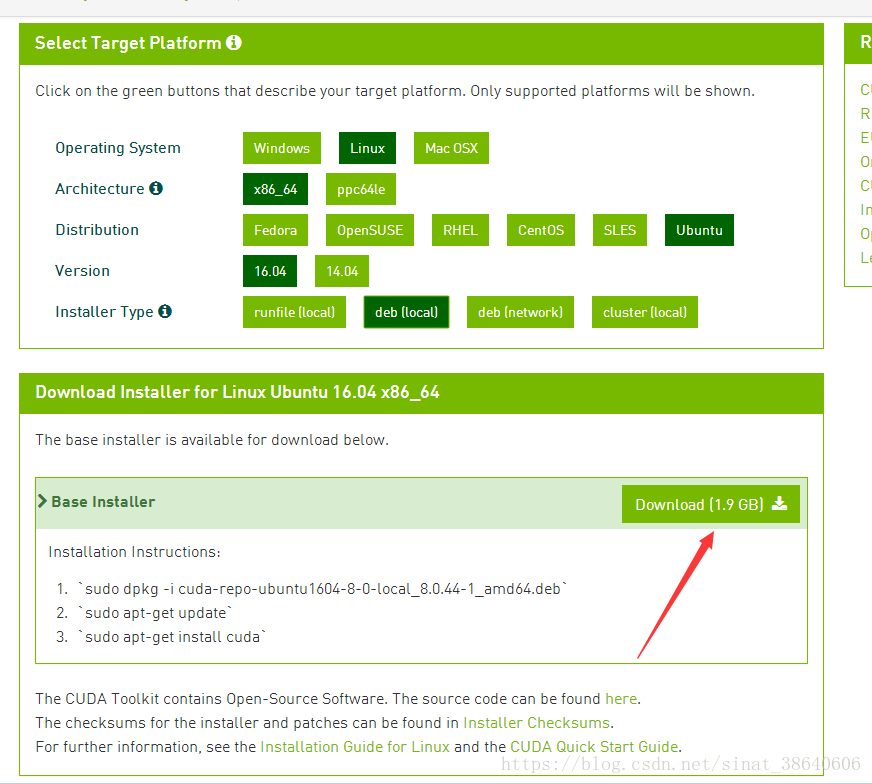
cuDNN v5

1.安装ubuntu16.04 LTS 系统
下载系统文件以后用软碟通考进U盘里面,这里要设置两个,注意注意
写入方式:USB-ZIP+
便捷启动:写入新的硬盘主引导记录(MBR)-USB-ZIP+
刚开机的时候按del或者F2,选U盘的时候,两个一样的U盘,选没有uefi文字更少的那一个
安装,什么都不选,其他
/给10g以上,安装系统的,主分区
boot没多少,1g足够,主分区
swap给16g或者更少,逻辑分区
剩的全是home,逻辑分区
剩下的没有选择全是安装,慢慢等。
2. 安装NVIDIA驱动
安装驱动之前,一个很重要的工作,在开机启动的时候按住f10进入bios界面,系统设置-传统启动enable安全启动disable
这个极其之重要,把安全启动关了。惠普的本子按住f10保存之后,还有什么数字然后回车确认。反正这个安全启动不关怎么都是错。
1. 先卸载原有N卡驱动
#for case1: original driver installed by apt-get:
sudo apt-get remove --purge nvidia*
#for case2: original driver installed by runfile:
sudo chmod +x *.run
sudo ./NVIDIA-Linux-x86_64-384.59.run --uninstall如果原驱动是用apt-get安装的,就用第1种方法卸载。
如果原驱动是用runfile安装的,就用–uninstall命令卸载。其实,用runfile安装的时候也会卸载掉之前的驱动,所以不手动卸载亦可。
2. 禁用nouveau驱动
sudo gedit /etc/modprobe.d/blacklist.conf在文本最后添加:(禁用nouveau第三方驱动,之后也不需要改回来)
blacklist nouveau
options nouveau modeset=0然后执行:sudo update-initramfs -u
重启后,执行:lsmod | grep nouveau。如果没有屏幕输出,说明禁用nouveau成功。
3. 禁用X-Window服务
sudo service lightdm stop #这会关闭图形界面,但不用紧张
大坑在这,关闭图形界面之前,看一下自己的驱动安装程序放在哪,对着文件夹点击右键属性能看见。
然后进入命令行,用cd一步一步进入然后再输命令
按Ctrl-Alt+F1进入命令行界面,输入用户名和密码登录即可。
安装的过程中有很多的选择问题,这里没记录,上网查一下。
小提示:在命令行输入:
sudo service lightdm start,然后按Ctrl-Alt+F7即可恢复到图形界面。
4. 命令行安装驱动
#给驱动run文件赋予执行权限:
sudo chmod +x NVIDIA-Linux-x86_64-384.59.run
#后面的参数非常重要,不可省略:
sudo ./NVIDIA-Linux-x86_64-384.59.run –-no-opengl-files --no-x-check –-no-nouveau-check(大坑!!!!)--no-opengl-files:表示只安装驱动文件,不安装OpenGL文件。这个参数不可省略,否则会导致登陆界面死循环,英语一般称为”login loop”或者”stuck in login”。(no前面是双杠!!!!!)--no-x-check:表示安装驱动时不检查X服务,非必需。--no-nouveau-check:表示安装驱动时不检查nouveau,非必需。-Z, --disable-nouveau:禁用nouveau。此参数非必需,因为之前已经手动禁用了nouveau。-A:查看更多高级选项。
必选参数解释:因为NVIDIA的驱动默认会安装OpenGL,而Ubuntu的内核本身也有OpenGL、且与GUI显示息息相关,一旦NVIDIA的驱动覆写了OpenGL,在GUI需要动态链接OpenGL库的时候就引起问题。
按照如下步骤安装
(1)Accept
(2)contiuned install
(3) Unable to find a suitable destination to install 32-bit compatibility libraries. Your system may not be set up for 32-bit compatibility. 32-bit compatibility files will not be installed; if you wish to install them, re-run the installation and set a valid directory with the --compat32-libdir option.
然后这里也没什么事,直接继续就可以了,想要解决的话,也可以尝试一下安装下面的东西(没试过)
sudo optitude install ia32-libs(4)would you like to run the nvidia-xconfig utility to automatically update your X configuration file so that the NVIDIA X driver will be used when you restart X ? Any pre-existing X configuration file will be backed up
直接选择 NO,意思是安装驱动时不检查X服务
(5) Installation of the NVIDIA Accelerated Graphics Driver for Linux-x86_64(version:390.25) is now complete. Please update your XF86Config or xorg.conf file as appropriate;see the file
/usr/share/doc/NVIDIA_GLX-1.0/README.txt for details.
只有一个选项,选择Ok就行了。
然后键入重启
sudo reboot
最后重新启动图形环境
$sudo service lightdm start之后,按照提示安装,成功后重启即可。
如果提示安装失败,不要急着重启电脑,重复以上步骤,多安装几次即可。
Driver测试:
nvidia-smi #若列出GPU的信息列表,表示驱动安装成功
nvidia-settings #若弹出设置对话框,亦表示驱动安装成功
3. 安装CUDA
sudo chmod +x cuda_8.0.61_375.26_linux.runsudo ./cuda_8.0.61_375.26_linux.run --no-opengl-libs
--no-opengl-libs:表示只安装驱动文件,不安装OpenGL文件。必需参数,原因同上。注意:不是-no-opengl-files。- 这之后它显示more(0百分之),按q弹出选项栏继续
之后,按照提示安装即可。我依次选择了:
accept #同意安装
n #不安装Driver,因为已安装最新驱动
y #安装CUDA Toolkit
#安装到默认目录
y #创建安装目录的软链接
n #不复制Samples,因为在安装目录下有/samples
CUDA Sample测试:(很可能要装完环境变量才能用)
#编译并测试设备 deviceQuery:
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
#编译并测试带宽 bandwidthTest:
cd ../bandwidthTest
sudo make
./bandwidthTest如果这两个测试的最后结果都是Result = PASS,说明CUDA安装成功啦。
gcc降版本不知道用不用
安装完毕后,再声明一下环境变量,并将其写入到 ~/.bashrc 的尾部,终端输入:sudo gedit ~/.bashrc ,在打开的文档末尾插入如下内容保存即可。
export PATH=/usr/local/cuda-8.0/bin\${PATH:+:\${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\${LD_LIBRARY_PATH:+:\${LD_LIBRARY_PATH}}
安装cuDNN(自己目前安的是5)
如何安装cudnn
首先说一下网上大多数中文安装cuDNN教程的错误方式,这种方式真的坑人无数。
简单地说网上的大多错误的安装cuDNN的方式都是将下载后的cuDNN压缩包解压。然后再将cudnn的头文件(cuda/include目录下的.h文件)复制到cuda安装路径的include路径下,将cudnn的库文件(cuda/lib64目录下的所有文件)复制到cuda安装路径的lib64路径下。这种方法如果不重置cuDNN相应的符号链接的话是不能成功的安装cuDNN的。
下面我们说一下正确的安装cuDNN方式,其实跟着官方安装说明进行安装就可以了。
-
从https://developer.nvidia.com/cudnn上下载cudnn相应版本的压缩包(可能需要注册或登录)。
-
如果这个压缩包不是.tgz格式的,把这个压缩包重命名为.tgz格式。解压当前的.tgz格式的软件包到系统中的任意路径(这个路径很重要,以下将该路径的绝对路径简称为/your/path/to/cudnn),解压后的文件夹名为cuda,文件夹中包含两个文件夹:一个为include,另一个为lib64。
例如:我将这个压缩包解压在了/usr/local目录下,那么该文件的绝对路径为/usr/local/cuda -
将解压后的文件中的lib64文件夹关联到环境变量中。这一步很重要。
cd ~
sudo gedit .bashrc在弹出的gedit文档编辑器(.bashrc中)中最后一行加入:
export LD_LIBRARY_PATH=/your/path/to/cudnn/lib64:$LD_LIBRARY_PATH其中/your/path/to/cudnn/lib64是指.tgz解压后的文件所在路径中的lib64文件夹。
保存更改的文件后,紧接着:
source .bashrc再重启一下Terminal(终端),该步骤可以成功的配置cuDNN的Lib文件。
配置cuDNN的最后一步就是将解压后的cuDNN文件夹(一般该文件名为cuda)中的include文件夹(/your/path/to/cudnn/include)中的cudnn.h文件拷贝到/usr/local/cuda/include中,由于进入了系统路径,因此执行该操作时需要获取管理员权限。
打开终端,进入/your/path/to/cudnn/include。其中/your/path/to/cudnn/include指的是.tgz解压后的文件所在路径中的include文件夹。例如:
cd cuda/include
sudo cp *.h /usr/local/cuda/include/其中这里的cuda/include对于我自己的安装来说就是/your/path/to/cudnn/include。因为我将cudnn的.tgz压缩包解压到了home的当前用户的路径下,解压后的文件夹名为cuda。
之后,再重置cudnn.h文件的读写权限:
sudo chmod a+r /usr/local/cuda/include/cudnn.h至此,cuDNN的配置就全部安装完成了。
一、安装Anaconda
主要参考:https://docs.anaconda.com/anaconda/install/linux
1.1 从清华大学开源软件网站上选择合适的源文件并下载,
这里的Anaconda和python是有对应关系的,如果要python3.5的话,Anaconda要3-4.2.0,只要Anaconda不用最新版本,根本谈不上什么python降级的问题嘛。(后补)
1.2 在终端terminal中运行bash ~/path/sourcename,即自动进行安装,过程下会有进行选择,不懂的情况下enter“Yes”。
其中path为对应源文件所在路径,本人的为下载目录,path=‘下载’(中文系统);sourcename为源文件名称,在此为sourcename=‘Anaconda3-5.0.1-Linux-x86_64.sh’。运行命令如下:
bash ~/Download/Anaconda3-5.0.1-Linux-x86_64.sh- 1
1.3验证安装是否成功:
python
>>>import numpy #查看是否能够运行,numpy为anaconda内置python库。python一定要换源下载。
三、升级pip版本
在装tensorflow之前,不管是不是最新的pip版本,都要更新一下,具体命令如下:
[plain] view plain copy
- python 2.7版本:sudo pip install --upgrade pip
- python 3.x版本:sudo pip3 install --upgrade pip
四、更改pip源地址(提高下载速度)
在主目录下创建.pip文件夹(对应在自己的电脑上也就是Home,download的上一层)
mkdir ~/.pip
修改 ~/.pip/pip.conf (没有就创建一个文件夹及文件,文件夹要加".",表示是隐藏文件夹),内容如下:
[plain] view plain copy
- [global]
- index-url = https://pypi.tuna.tsinghua.edu.cn/simple
- [install]
- trusted-host=mirrors.aliyun.com
五、GCC降版本
其实,在ubuntu上安装老版gcc十分简单,直接用apt-get命令下载即可。
第一步:
sudo apt-get install gcc-4.8输入密码,同意安装,接下来就自动下载安装4.8.5版本了。
第二步:设置默认的gcc版本
gcc --version(可选)查看当前版本,不出意外的话会返回ubuntu16.04自带的5.4.0这个版本号,现在使用gcc命令编译时还是会用新版本。
ls /usr/bin/gcc*(可选)查看已有的gcc版本,确认一下刚才4.8.5有没有装成功。
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.8 100将某个版本加入gcc候选中,最后的数字是优先级,我自己是直接设为100,没任何问题。
此时在运行gcc --version查看版本,发现4.8.5已经为默认的gcc版本。
conda换源,打开控制台 ,更换清华源(墙太高)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes3.创建一个名yang的环境
conda create -n yang python=3.5这里创建conda环境就是因为pythohn3.6的版本和tensorflow有冲突,所以把python的版本降到3.5
创建成功
激活环境
source activate yang
六、安装TensorFlow
这里有两个python,sudo执行的是系统自带的原装版本,不加sudo直接python用的是anaconda的python,那就不加sudo吧
真正执行版本:
pip install scikit-learn scikit-image
pip install tensorflow-gpu==1.2.1 # GPU加速版
pip install keras
在终端中验证是否安装成功:
import tensorflow
import keras
如果不报错,即配置成功!
这里还有另一个坑,就是tensorflow的版本也是有限制的,目前实验成功的是tensorflow-gpu1.2.1
总结一下全部的版本
cuda8.0, cudnn5.1, python3.5, tensorflow1.2.1
六、测试安装结果
进入python编译环境,导入TensorFlow,做一个简单的加法运算,如图2所示。
