爬虫篇(2)使用pyexecjs破解js中cookies
首先下载pyexecjs:
pip install PyExecJS 如果有需要,自行下载PyV8 , Node.js , PhantomJS等
使用参考:https://github.com/doloopwhile/PyExecJS
PyExecJS文档:https://pypi.org/project/PyExecJS/
此次采集链接:http://www.landchina.com/default.aspx?tabid=226
直接请求:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests
url = 'http://www.landchina.com/default.aspx?tabid=226'
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
}
html = requests.get(url, headers=headers, verify=False)
print("txte:",html.text)
with open('数据2.html', 'w',encoding='utf8') as f:
f.write(str(html.text) + '\n')
print("数据.html保存完毕!")打开'数据2.html',获取js数据:
可以看到document.cookie=******************,这个就是js设置cookies的代码
使用PyExecJS执行stringToHex()函数看看,代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import execjs
jstext = '''
function stringToHex(str){var val="";for(var i = 0; i < str.length; i++){if(val == "")
val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;}
'''
ctx = execjs.compile(jstext)# 编译JS代码
a = ctx.call("stringToHex","9999")
print(a)或者使用nodejs
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import execjs
import execjs.runtime_names
jstext = '''
function stringToHex(str){var val="";for(var i = 0; i < str.length; i++){if(val == "")
val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;}
'''
node = execjs.get(execjs.runtime_names.Node)
ctx = node.compile(jstext)# 编译JS代码
a = ctx.call("stringToHex","9999")
print(a)执行结果:

执行js成功,未完待续。。。。
继续执行YunSuoAutoJump()函数:
node = execjs.get(execjs.runtime_names.Node)
ctx = node.compile(jstext)
a = ctx.call("YunSuoAutoJump",)报错:execjs._exceptions.ProgramError: ReferenceError: screen is not defined
screen未发现,screen是window的对象,发现未配置PhantomJS(参考:js逆向解密之网络爬虫+phantomjs 安装教程+下载PhantomJS)
配置好PhantomJS编译环境,并修改其js后执行代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import execjs,os
import execjs.runtime_names
# os.environ["EXECJS_RUNTIME"] = "Node"
print("当前环境:",execjs.get().name) # this value is depends on your environment.
jstext = '''
function stringToHex(str){var val="";for(var i = 0; i < str.length; i++){if(val == "")
val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;}
function YunSuoAutoJump(){ var width =screen.width; var height=screen.height; var screendate = width + "," + height;
var curlocation = window.location.href;if(-1 == curlocation.indexOf("security_verify_")){
document.cookie="srcurl=" + stringToHex(window.location.href) + ";path=/;";
fcookie="srcurl=" + stringToHex(window.location.href) + ";path=/;"; //加入一个变量记录cookies
}self.location = "/default.aspx?tabid=226&security_verify_data=" + stringToHex(screendate);
return fcookie //返回cookies
;}'''
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
print("修改环境:",execjs.get().name)
ctx = execjs.compile(jstext)
print(ctx.call("YunSuoAutoJump"))注意:这里的js中我加入了两条代码:
fcookie="srcurl=" + stringToHex(window.location.href) + ";path=/;"; //加入一个变量记录cookies
return fcookie //返回cookies执行结果:
修改代码后,使用requests发起请求,代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests,re,execjs,os
url = 'http://www.landchina.com/default.aspx?tabid=226'
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
}
html = requests.get(url, headers=headers, verify=False)
jstext = re.findall(r'',html.text)[0]
print("jstext:",jstext)
os.environ["EXECJS_RUNTIME"] = "PhantomJS"
jstext = jstext.replace('";path=/;";','";path=/;";fcookies="srcurl=" + stringToHex(window.location.href) + ";path=/;";')
jstext = jstext.replace('stringToHex(screendate);','stringToHex(screendate);return fcookies;')
print("jstext:",jstext)
ctx = execjs.compile(jstext)
print(ctx.call("YunSuoAutoJump"))输出结果:
jstext: function stringToHex(str){var val="";for(var i = 0; i < str.length; i++){if(val == "")val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;}function YunSuoAutoJump(){ var width =screen.width; var height=screen.height; var screendate = width + "," + height;var curlocation = window.location.href;if(-1 == curlocation.indexOf("security_verify_")){ document.cookie="srcurl=" + stringToHex(window.location.href) + ";path=/;";}self.location = "/default.aspx?tabid=226&security_verify_data=" + stringToHex(screendate);}
jstext: function stringToHex(str){var val="";for(var i = 0; i < str.length; i++){if(val == "")val = str.charCodeAt(i).toString(16);else val += str.charCodeAt(i).toString(16);}return val;}function YunSuoAutoJump(){ var width =screen.width; var height=screen.height; var screendate = width + "," + height;var curlocation = window.location.href;if(-1 == curlocation.indexOf("security_verify_")){ document.cookie="srcurl=" + stringToHex(window.location.href) + ";path=/;";fcookies="srcurl=" + stringToHex(window.location.href) + ";path=/;";}self.location = "/default.aspx?tabid=226&security_verify_data=" + stringToHex(screendate);return fcookies;}
srcurl=66696c653a2f2f2f433a2f55736572732f41444d494e497e312f417070446174612f4c6f63616c2f54656d702f657865636a7375753575783872652e6a73;path=/;
js中发现代码段:self.location="*******************8"(不懂的朋友可以看看:js中location.href的用法)
self.location = "/default.aspx?tabid=226&security_verify_data=" + stringToHex(screendate);通过fildder抓包分析,可以确定下一个请求链接http://www.landchina.com/default.aspx?tabid=226&security_verify_data=313533362c383634(注意,这个链接是js生成的):
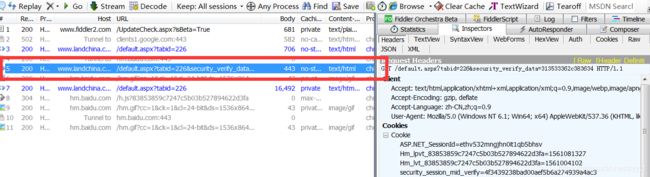
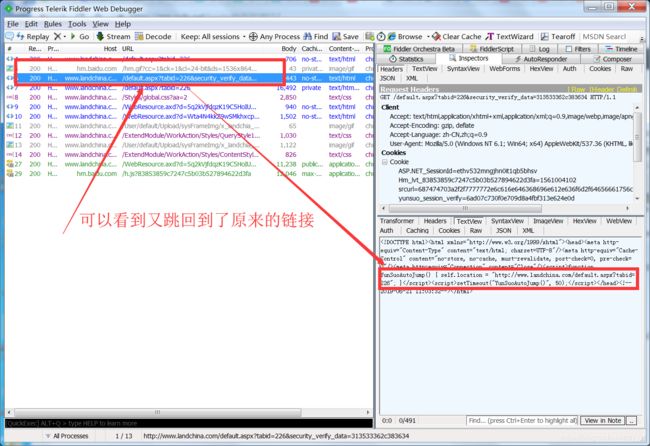
故,大概流程为首先请求http://www.landchina.com/default.aspx?tabid=226,获取js后解析获得cookies和verify_url信息,随后利用requests.session()访问js中的链接verify_url(我的是http://www.landchina.com/default.aspx?tabid=226&security_verify_data=313533362c383634),最后携带cookies信息再次请求http://www.landchina.com/default.aspx?tabid=226,最终拿到界面数据,整合代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import requests,re,execjs,os
session = requests.session()
url = 'http://www.landchina.com/default.aspx?tabid=226'
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
}
html = session.get(url, headers=headers, verify=False)
jstext = re.findall(r'',html.text)[0]
print("正则获取js:",jstext)
os.environ["EXECJS_RUNTIME"] = "PhantomJS" #设置execjs使用PhantomJS编译
jstext1 = jstext.replace('";path=/;";','";path=/;";fcookies="srcurl=" + stringToHex(window.location.href) + ";path=/;";')
jstext1 = jstext1.replace('stringToHex(screendate);','stringToHex(screendate);return fcookies;')
print("修改js:",jstext1)
ctx = execjs.compile(jstext1) #编译js
cookie1 = ctx.call("YunSuoAutoJump") #执行js中 YunSuoAutoJump()函数
print("js解析获得cookie1:",cookie1)
jstext2 = jstext.replace('stringToHex(screendate);','stringToHex(screendate);verify_url= "/default.aspx?tabid=226&security_verify_data=" + stringToHex(screendate);return verify_url;')
print("再次修改js获取以verify_url:",jstext2)
ctx = execjs.compile(jstext2)
verify_url = "http://www.landchina.com"+ctx.call("YunSuoAutoJump")
print("verify_url:",verify_url)
#分割cookies
cookie1= {item.split('=')[0]:item.split('=')[1] for item in cookie1.split('; ')}
html = session.get(verify_url)
# html = requests.get(next_url, headers=headers, verify=False,cookies=cookie1)
print("verify_url请求-html-2:",html.text)
html = session.get(url, headers=headers, verify=False)
print("最后获得界面-长度:",len(html.text))
print("最后获得界面-html:",html.text)
运行结果:
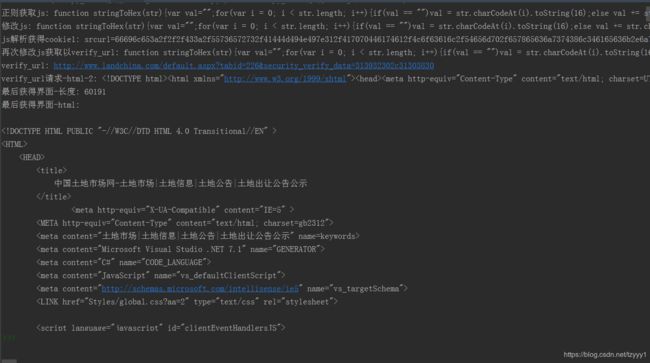
成功获取界面,后面就是数据清洗,url提取,入库等操作了。
参考文章:爬虫--破解网站通过js加密生成cookie(一)
本博客属技术研究,侵告删。