(七)tcp/ip协议之拥塞控制和窗口滑动
从传输数据来讲,TCP/UDP以及其他协议都可以完成数据的传输,从一端传输到另外一端,TCP比较出众的一点就是提供一个可靠的,流控的数据传输,所以实现起来要比其他协议复杂的多,先来看下这两个修饰词的意义:
1. Reliability ,提供TCP的可靠性,TCP的传输要保证数据能够准确到达目的地,如果不能,需要能检测出来并且重新发送数据。
2. Data Flow Control,提供TCP的流控特性,管理发送数据的速率,不要超过设备的承载能力
为了能够实现以上2点,TCP实现了很多细节的功能来保证数据传输,比如说 滑动窗口适应系统,超时重传机制,累计ACK等,这次先介绍一下滑动窗口的一些知识点。
拥塞控制
一般原理:发生拥塞控制的原因:资源(带宽、交换节点的缓存、处理机)的需求>可用资源。
作用:拥塞控制就是为了防止过多的数据注入到网络中,这样可以使网络中的路由器或者链路不至于过载。拥塞控制要做的都有一个前提:就是网络能够承受现有的网络负荷。
对比流量控制:拥塞控制是一个全局的过程,涉及到所有的主机、路由器、以及降低网络相关的所有因素。流量控制往往指点对点通信量的控制。是端对端的问题。
拥塞窗口:发送方为一个动态变化的窗口叫做拥塞窗口,拥塞窗口的大小取决于网络的拥塞程度。发送方让自己的发送窗口=拥塞窗口,但是发送窗口不是一直等于拥塞窗口的,在网络情况好的时候,拥塞窗口不断的增加,发送方的窗口自然也随着增加,但是接受方的接受能力有限,在发送方的窗口达到某个大小时就不在发生变化了。
发送方如果知道网络拥塞了呢?发送方发送一些报文段时,如果发送方没有在时间间隔内收到接收方的确认报文段,则就可以人为网络出现了拥塞。
慢启动算法的思路:主机开发发送数据报时,如果立即将大量的数据注入到网络中,可能会出现网络的拥塞。慢启动算法就是在主机刚开始发送数据报的时候先探测一下网络的状况,如果网络状况良好,发送方每发送一次文段都能正确的接受确认报文段。那么就从小到大的增加拥塞窗口的大小,即增加发送窗口的大小。
例子:开始发送方先设置cwnd(拥塞窗口)=1,发送第一个报文段M1,接收方接收到M1后,接收方向发送方发送确认报文,发送方接收到接收方的确认后,把cwnd增加到2,接着发送方发送M2、M3,发送方接收到接收方发送的确认后cwnd增加到4,慢启动算法每经过一个传输轮次(认为发送方都成功接收接收方的确认),拥塞窗口cwnd就加倍。
拥塞避免:为了防止cwnd增加过快而导致网络拥塞,所以需要设置一个慢开始门限ssthresh状态变量(我也不知道这个到底是什么,就认为他是一个拥塞控制的标识),它的用法:
1. 当cwnd < ssthresh,使用慢启动算法,
2. 当cwnd > ssthresh,使用拥塞控制算法,停用慢启动算法。
3. 当cwnd = ssthresh,这两个算法都可以。
拥塞避免的思路:是让cwnd缓慢的增加而不是加倍的增长,每经历过一次往返时间就使cwnd增加1,而不是加倍,这样使cwnd缓慢的增长,比慢启动要慢的多。
无论是慢启动算法还是拥塞避免算法,只要判断网络出现拥塞,就要把慢启动开始门限(ssthresh)设置为设置为发送窗口的一半(>=2),cwnd(拥塞窗口)设置为1,然后在使用慢启动算法,这样做的目的能迅速的减少主机向网络中传输数据,使发生拥塞的路由器能够把队列中堆积的分组处理完毕。拥塞窗口是按照线性的规律增长,比慢启动算法拥塞窗口增长块的多。
实例:1.TCP连接进行初始化的时候,cwnd=1,ssthresh=16。
2.在慢启动算法开始时,cwnd的初始值是1,每次发送方收到一个ACK拥塞窗口就增加1,当ssthresh =cwnd时,就启动拥塞控制算法,拥塞窗口按照规律增长,
3.当cwnd=24时,网络出现超时,发送方收不到确认ACK,此时设置ssthresh=12,(二分之一cwnd),设置cwnd=1,然后开始慢启动算法,当cwnd=ssthresh=12,慢启动算法变为拥塞控制算法,cwnd按照线性的速度进行增长。
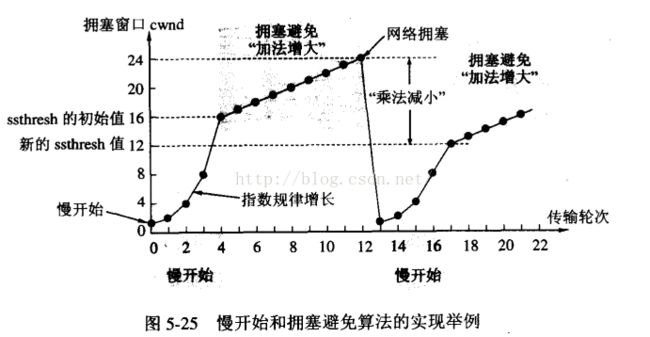
AIMD(加法增大乘法减小)
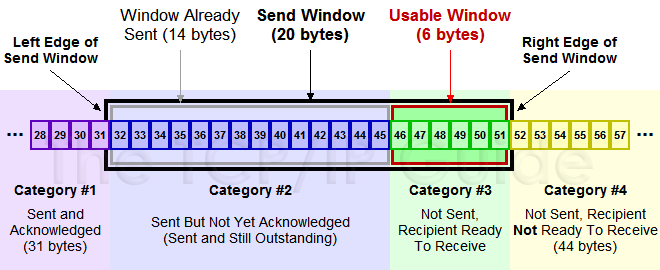
1. 乘法减小:无论在慢启动阶段还是在拥塞控制阶段,只要网络出现超时,就是将cwnd置为1,ssthresh置为cwnd的一半,然后开始执行慢启动算法(cwnd 2. 加法增大:当网络频发出现超时情况时,ssthresh就下降的很快,为了减少注入到网络中的分组数,而加法增大是指执行拥塞避免算法后,是拥塞窗口缓慢的增大,以防止网络过早出现拥塞。 这两个结合起来就是AIMD算法,是使用最广泛的算法。拥塞避免算法不能够完全的避免网络拥塞,通过控制拥塞窗口的大小只能使网络不易出现拥塞。 快重传: 快重传算法要求首先接收方收到一个失序的报文段后就立刻发出重复确认,而不要等待自己发送数据时才进行捎带确认。接收方成功的接受了发送方发送来的M1、M2并且分别给发送了ACK,现在接收方没有收到M3,而接收到了M4,显然接收方不能确认M4,因为M4是失序的报文段。如果根据可靠性传输原理接收方什么都不做,但是按照快速重传算法,在收到M4、M5等报文段的时候,不断重复的向发送方发送M2的ACK,如果接收方一连收到三个重复的ACK,那么发送方不必等待重传计时器到期,由于发送方尽早重传未被确认的报文段。 快恢复: 1. 当发送发连续接收到三个确认时,就执行乘法减小算法,把慢启动开始门限(ssthresh)减半,但是接下来并不执行慢开始算法。 2. 此时不执行慢启动算法,而是把cwnd设置为ssthresh的一半, 然后执行拥塞避免算法,使拥塞窗口缓慢增大。 在TCP/IP协议栈中,滑动窗口的引入可以解决此问题,先来看从概念上数据分为哪些类(发送端) 1. Sent and Acknowledged:这些数据表示已经发送成功并已经被确认的数据,比如图中的前31个bytes,这些数据其实的位置是在窗口之外了,因为窗口内顺序最低的被确认之后,要移除窗口,实际上是窗口进行合拢,同时打开接收新的带发送的数据 2. Send But Not Yet Acknowledged:这部分数据称为发送但没有被确认,数据被发送出去,没有收到接收端的ACK,认为并没有完成发送,这个属于窗口内的数据。 3. Not Sent,Recipient Ready to Receive:这部分是尽快发送的数据,这部分数据已经被加载到缓存中,也就是窗口中了,等待发送,其实这个窗口是完全有接收方告知的,接收方告知还是能够接受这些包,所以发送方需要尽快的发送这些包 4. Not Sent,Recipient Not Ready to Receive: 这些数据属于未发送,同时接收端也不允许发送的,因为这些数据已经超出了发送端所接收的范围 对于接收端也是有一个接收窗口的,类似发送端,接收端的数据有3个分类,因为接收端并不需要等待ACK所以它没有类似的接收并确认了的分类,情况如下 1. Received and ACK Not Send to Process:这部分数据属于接收了数据但是还没有被上层的应用程序接收,也是被缓存在窗口内 2. Received Not ACK: 已经接收并,但是还没有回复ACK,这些包可能输属于Delay ACK的范畴了 3. Not Received:有空位,还没有被接收的数据。 发送窗口和可用窗口 对于发送方来讲,窗口内的包括两部分,就是发送窗口(已经发送了,但是没有收到ACK),可用窗口,接收端允许发送但是没有发送的那部分称为可用窗口。 1. Send Window : 20个bytes 这部分值是有接收方在三次握手的时候进行通告的,同时在接收过程中也不断的通告可以发送的窗口大小,来进行适应 2. Window Already Sent: 已经发送的数据,但是并没有收到ACK。 举一个例子来说明一下滑动窗口的原理: 1. 假设32~45 这些数据,是上层Application发送给TCP的,TCP将其分成四个Segment来发往internet 2. seg1 32~34 seg3 35~36 seg3 37~41 seg4 42~45 这四个片段,依次发送出去,此时假设接收端之接收到了seg1 seg2 seg4 3. 此时接收端的行为是回复一个ACK包说明已经接收到了32~36的数据,并将seg4进行缓存(保证顺序,产生一个保存seg3 的hole) 4. 发送端收到ACK之后,就会将32~36的数据包从发送并没有确认切到发送已经确认,提出窗口,这个时候窗口向右移动 5. 假设接收端通告的Window Size仍然不变,此时窗口右移,产生一些新的空位,这些是接收端允许发送的范畴 6. 对于丢失的seg3,如果超过一定时间,TCP就会重新传送(重传机制),重传成功会seg3 seg4一块被确认,不成功,seg4也将被丢弃 就是不断重复着上述的过程,随着窗口不断滑动,将真个数据流发送到接收端,实际上接收端的Window Size通告也是会变化的,接收端根据这个值来确定何时及发送多少数据,从对数据流进行流控。原理图如下图所示: 滑动窗口动态调整 1. 客户端不断快速发送数据,服务器接收相对较慢,看下实验的结果 a. 包175,发送ACK携带WIN = 384,告知客户端,现在只能接收384个字节 b. 包176,客户端果真只发送了384个字节,Wireshark也比较智能,也宣告TCP Window Full c. 包177,服务器回复一个ACK,并通告窗口为0,说明接收方已经收到所有数据,并保存到缓冲区,但是这个时候应用程序并没有接收这些数据,导致缓冲区没有更多的空间,故通告窗口为0, 这也就是所谓的零窗口,零窗口期间,发送方停止发送数据 d. 客户端察觉到窗口为0,则不再发送数据给接收方 e. 包178,接收方发送一个窗口通告,告知发送方已经有接收数据的能力了,可以发送数据包了 f. 包179,收到窗口通告之后,就发送缓冲区内的数据了.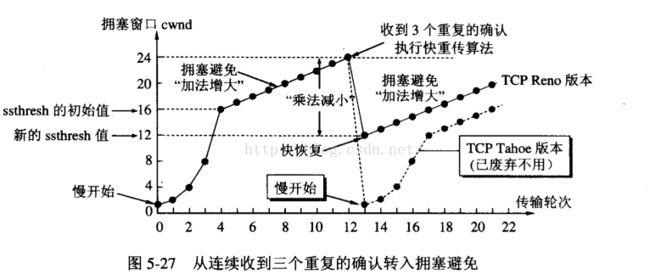
滑动窗口
可以假设一下,来优化一下PAR效率低的缺点,比如我让发送的每一个包都有一个id,接收端必须对每一个包进行确认,这样设备A一次多发送几个片段,而不必等候ACK,同时接收端也要告知它能够收多少,这样发送端发起来也有个限制,当然还需要保证顺序性,不要乱序,对于乱序的状况,我们可以允许等待一定情况下的乱序,比如说先缓存提前到的数据,然后去等待需要的数据,如果一定时间没来就DROP掉,来保证顺序性!
滑动窗口原理
TCP并不是每一个报文段都会回复ACK的,可能会对两个报文段发送一个ACK,也可能会对多个报文段发送1个ACK【累计ACK】,比如说发送方有1/2/3 3个报文段,先发送了2,3 两个报文段,但是接收方期望收到1报文段,这个时候2,3报文段就只能放在缓存中等待报文1的空洞被填上,如果报文1,一直不来,报文2/3也将被丢弃,如果报文1来了,那么会发送一个ACK对这3个报文进行一次确认。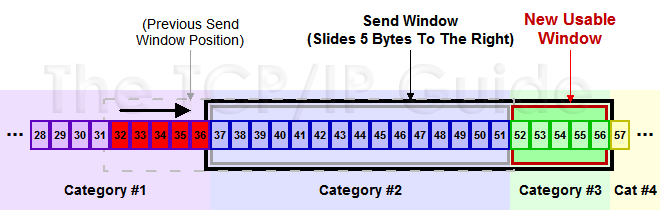
主要是根据接收端的接收情况,动态去调整Window Size,然后来控制发送端的数据流量
总结一点,就是接收端可以根据自己的状况通告窗口大小,从而控制发送端的接收,进行流量控制