转自:https://zhuanlan.zhihu.com/p/31096468
前言
普遍的观点认为,前端就是打好 HTML、CSS、JS 三大基础,深刻理解语义化标签,了解 N 种不同的布局方式,掌握语言的语法、特性、内置 API。再学习一些主流的前端框架,使用社区成熟的脚手架,即可快速搭建一个前端项目。胜任前端工作非常容易。再往深处学习,你会发现前端这个领域,总是有学不完的框架、工具、库,不断有新的轮子出现。技术推陈出新,版本快速迭代,但万变不离其宗。工具致力于流程自动化、规范化,服务于简洁、优雅、高效的编码,将问题高度抽象化、层次化。在如今前端开源界如此火热的现状下,框架的使用者与框架的维护者联系更加紧密,不仅能深入源码来更彻底地认识框架,还能够提出问题,参与讨论,贡献代码,共同解决技术问题,推进前端生态的发展和壮大。而编译原理,作为一门基础理论学科,除了 JS 语言本身的编译器之外,更成为 Babel、ESLint、Stylus、Flow、Pug、YAML、Vue、React、Marked 等开源前端框架的理论基石之一。了解编译原理能够对所接触的框架有更充分的认识。
什么是编译器?
对外部来说,编译器是一个黑盒子,能够把一种源语言翻译为语义上等价的另一种目标语言。从现代高级编译器的角度讲,源语言是高级程序设计语言,容易阅读与编写,而目标语言是机器语言,即二进制代码,能够被计算机直接识别。从语言系统的处理角度来看,由源程序生成可执行程序的整体工作流程如图 1 所示:
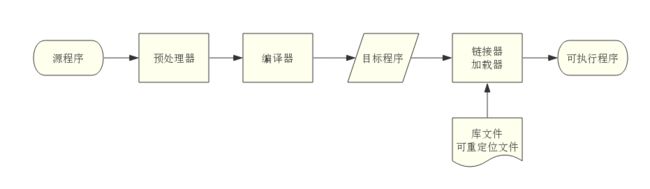 图1 源程序生成可执行程序整体工作流程图
图1 源程序生成可执行程序整体工作流程图
其中,编译器又分为前端和后端两个部分。前端包括词法分析、语法分析、语义分析、中间代码生成,具有机器无关性,比较有代表性的工具是 Flex、Bison。后端包括中间代码优化、目标代码生成,具有机器相关性,比较有代表性的工具是 LLVM。在 Web 前端工程领域,由于宿主环境浏览器与 Node.js 的跨平台特性,我们只需关注编译器前端部分,就可以充分发挥它的应用价值。为了更好地理解编译器前端的工作原理,本文将主要以目前被广泛使用的 Babel 为例,阐述它是如何将源代码编译为目标代码。
Babel
作为新生代 ES 语法编译器,Babel 在前端工具链中占据了非常重要的地位,它严格按照 ECMA-262 语言规范,实现对最新语法的解析,而无需等待浏览器升级来提供对新特性的支持。Babel 内部所使用的语法解析器是 Babylon,抽象语法树(简写为 AST)的结点类型定义则参考了 Mozilla JS 引擎 SpiderMonkey,并对其进行扩展增强,且支持对 Flow、JSX、TypeScript 语法的解析。它所使用的 Babylon 实现了编译器中两个部分,词法分析和语法分析。
词法分析
词法分析是处理源程序的第一部分,主要任务是逐个扫描输入字符,转换为词法单元(Token)序列,传递给语法分析器进行语法分析。Token 是一个不可分割的最小单元。例如 var 这三个字符,它只能作为一个整体,语义上不能再被分解,因此它是一个 Token。每个 Token 对象都有能够被单独识别的类型属性和其它附加属性(操作符优先级、行列号等)。在 Babylon 词法分析器里,每个关键字是一个 Token ,每个标识符是一个 Token,每个操作符是一个 Token,每个标点符号也都是一个 Token。除此之外,还会过滤掉源程序中的注释和空白字符(换行符、空格、制表符等)。
对于 Token 的匹配规则,可以根据正则表达式来描述。举个例子,要匹配一个 Number 类型的 Token,可以检测是否以 [0-9] 开头,接着循环或递归扫描紧连的后续字符,且需要特别留意 0b、0o、0x 开头的非十进制数值、科学计数法 e 或 E、小数点等特殊字符,指针不断后移直至不满足匹配规则或者到达行末尾。最后生成一个 Number 类型的 Token,附带值、文件位置等属性,并加入到 Token 序列中,继续下一轮扫描。
一个简单的 Number 类型状态转换如图 2 所示:
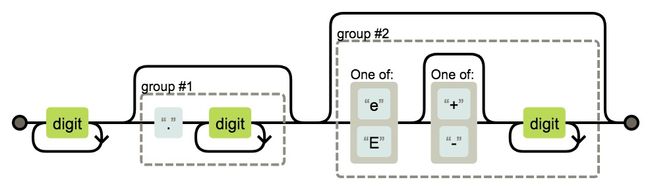 图2 Number 类型状态转换示意图
图2 Number 类型状态转换示意图
当然除了 Babylon 手写词法分析器之外,这个过程还可以采用有穷自动机(DFA/NFA)的方式实现,通过词法分析器生成器,把输入程序(模式匹配规则)自动转换成一个词法分析器,这里不展开阐述。
语法分析
语法分析是词法分析的下一步,主要任务是扫描来自词法分析器产生的 Token 序列,根据文法和结点类型定义构造出一棵 AST,传递给编译器前端余下部分。文法描述了程序设计语言的构造规则,用于指导整个语法分析的过程。它由四个部分组成,一组终结符号(也称 Token)、一组非终结符号、一组产生式和一个开始符号。例如,函数声明语句的产生式表示形式如图 3 所示:
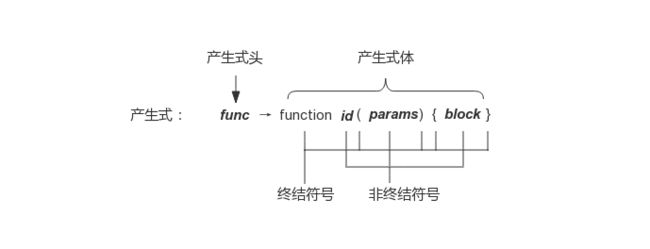 图3 函数声明语句的产生式
图3 函数声明语句的产生式
根据文法,语法分析器将 Token 逐个读入,不断替换文法产生式体的非终结符号,直至全部将非终结符号替换为终结符号,这个过程被称为推导。推导又分为两种方式,最左推导和最右推导。如果总是优先替换产生式体最左侧的非终结符号,被称为最左推导,如果总是优先替换产生式体最右侧的非终结符号,被称为最右推导。
语法分析器按照工作方式来划分,分为自顶向下分析法和自底向上分析法。自顶向下分析法要求通过最左推导从顶部 ( 根结点 ) 开始构造 AST,常用的分析器有递归下降语法分析器、 LL 语法分析器。而自底向上分析法要求通过最右推导从底部 ( 叶子结点 ) 开始构造 AST,常用的分析器有 LR 语法分析器、SLR 语法分析器、LALR 语法分析器。这两种分析方式在 Babylon 中都有所实践。
首先是自顶向下分析法,例如变量声明语句:
var foo = "bar";
经由词法分析器处理后,会生成 Token 序列:
Token('var')
Token('foo') Token('=') Token('"bar"') Token(';')
由 LL(1) 语法分析器进行递归下降分析,每次向前查看一个输入 Token,来决定该用哪种产生式展开。对于变量声明语句的 FIRST 集合(推导结果的首个 Token 集合),只需检查输入 Token 为 Token('var')、Token('let')、Token('const') 三者其中之一,那么就使用该产生式展开。首先构造 AST 最顶层结点 VariableDeclaration,把 Token('var') 的值加入到该结点属性中, 接着逐个读入其余 Token,根据产生式的非终结符号从左到右的顺序,依次构造它的子结点,不断递归下降分析,直至所有 Token 读入完毕。最后生成的一棵 AST 如图 4 所示:
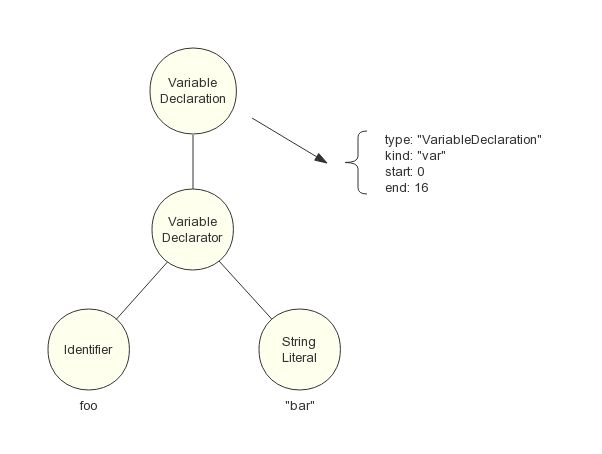 图4 自顶向下分析法产生的 AST 树
图4 自顶向下分析法产生的 AST 树
另一种是自底向上分析法,例如成员表达式语句:
foo.bar.baz.qux
我们都知道这条语句等价于:
((foo.bar).baz).qux
而不是:
foo.(bar.(baz.qux))
原因就在于它所设计的文法是左递归的,而 LL 语法分析器是无法做到解析左递归的文法,这时候只能使用 LR 语法分析器的方式,自底向上地构造 AST。LR 语法分析器的核心是移入 - 归约分析技术,通过维护一个栈,由下一个输入 Token 来决定是把它移入栈中还是将栈顶的部分符号进行归约(把产生式体替换为产生式头),先构造子结点,再构造父结点,直至栈中所有符号全部归约。最后生成的一棵 AST 如图 5 所示:
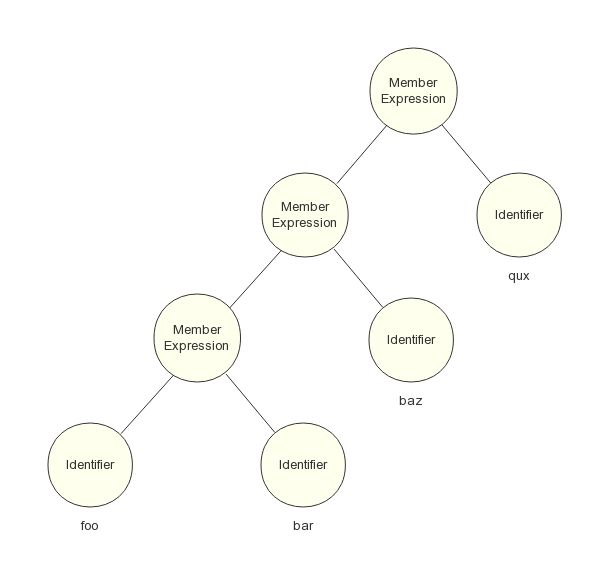 图5 自底向上分析法产生的 AST 树
图5 自底向上分析法产生的 AST 树
此外,由 Babylon 构建的完整的 AST 还拥有特殊顶层结点 File 和 Program,它们描述了文件的基本信息、模块类型等等。
生成代码
工业级别的语言编译器,通常还会有语义分析阶段,检查程序上下文是否和语言所定义的语义一致,比如类型检查,作用域检查,另一个则是生成中间代码,比如三地址代码,用地址和指令来线性描述程序。但由于 Babel 的定位仅仅是对 ES 语法的转换,这一部分工作可以交给 JS 解释器引擎来处理。而 Babel 最为特色的部分是它的插件机制,针对不同的浏览器版本环境,调用不同的 Babel 插件。通过访问者模式(一种设计模式)的接口定义,对 AST 进行一遍深度优先遍历,对指定的匹配到的结点进行修改、删除、新增、移位,使原先的 AST 转换为另一棵经过修改的 AST。
一个访问者模式的接口定义如下:
visitor: {
Identifier(path) { enter() { //遍历AST进入Identifier结点时执行 ... }, exit() { //遍历AST离开Identifier结点时执行 ... } }, ... }
最后一个阶段则是生成目标代码,从 AST 的根结点出发,递归下降遍历,对每个结点都调用一个相关函数,执行语义动作,不断打印代码片段,最终生成目标代码,即经过 babel 编译后的代码。
模板引擎
再讲到模板引擎,最早诞生于服务端动态页面的开发,如 JSP、PHP、ASP 等模板引擎,自 Node.js 快速发展以后,前端界又产出了非常多的轮子,包括 EJS、Handlebars、Pug (前身为 Jade)、Mustache 等等,数不胜数。模板引擎技术使得结合数据渲染视图变得更加灵活,给逻辑的抽象带来了更多的可能性,数据与内容互不依赖。模板引擎的实现方式有很多种,比较简单的模板引擎,直接利用字符串替换、拼接的方式实现,比较复杂的模板引擎,例如 Pug,则会有比较完整的词法分析和语法分析过程,将模板预编译成 JS 代码再去动态执行。
例如模板语句:
h1 hello #{name}
经由 Pug 解析器生成的 AST 如图 6 所示:
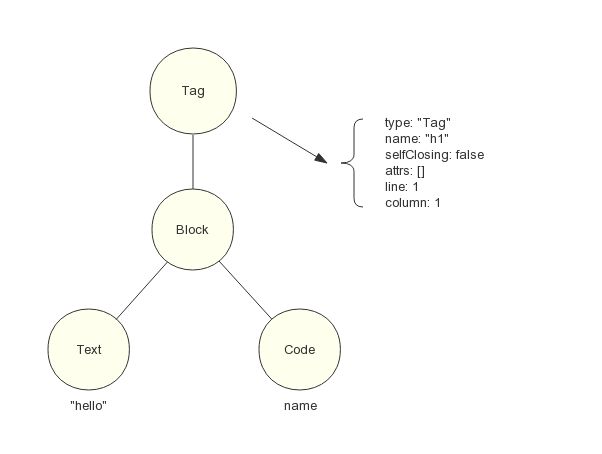 图6 由 Pug 解析器生成的 AST
图6 由 Pug 解析器生成的 AST
生成器生成的目标代码为(伪代码):
'' + 'hello' + name + ''
运行时再调用 new Function 来动态执行代码:
var compiledFn = new Function('local', ` with (local) { return '' + 'hello' + name + ''; } `) compiledFn({ name: 'world' })
最后输出 HTML 语句:
<h1>hello worldh1>
整个过程由两部分组成,预编译阶段和运行时阶段。当然一个好的模板引擎还会考虑功能、性能与安全兼备,上面的`with`语句是要避免的,还要引入缓存机制,XSS 防范机制,以及更加强大、友好、易于使用的语法糖。
另外值得一提的是以 Angular、React、Vue 为代表的前端 MVVM 框架,无一不引入了模板编译技术。Vue 作为渐进式的前端解决方案,受到众多开发者们的青睐,它对视图的渲染提供了渲染函数和模板两种方式。使用渲染函数需要调用核心 API 来构建 Virtual DOM 类型,过程相对复杂,编码量非常大,一旦 DOM 层次嵌套过深,就会造成代码难以掌控和维护的局面。为了应对这种复杂性,另一种方式则是编写基于 HTML 的模板,并加入 Vue 特有的标签、指令、插值等语法,由编译器来进行从模板到渲染函数的编译和优化,相对前者更优雅、便捷、易于编码。
CSS 预处理器
前端布局方式从刀耕火种的纯 CSS 年代演进到以 Sass、Less、Stylus 为代表的预处理语言,赋予了 CSS 可编程的能力,定义变量,函数,表达式计算、模块化等特性,极大地提升了开发人员的生产效率。这些都是编译技术所带来的变化。同样,编译器对原样式代码进行词法分析,产生 Token 序列。接着,语法分析,生成中间表示,一棵符合定义的 AST。同时,还会为每个程序块建立一个符号表来记录变量的名字,属性,为代码生成阶段的变量作用域分析提供帮助。最后,递归下降访问 AST,生成能够在浏览器环境中直接执行的 CSS 代码。
以预处理器 Stylus 语法为例:
foo = 14px
body
font-size foo
编译生成的 AST 为图 7 所示:
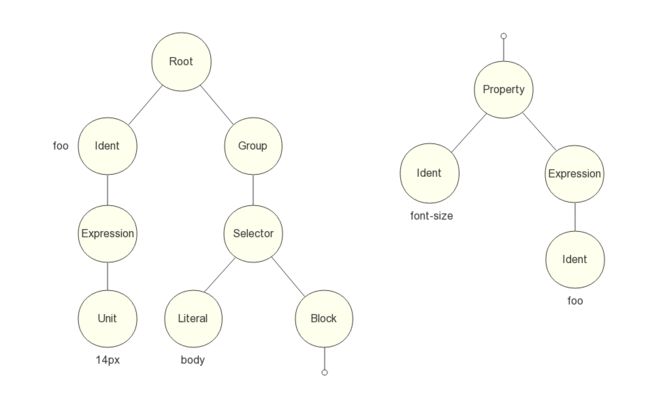 图7 由 Stylus 解析器生成的 AST
图7 由 Stylus 解析器生成的 AST
最后生成的目标代码为:
body {
font-size: 14px; }
看似简单容易的代码转换背后,编译器为我们做了许多语法层面的处理,给 CSS 带来了从未有过的强大的扩展能力,以及底层对编译速度的持续优化,让 CSS 的编写方式更加简洁高效,易于维护和管理。
写在最后
写这篇文章的目的是希望告诉读者,编译原理在前端工程领域的应用非常广泛,可以用来帮助我们解决工程技术上的难点。当然在实际编码过程中,需要非常得有耐心,细心,考虑各种文法,分析方式,优化手段,写好测试用例等等。一个良好的编译器需要精心打磨,不断优化升级,全方位为开发者服务。如果你没有学习过编译原理相关知识,建议寻找相关书籍,系统地学习一遍知识体系。即使在实际日常工作中接触不到编译原理,但它对基础知识的积累与掌握,对编程语言的认识与理解,对框架的学习与运用,对日后职业生涯的发展道路,或多或少都有帮助。