从零开始利用Python建立逻辑回归分类模型
假设申请人向你提供成绩,你根据成绩对其进行分类,目标是根据分数将申请人分为两类,如果申请人可以进入大学,则分为1级,如果申请人不能被录取,则分为0级。使用线性回归可以解决这个问题吗?让我们一起来看看。
注意:阅读本文的前提是了解线性回归!
目录
-
什么是逻辑回归?
-
数据集可视化
-
假设和成本函数
-
从头开始训练模型
-
模型评估
-
Scikit-learn实现
什么是逻辑回归?
回想一下线性回归,它被用于确定一个连续因变量的值。逻辑回归通常用于分类目的。与线性回归不同,因变量只能采用有限数量的值,即因变量是分类的。当可能结果的数量只有两个时,它被称为二元逻辑回归。
让我们看看逻辑回归如何被用于分类任务。
在线性回归中,输出是输入的加权和。逻辑回归是广义线性回归,在某种意义上,我们不直接输出输入的加权和,但我们通过一个函数来传递它,该函数可以映射0到1之间的任何实数值。
如果我们将输入的加权和作为输出,就像我们在线性回归中做的那样,那么该值可以大于1,但我们想要一个介于0和1之间的值。这也是为什么线性回归不能用于分类任务的原因。
从下图可以看出,线性回归的输出通过一个激活函数传递,该函数可以映射0到1之间的任何实数值。

所使用的激活函数称为sigmoid函数。sigmoid函数的曲线如下图所示
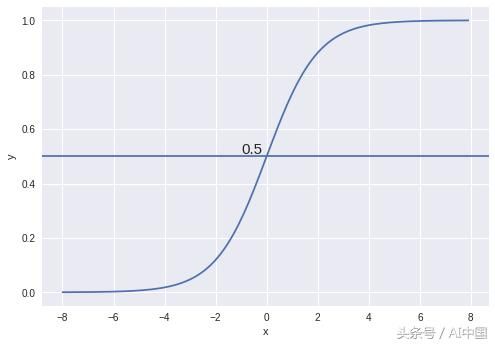
我们可以看到sigmoid函数的值总是介于0和1之间。在X = 0时,该值恰好为0.5。我们可以使用0.5作为概率阈值来确定类。如果概率大于0.5,我们将其分类为Class-1(Y = 1)或者归类为Class-0(Y = 0)。
在我们构建模型之前,让我们看一下逻辑回归所做的假设
-
因变量必须是绝对的
-
自变量(特征)必须是独立的(以避免多重共线性)
数据集
本文中使用的数据来自吴恩达在Coursera上的机器学习课程。数据可以从这里下载。(https://www.coursera.org/learn/machine-learning)该数据包括100名申请人的两次考试分数。目标值采用二进制值1,0。1表示申请人被大学录取,0表示申请人未被录取。它目标是建立一个分类器,可以预测申请是否将被大学录取。
让我们使用read_csv函数将数据加载到pandas Dataframe中。我们还将数据分为录取的和未录取的,以使数据可视化。




现在我们已经清楚地了解了问题和数据,让我们继续构建我们的模型。
假设和成本函数
到目前为止,我们已经了解了如何使用逻辑回归将实例分类到不同的类中。在本节中,我们将定义假设和成本函数。
线性回归模型可以用等式表示。
![]()
然后,我们将sigmoid函数应用于线性回归的输出
![]()
sigmoid函数表示为,
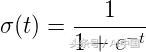
然后逻辑回归的假设为,

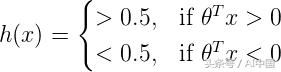
如果输入的加权和大于零,则预测的类为1,反之亦然。因此,通过将输入的加权和设置为0,可以找到将两个类分开的决策边界。
成本函数
与线性回归一样,我们将为模型定义成本函数,目标是最小化成本。
单个训练示例的成本函数可以通过以下方式给出:
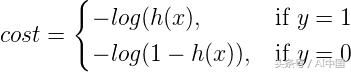
成本函数直觉
如果实际的类是1并且模型预测为0,我们应该惩罚它,反之亦然。从下图中可以看出,对于h(x)接近1的情况-log(h(x)),成本为0,当h(x)接近0时,成本为无穷大(即我们对模型进行严重惩罚)。类似地,对于绘图-log(1-h(x)),当实际值为0并且模型预测为0时,成本为0并且当h(x)接近1时成本变为无穷大。

我们可以使用以下两个方程组合:
![]()
由J(θ)表示的所有训练样本的成本可以通过取所有训练样本的成本的平均值来计算
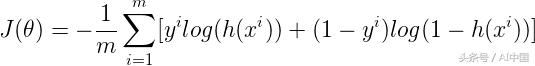
其中m是训练样本的数量。
我们将使用梯度下降来最小化成本函数。梯度w.r.t任何参数都可以由该方程给出
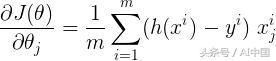
该方程类似于我们在线性回归中所获得的方程,在这两种情况下只有h(x)不同。
训练模型
现在我们已经拥有了构建模型所需的一切。让我们在代码中实现它。
让我们首先为我们的模型准备数据。

我们将定义一些将用于计算成本的函数。

接下来,我们定义成本和梯度函数。


我们还定义拟合函数,该函数将用于查找最小化成本函数的模型参数。在这篇文章中,我们编写了梯度下降法来计算模型参数。 在这里,我们将使用scipy库中的fmin_tnc函数。它可用于计算任何函数的最小值。它将参数作为:
-
func:最小化的函数
-
x0:我们想要查找的参数的初始值
-
fprime:'func'定义的函数的梯度
-
args:需要传递给函数的参数

模型参数为[-25.16131856 0.20623159 0.20147149]
为了了解我们的模型有多好,我们将绘制决策边界。
绘制决策边界
由于我们的数据集中有两个特征,因此线性方程可以表示为,
![]()
如前所述,可以通过将输入的加权和设置为0来找到决策边界。将h(x)等于0,

我们将在我们用于可视化数据集的图上方绘制决策边界。


看起来我们的模型在预测课程方面做得不错。但它有多准确?让我们来看看。
模型的准确性

该模型的准确率为89%。
让我们使用scikit-learn实现我们的分类器,并将它与我们从头开始构建的模型进行比较。
scikit-learn实现

模型参数为[[-2.85831439,0.05214733,0.04531467]],精度为91%。
为什么模型参数与我们从头开始实现的模型有很大不同?如果你看一下sk-learn的逻辑回归实现的文档,你就会发现其中考虑了正则化。基本上,正则化是用于防止模型过度拟合数据的。 在本文中,我不会深入讨论正规化的细节。
此文章中使用的完整代码可以在此GitHub中找到。(https://github.com/animesh-agarwal/Machine-Learning/tree/master/LogisticRegression)
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31545819/viewspace-2217707/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31545819/viewspace-2217707/