pytorch学习笔记四:torch.nn下常用网络层(layer)详解
一、卷积层
- 卷积:Conv2d
'''
in_channels:输入通道数
out_channels:输出通道数
kernel_size:卷积核尺寸,整数或者元组
stride:卷积操作的步幅,整数或者元组
padding:数据hw方向上填充的层数,整数或者元组,默认填充的是0
dilation:卷积核内部各点的间距,整数或者元组
groups:控制输入和输出之间的连接;group=1,输出是所有输入的卷积;
group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,
并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
bias:bool类型,为true的话就会对输出添加可学习的偏置量
padding_mode:填充模式,字符串类型
'''
torch.nn.Conv2d(in_channels, out_channels,
kernel_size, stride=1,
padding=0, dilation=1,
groups=1, bias=True,
padding_mode='zeros')

- 转置卷积:ConvTranspose2d
'''
in_channels:输入通道数
out_channels:输出通道数
kernel_size:卷积核尺寸,整数或者元组
stride:卷积操作的步幅,整数或者元组
padding:数据hw方向上填充的层数,整数或者元组,默认填充的是0
output_padding:对输出的hw填充的层数,整数或者元组
groups:控制输入和输出之间的连接;group=1,输出是所有输入的卷积;
group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,
并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
dilation:卷积核内部各点的间距,整数或者元组
bias:bool类型,为true的话就会对输出添加可学习的偏置量
padding_mode:填充模式,字符串类型
'''
torch.nn.ConvTranspose2d(in_channels, out_channels,
kernel_size, stride=1,
padding=0, output_padding=0,
groups=1, bias=True,
dilation=1, padding_mode='zeros')


二、池化层
- 最大池化:MaxPool2d
'''
kernel_size:窗口尺寸;整数或者元组
stride:窗口的步幅,默认就等于窗口尺寸;整数或者元组
padding:数据hw方向上的零填充层数;整数或者元组
dilation:一个控制窗口中元素步幅的参数;整数或者元组
return_indices:如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
ceil_mode:如果等于True,计算输出数据的hw的时候,
会使用向上取整,代替默认的向下取整的操作
'''
torch.nn.MaxPool2d(kernel_size, stride=None,
padding=0, dilation=1,
return_indices=False, ceil_mode=False)

- 平均池化:AvgPool2d
'''
kernel_size:窗口尺寸;整数或者元组
stride:窗口的步幅,默认就等于窗口尺寸;整数或者元组
padding:数据hw方向上的零填充层数;整数或者元组
ceil_mode:如果等于True,计算输出数据的hw的时候,
会使用向上取整,代替默认的向下取整的操作
count_include_pad:如果等于True,计算平均池化时,将包括padding填充的0
divisor_override
'''
torch.nn.AvgPool2d(kernel_size, stride=None,
padding=0, ceil_mode=False,
count_include_pad=True,
divisor_override=None)

三、填充层
- 零填充:ZeroPad2d
'''
padding:填充的层数,整数或者元组;如果是一个整数值n,
那么在四个边界上都填充n层0;如果是四个整数值组成的元组,
那么就分别表示对应方向上填充0的层数,对应关系如下:
(padding_left,padding_right,padding_top,padding_bottom)
'''
torch.nn.ZeroPad2d(padding)

下面举个例子:
>>> m = nn.ZeroPad2d(2)
>>> input = torch.randn(1, 1, 3, 3)
>>> input
tensor([[[[-0.1678, -0.4418, 1.9466],
[ 0.9604, -0.4219, -0.5241],
[-0.9162, -0.5436, -0.6446]]]])
>>> m(input)
tensor([[[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.1678, -0.4418, 1.9466, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.9604, -0.4219, -0.5241, 0.0000, 0.0000],
[ 0.0000, 0.0000, -0.9162, -0.5436, -0.6446, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]]])
>>> # using different paddings for different sides
>>> m = nn.ZeroPad2d((1, 1, 2, 0))
>>> m(input)
tensor([[[[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, -0.1678, -0.4418, 1.9466, 0.0000],
[ 0.0000, 0.9604, -0.4219, -0.5241, 0.0000],
[ 0.0000, -0.9162, -0.5436, -0.6446, 0.0000]]]])
四、非线性激活层
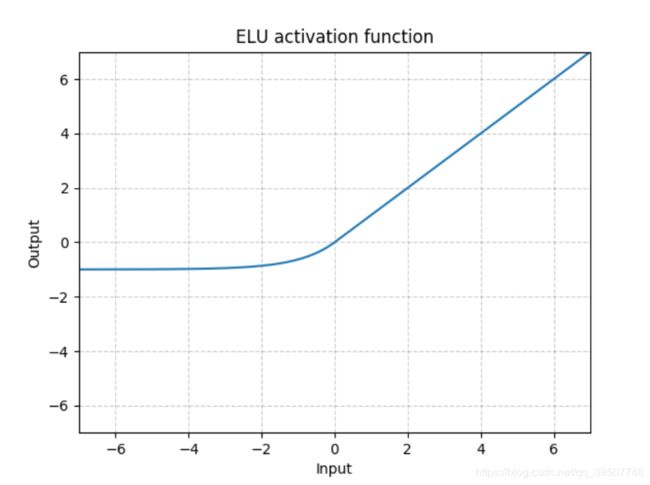
- ELU
torch.nn.ELU(alpha=1.0, inplace=False)
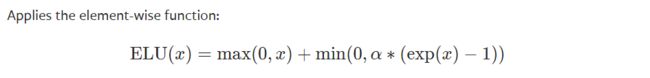
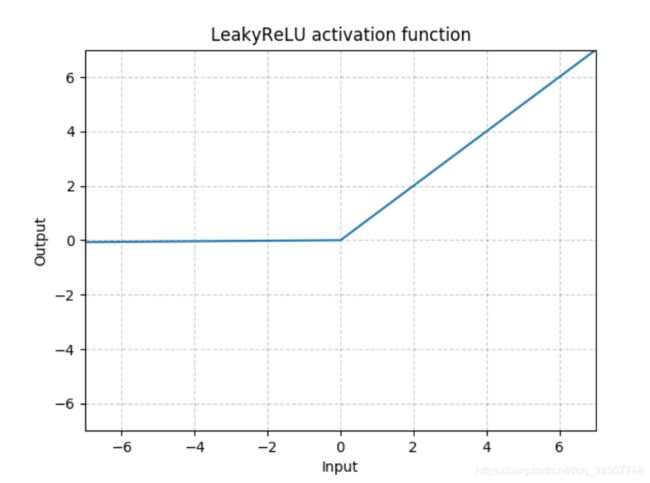
- LeakyReLU
torch.nn.LeakyReLU(negative_slope=0.01, inplace=False)
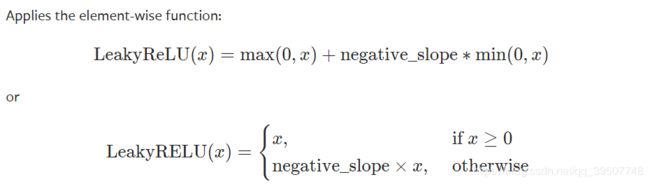
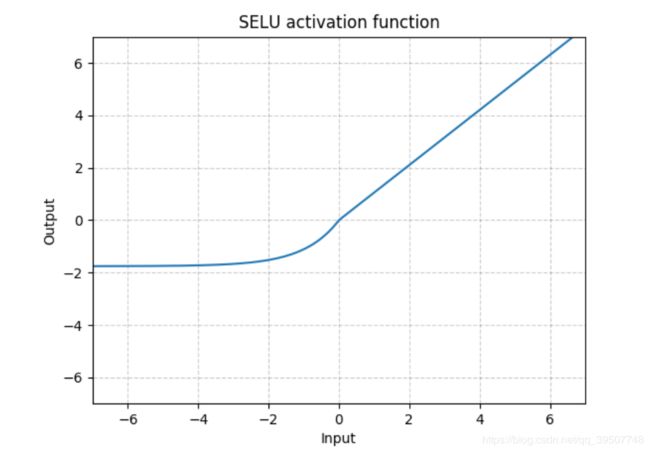
- SELU
torch.nn.SELU(inplace=False)

- RReLU
torch.nn.RReLU(lower=0.125, upper=0.3333333333333333,
inplace=False)
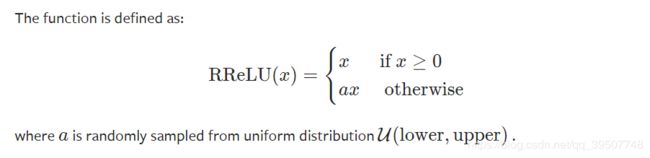
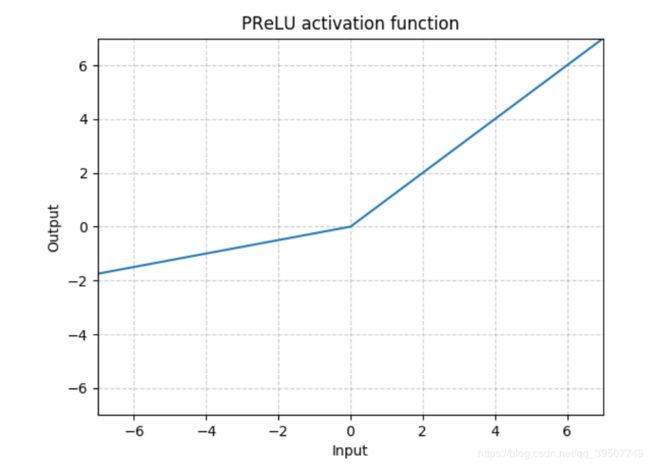
- PReLU(系数可学习)
'''
num_parameters:可学习参数的个数,1或者通道数;
1表示所有通道使用相同的可学习系数,后者表示每个通道独有一个可学习系数
init:可学习系数a的初始值
'''
torch.nn.PReLU(num_parameters=1, init=0.25)
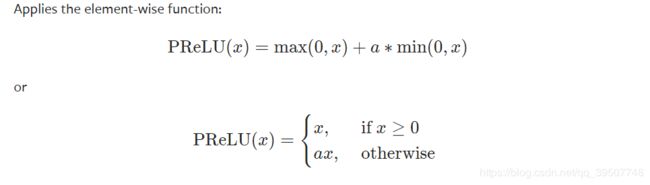
- Sigmoid
torch.nn.Sigmoid
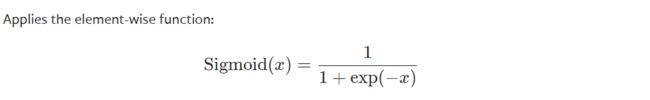
五、标准化层
- BatchNorm2d
'''
num_features:来自期望输入的特征数,该期望输入的大小为
'batch_size x num_features x height x width'
eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5
momentum:动态均值和动态方差所使用的动量,默认为0.1
affine:一个布尔值,当设为true,给该层添加可学习的仿射变换参数
'''
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1,
affine=True, track_running_stats=True)

六、Dropout 丢弃层
- 输入: (N,C,H,W)
输出: (N,C,H,W)(与输入形状相同)
'''
p:将元素置0的概率,默认值=0.5
'''
torch.nn.Dropout(p=0.5, inplace=False)
七、Upsample 上采样
- 对给定的
1D (temporal),2D (spatial)or3D (volumetric)数据进行上采样,这里的维度不包括batch和channel
'''
size:根据给定的需要进行上采样的数据的维度,指定的输出数据的size;
对应上面所说的三种维度,size可以是int,(int,int),(int,int,int)
scale_factor:指定在某个维度上输出为输入尺寸的多少倍,
对应上面所说的三种维度,size可以是float,(float,float),(float,float,float)
mode:可使用的上采样算法,有'nearest', 'linear', 'bilinear',
'bicubic' and 'trilinear'. 默认使用'nearest'
align_corners:如果为True,输入的角像素将与输出张量对齐,因此将保存下
来这些像素的值。仅当使用的算法为'linear', 'bilinear'or
'trilinear'时可以使用。默认设置为False
'''
torch.nn.Upsample(size=None, scale_factor=None,
mode='nearest', align_corners=None)
