爬虫学习 step_05 爬取的数据放入数据库
采用的是mysql-connector驱动:
db = mysql.connector.connect(user='root', password='******', database='luntan', charset='utf8') #初始化一个数据库对象mysqldb驱动的话为:
db = MySQLdb..connect(user='root', password='******', database='luntan', charset='utf8')#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-05-06 15:41:13
# Project: v2ex
from pyspider.libs.base_handler import *
import random
import mysql.connector
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.db = mysql.connector.connect(user='root', password='nankai416', database='luntan', charset='utf8') #初始化一个数据库对象
def add_question(self,title,content):
try:
cursor = self.db.cursor() #获取一个数据库游标
sql = 'insert into question(title, content, user_id, created_date,comment_count) values("%s", "%s" , %d, now() , 0) '%(title,content,random.randint(0,10),) #定义一个sql语句
print sql
cursor.execute(sql) #执行sql语句
qid = cursor.lastrowid #打印出最近插入的数据的id
print qid
self.db.commit() #提交事务
except Exception, e:
print e.message
self.db.rollback() #出现异常回滚
self.db.close #关闭数据库连接
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://www.v2ex.com/?tab=tech', callback=self.index_page,validate_cert=False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/?tab="]').items():
self.crawl(each.attr.href, callback=self.tab_page, validate_cert=False)
@config(priority=2)
def tab_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/go/"]').items():
self.crawl(each.attr.href, callback=self.board_page, validate_cert=False)
@config(priority=2)
def board_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/t/"]').items():
url = each.attr.href
if url.find('#reply') > 0:
url = url[0:url.find('#')]
self.crawl(url, callback=self.detail_page, validate_cert=False)
@config(priority=2)
def detail_page(self, response):
title = response.doc('h1').text()
content = response.doc('div.topic_content').html().replace('" ','\\') #数据库中不能带有“等字符,替换掉
self.add_question(title,content) #爬取的数据插入数据库中
return {
"url": response.url,
"title": response.doc('title').text(),
}插入后效果:
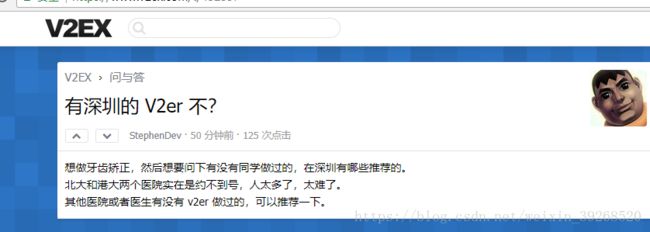
insert into question(title, content, user_id, created_date,comment_count) values("有深圳的 V2er 不?", "想做牙齿矫正,然后想要问下有没有同学做过的,在深圳有哪些推荐的。
北大和港大两个医院实在是约不到号,人太多了,太难了。
其他医院或者医生有没有 v2er 做过的,可以推荐一下。" , 5, now() , 0)
17
{'title': u'有深圳的 V2er 不? - V2EX',
'url': 'https://www.v2ex.com/t/452557'}![]()
显示在自己项目中如图:

源数据:
实现多页爬取:
先查看分页的特点:
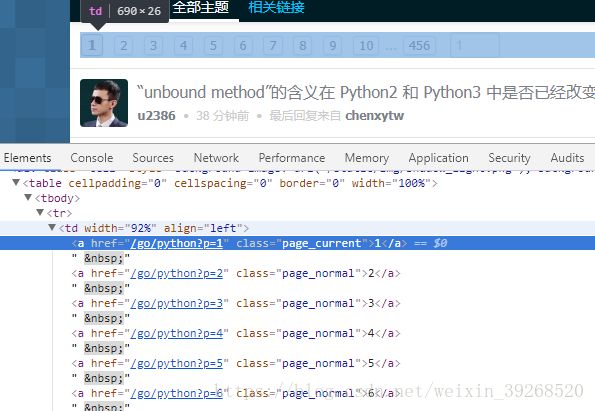
都是page_normal
代码:
@config(priority=2)
def board_page(self, response):
for each in response.doc('a[href^="https://www.v2ex.com/t/"]').items(): #爬取当前页面
url = each.attr.href
if url.find('#reply') > 0:
url = url[0:url.find('#')]
self.crawl(url, callback=self.detail_page, validate_cert=False)
for each in response.doc('a.page_normal').items(): #抓取页面后,继续抓取翻页的链接
self.crawl(each.attr.href, callback=self.board_page, validate_cert=False) #抓取翻页后,注意此时的callback为他自己,继续循环抓取当前页面和其他翻页代码写完后:
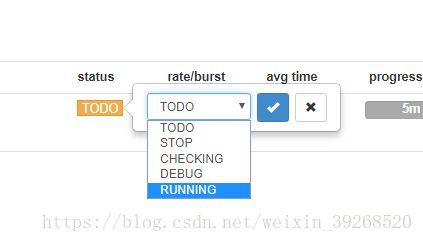
调到running模式

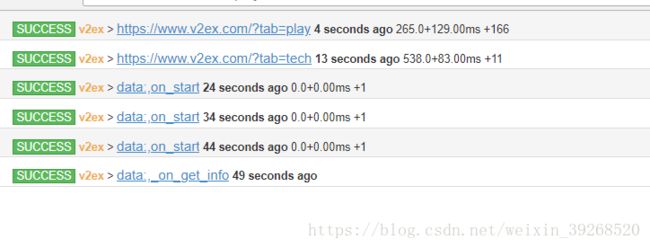
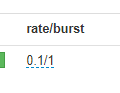 参数意义为1秒钟跑0.1次,也可以自行修改
参数意义为1秒钟跑0.1次,也可以自行修改
就开始不停的跑了!