Python中多线程的资源竞争及解决方案
首先要明确一点, Python中的多线程并不是真正地多个任务同步执行, 而是给每个任务分配一部分的执行时间, 轮流执行, 因此资源竞争的问题就会随之而来
比如当有两个线程或者多个线程对同一全局变量同时操作时, 问题就会产生
资源竞争产生的问题
import threading
import time
def add_a(count):
global num
print('a是'+str(num))
for i in range(count):
num += 1
print('a最终是'+str(num))
def add_b(count):
global num
print('b是'+str(num))
for i in range(count):
num += 1
print('b最终是'+str(num))
def main():
t1 = threading.Thread(target=add_a, args=(1000000,))
t2 = threading.Thread(target=add_b, args=(1000000,))
t1.start()
t2.start()
time.sleep(1)
print(num)
num = 0
lock = threading.Lock()
if __name__ == '__main__':
main()
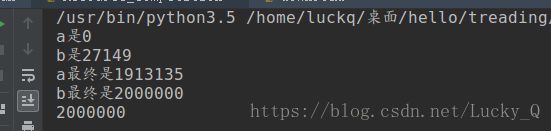
这里我们会发现, 我们给两个函数传递的参数是1000000,每个函数都是进行100w次的+1操作, 按照我们的常识来说, 最后的结果应该是200w才对, 但是结果却是1514861(这里的结果并不是固定的)
产生这种结果的原因是因为python的解释器会把一个简单的+1操作分成多步:
- 获取num的值
- 将num的值+1
- 将运算完成的值赋给num
又因为这是多线程的, 所以cpu在处理两个线程的时候, 是采用雨露均沾的方式, 可能在线程一刚刚将num值+1还没来得及将新值赋给num时, 就开始处理线程二了, 因此当线程二执行完全部的num+=1的操作后, 可能又会开始对线程一的未完成的操作, 而此时的操作停留在了完成运算未赋值的那一步, 因此在完成对num的赋值后, 就会覆盖掉之前线程二对num的+1操作
解决问题
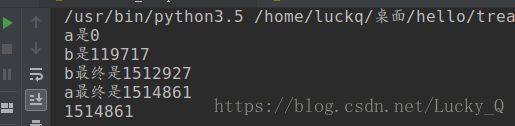
在threading中有一个Lock类,通过调用Lock类中的acquire()方法, 可以将后面的代码保护起来一直执行, 其他的线程会处于监听状态,直到监听到那个线程调用了release()方法解锁, 才会继续争夺对cpu的使用权
import threading
import time
def add_a(count):
global num
print('a是'+str(num))
for i in range(count):
lock.acquire()
num += 1
lock.release()
print('a最终是'+str(num))
def add_b(count):
global num
print('b是'+str(num))
for i in range(count):
lock.acquire()
num += 1
lock.release()
print('b最终是'+str(num))
def main():
t1 = threading.Thread(target=add_a, args=(1000000,))
t2 = threading.Thread(target=add_b, args=(1000000,))
t1.start()
t2.start()
time.sleep(1)
print(num)
num = 0
lock = threading.Lock()
if __name__ == '__main__':
main()