电影信息爬取
文章目录
- 1.抓包分析
- 1.1 网页分析
- 1.2如何进行抓包
- 2.电影信息爬取
- 2.1爬取第一页
- 2.1.1请求网页
- 2.1.2获取text内容:
- 2.1.3获取json内容:
- 2.1.4xpath提取内容
- 2.2爬取2020所有电影信息
- 3将爬取内容写入CSV文件
- 4.代码汇总
1.抓包分析
网址:电影票房
1.1 网页分析
在爬取网页内容之前,第一件事就是分析它的网页数据的加载方式,再决定我请求服务器的方式。
我们点击第二页时发现网页的URL没有发生改变,可以初步判断它是ajax加载的数据,所以我们可以通过抓包的方式来获取内容。
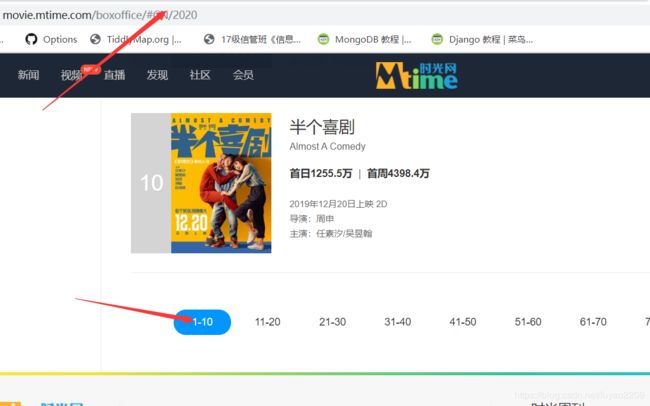

1.2如何进行抓包
如何进行抓包在我的另一篇博客里面有说到:python爬取美团评论

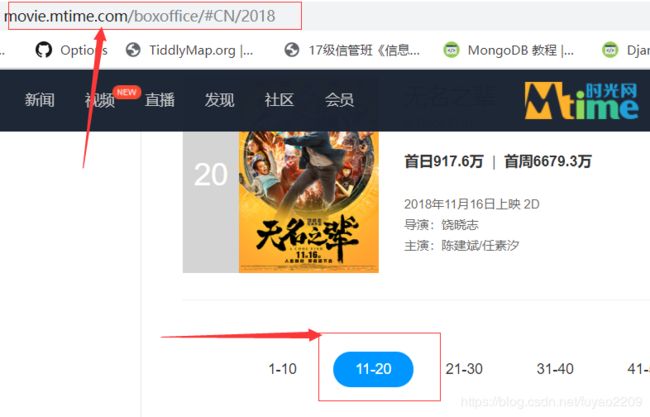
选择了第1、2、3和最后一页的链接进行了比较,它们的参数有两处不同,但时间戳那里不是该链接的关键信息,并不能影响到链接,所以不用管它,仅需关注page=那里即刻,间隔为1。
2.电影信息爬取
这里爬取的是2020年的
2.1爬取第一页
2.1.1请求网页
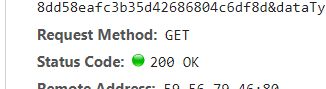
返回200才是请求成功。
# 请求网页
import requests
ajax_url="http://movie.mtime.com/boxoffice/?year=2020&area=china&type=MovieRankingYear&category=all&page=0&display=list×tamp=1587194660511&version=07bb781100018dd58eafc3b35d42686804c6df8d&dataType=json"
#字典型,代理
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
response=requests.get(url=ajax_url,headers=headers)
print(response)
<Response [521]>
结果我们发现没有请求成功,该网页有反爬虫机制,因此要用到它的Cookie值。
重新请求网页:
Cookie值的查找:

# 请求网页
import requests
ajax_url="http://movie.mtime.com/boxoffice/?year=2020&area=china&type=MovieRankingYear&category=all&page=0&display=list×tamp=1587194660511&version=07bb781100018dd58eafc3b35d42686804c6df8d&dataType=json"
#字典型,代理
headers={
"Cookie": "_userCode_=202041883428296; _userIdentity_=202041883428359; userId=0; defaultCity=%25E5%25B9%25BF%25E4%25B8%259C%257C364; DefaultCity-CookieKey=364; DefaultDistrict-CookieKey=0; _tt_=B74386D6D79B43F16B312C45BE7A7DB0; __utma=221034756.1561762253.1587170071.1587170071.1587170071.1; __utmc=221034756; __utmz=221034756.1587170071.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); Hm_lvt_6dd1e3b818c756974fb222f0eae5512e=1587171337; Hm_lpvt_6dd1e3b818c756974fb222f0eae5512e=1587172633; _ydclearance=09eee44c9074eb37d3084533-c8e1-45e0-9eda-fcc89987393c-1587200396",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
response=requests.get(url=ajax_url,headers=headers)
print(response)
<Response [200]>
返回200,请求网页成功。
2.1.2获取text内容:
print(response.text)
结果为:

我仅需要获取其中的一些信息,把所得结果复制到json解析去解析,我们只要html标签中的内容。

2.1.3获取json内容:
response.json()["html"]
结果:

2.1.4xpath提取内容
我们使用xpath时,也必须先对网页进行 lxml 库中的 etree解析 ,把它变为特有的树状形式,才能通过它进行节点定位。
#解析网页
from lxml import etree
html_etree=etree.HTML(response.json()["html"])
#看成一个筛子,树状
1.提取电影名称:
html_etree.xpath('/html/body/div[3]/div[2]/div[1]/div[2]/div/dd[1]/div/div[2]/h3/a/text()')
结果:
[]
然后我们发现没有提取到信息,所以直接法制其xpath 的方法不可取,因此我们需要自己构造它的xpath


重新构造的原因是如果从html开始定位会出现模糊定位,无法定位到我们想要的地方。
然后我们重新来提取信息:
html_etree.xpath('//div[@class="boxofficelist"]/div/dd[1]/div/div[2]/h3/a/text()')
['宠爱']
这里就提取成功了。
2.提取电影排名
同样的这里也需要构造它的xpath,与上面的构造方法一样,我们只要找到排名对应的标签即刻。
提取信息:
html_etree.xpath('//div[@class="boxofficelist"]/div/dd[1]/div/div[1]/i/text()')
结果:
['01']
同等方法获取其他单个电影信息。
3.获取本页所有电影名称,这里写一个for循环来实现
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
name=item.xpath('./div/div[2]/h3/a/text()')
print(name)
结果:
['宠爱']
['叶问4:完结篇']
['误杀']
['变身特工']
['我为你牺牲']
['美丽人生']
['天使陷落']
['紫罗兰永恒花园外传:永远与自动手记人偶']
['鲨海逃生']
['半个喜剧']
4.获取本页所有排名和电影名称
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
name=item.xpath('./div/div[2]/h3/a/text()')
rank=item.xpath('./div/div[1]/i/text()')
print(rank,name)
结果:
['01'] ['宠爱']
['02'] ['叶问4:完结篇']
['03'] ['误杀']
['04'] ['变身特工']
['05'] ['我为你牺牲']
['06'] ['美丽人生']
['07'] ['天使陷落']
['08'] ['紫罗兰永恒花园外传:永远与自动手记人偶']
['09'] ['鲨海逃生']
['10'] ['半个喜剧']

5.到我们获取导演时我们会发现,这样的方式无法获取,接下来我们用模糊匹配

导演这里对应的是第三个p标签
![]()
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
name=item.xpath('./div/div[2]/h3/a/text()')
rank=item.xpath('./div/div[1]/i/text()')
daypiao=item.xpath('./div/div[2]/p[1]/strong[1]/text()')#首日票房
weekpiao=item.xpath('./div/div[2]/p[1]/strong[2]/text()')#首周票房
time=item.xpath('./div/div[2]/p[2]/text()')#上映时间
#director=item.xpath('./div/div[2]/b/p[1]/a/text()')
director=item.xpath('./div/div[2]//p[3]/a/text()')#模糊匹配
print(rank+name+daypiao+weekpiao+time+director)
结果:
['01', '宠爱', '1.72', '4.37', '2019年12月31日上映\xa02D', '杨子']
['02', '叶问4:完结篇', '9723.4', '3.24', '2019年12月20日上映\xa02D/中国巨幕', '叶伟信']
['03', '误杀', '4649.7', '2.02', '2019年12月13日上映\xa02D/IMAX/中国巨幕', '柯汶利']
['04', '变身特工', '455.0', '2537.6', '2020年01月03日上映\xa02D/3D', '特洛伊·奎安']
['05', '我为你牺牲', '258.6', '993.3', '2019年12月05日上映\xa02D', '安战军']
['06', '美丽人生', '690.4', '2389.1', '2020年01月03日上映\xa02D', '罗伯托·贝尼尼']
['07', '天使陷落', '1157.4', '4123.7', '2019年12月31日上映\xa02D', '里克·罗曼·沃夫']
['08', '紫罗兰永恒花园外传:永远与自动手记人偶', '873.0', '2304.1', '2020年01月10日上映\xa02D', '藤田春香']
['09', '鲨海逃生', '1113.3', '2445.6', '2020年01月10日上映\xa02D', '约翰内斯·罗伯茨']
['10', '半个喜剧', '1255.5', '4398.4', '2019年12月20日上映\xa02D', '周申']
这次就成功获取导演了。
6.获取演员时也出现和获取导演的同样的问题,运用同样的方法即刻
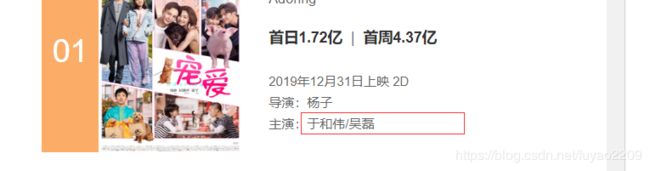
然后我们发现主演并非一个,如果要获取全部主演名字,不给a值就可以了。

代码:
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
name=item.xpath('./div/div[2]/h3/a/text()')
rank=item.xpath('./div/div[1]/i/text()')
daypiao=item.xpath('./div/div[2]/p[1]/strong[1]/text()')#首日票房
weekpiao=item.xpath('./div/div[2]/p[1]/strong[2]/text()')#首周票房
time=item.xpath('./div/div[2]/p[2]/text()')#上映时间
#director=item.xpath('./div/div[2]/b/p[1]/a/text()')
director=item.xpath('./div/div[2]//p[3]/a/text()')#模糊匹配
actor=item.xpath('./div/div[2]//p[4]/a/text()')#获取全部
print(rank+name+daypiao+weekpiao+time+director+actor)
结果:

把演员输出成用“、”隔开的
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
actor=item.xpath('./div/div[2]//p[4]/a/text()')#获取全部
act="、".join(actor)#拼接字符串
act=[act]#数组形式
print( act)
结果;

7.获取本页所以内容
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
rank=item.xpath('./div/div[1]/i/text()')
name=item.xpath('./div/div[2]/h3/a/text()')
daypiao=item.xpath('./div/div[2]/p[1]/strong[1]/text()')#首日票房
weekpiao=item.xpath('./div/div[2]/p[1]/strong[2]/text()')#首周票房
yearpiao=item.xpath('./div/div[4]/p[1]/strong/text()')#年度票房
time=item.xpath('./div/div[2]/p[2]/text()')#上映时间
#director=item.xpath('./div/div[2]/b/p[1]/a/text()')
director=item.xpath('./div/div[2]//p[3]/a/text()')#模糊匹配
actor=item.xpath('./div/div[2]//p[4]/a/text()')#获取全部主演
act="、".join(actor)#拼接字符串
act=[act]#数组形式
ren=item.xpath('./div/div[3]/p[2]/text()')
ren=[(ren[0].replace("人评分",""))]#替换掉“人评分”
print(rank+name+daypiao+weekpiao+yearpiao+time+director+act+ren)
结果:
['01', '红海行动', '1.29', '4.65', '36.51', '2018年02月16日上映\xa02D/3D/IMAX3D', '林超贤', '张译、黄景瑜', '10410']
['02', '唐人街探案2', '3.41', '9.90', '33.98', '2018年02月16日上映\xa02D/IMAX/中国巨幕', '陈思诚', '王宝强、刘昊然', '6048']
['03', '我不是药神', '1.60', '11.72', '30.98', '2018年07月05日上映\xa02D/IMAX/中国巨幕', '文牧野', '徐峥、周一围', '9537']
['04', '西虹市首富', '2.27', '9.02', '25.45', '2018年07月27日上映\xa02D/IMAX', '闫非', '沈腾、宋芸桦', '6298']
['05', '复仇者联盟3:无限战争', '3.87', '12.13', '23.90', '2018年05月11日上映\xa03D/IMAX3D/中国巨幕', '安东尼·罗素', '小罗伯特·唐尼、克里斯·埃文斯', '8647']
['06', '捉妖记2', '5.47', '12.04', '22.37', '2018年02月16日上映\xa02D/IMAX/中国巨幕', '许诚毅', '梁朝伟、白百何', '3705']
['07', '毒液:致命守护者', '2.23', '7.49', '18.66', '2018年11月09日上映\xa03D/IMAX3D/中国巨幕', '鲁本·弗雷斯彻', '汤姆·哈迪、米歇尔·威廉姆斯', '4668']
['08', '海王', '1.57', '6.42', '18.48', '2018年12月07日上映\xa03D/IMAX3D/中国巨幕', '温子仁', '杰森·莫玛、艾梅柏·希尔德', '6541']
['09', '侏罗纪世界2', '2.02', '7.21', '16.96', '2018年06月15日上映\xa02D/3D/IMAX3D', '胡安·安东尼奥·巴亚纳', '克里斯·帕拉特、布莱丝·达拉斯·霍华德', '4079']
['10', '前任3:再见前任', '6449.1', '2.81', '16.47', '2017年12月29日上映\xa02D', '田羽生', '韩庚、郑恺', '3859']
2.2爬取2020所有电影信息
代码:
import requests
from lxml import etree
#字典型,代理
headers={
"Cookie": "_userCode_=202041883428296; _userIdentity_=202041883428359; userId=0; defaultCity=%25E5%25B9%25BF%25E4%25B8%259C%257C364; DefaultCity-CookieKey=364; DefaultDistrict-CookieKey=0; _tt_=B74386D6D79B43F16B312C45BE7A7DB0; __utma=221034756.1561762253.1587170071.1587170071.1587170071.1; __utmc=221034756; __utmz=221034756.1587170071.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); Hm_lvt_6dd1e3b818c756974fb222f0eae5512e=1587171337; Hm_lpvt_6dd1e3b818c756974fb222f0eae5512e=1587172633; _ydclearance=09eee44c9074eb37d3084533-c8e1-45e0-9eda-fcc89987393c-1587200396",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
for page in range(10):
ajax_url="http://movie.mtime.com/boxoffice/?year=2020&area=china&type=MovieRankingYear&category=all&page=0&display=list×tamp=1587194660511&version=07bb781100018dd58eafc3b35d42686804c6df8d&dataType=json"
response=requests.get(url=ajax_url,headers=headers)
response.json()["html"]
print("第%s页.................."%page)
#解析网页
from lxml import etree
html_etree=etree.HTML(response.json()["html"])#看成一个筛子,树状
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
rank=item.xpath('./div/div[1]/i/text()')
name=item.xpath('./div/div[2]/h3/a/text()')
daypiao=item.xpath('./div/div[2]/p[1]/strong[1]/text()')#首日票房
weekpiao=item.xpath('./div/div[2]/p[1]/strong[2]/text()')#首周票房
yearpiao=item.xpath('./div/div[4]/p[1]/strong/text()')#年度票房
time=item.xpath('./div/div[2]/p[2]/text()')#上映时间
#director=item.xpath('./div/div[2]/b/p[1]/a/text()')
director=item.xpath('./div/div[2]//p[3]/a/text()')#模糊匹配
actor=item.xpath('./div/div[2]//p[4]/a/text()')#获取全部主演
act="、".join(actor)#拼接字符串
act=[act]#数组形式
ren=item.xpath('./div/div[3]/p[2]/text()')
ren=[(ren[0].replace("人评分",""))]#替换掉“人评分”
print(rank+name+daypiao+weekpiao+yearpiao+time+director+act+ren)
print("~"*60)
结果:

3将爬取内容写入CSV文件
步骤:
- 打开文件夹
- 放进文件夹
- 关闭文件夹
#导入包
import csv
# 创建文件夹并打开
fp = open("./电影信息2020.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #写入内容
# 写入内容
writer.writerow(('排名', '名称', '首日票房', '首周票房','年度票房','上映时间','导演','主演', '评价人数'))
#关闭文件
fp.close()
4.代码汇总
import requests,csv,time
from lxml import etree
#字典型,代理
headers={
"Cookie": "_userCode_=202041883428296; _userIdentity_=202041883428359; userId=0; defaultCity=%25E5%25B9%25BF%25E4%25B8%259C%257C364; DefaultCity-CookieKey=364; DefaultDistrict-CookieKey=0; _tt_=B74386D6D79B43F16B312C45BE7A7DB0; __utmc=221034756; __utmz=221034756.1587170071.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); Hm_lvt_6dd1e3b818c756974fb222f0eae5512e=1587171337; Hm_lpvt_6dd1e3b818c756974fb222f0eae5512e=1587194669; __utma=221034756.1561762253.1587170071.1587170071.1587194671.2; _ydclearance=cb9e61b6f183fbce6e387f64-f64f-49b0-a970-dd340d436c93-1587292922",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
# 创建文件夹并打开
fp = open("./电影信息2020.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #写入内容
# 写入内容
writer.writerow(('排名', '名称', '首日票房', '首周票房','年度票房','上映时间','导演','主演', '评价人数'))
for page in range(10):
ajax_url="http://movie.mtime.com/boxoffice/?year=2020&area=china&type=MovieRankingYear&category=all&page=%s&display=list×tamp=1587194660511&version=07bb781100018dd58eafc3b35d42686804c6df8d&dataType=json"%page
response=requests.get(url=ajax_url,headers=headers)
response.json()["html"]
print("第%s页.................."%page)
#解析网页
from lxml import etree
html_etree=etree.HTML(response.json()["html"])#看成一个筛子,树状
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
rank=item.xpath('./div/div[1]/i/text()')
name=item.xpath('./div/div[2]/h3/a/text()')
daypiao=item.xpath('./div/div[2]/p[1]/strong[1]/text()')#首日票房
weekpiao=item.xpath('./div/div[2]/p[1]/strong[2]/text()')#首周票房
yearpiao=item.xpath('./div/div[4]/p[1]/strong/text()')#年度票房
time=item.xpath('./div/div[2]/p[2]/text()')#上映时间
#director=item.xpath('./div/div[2]/b/p[1]/a/text()')
director=item.xpath('./div/div[2]//p[3]/a/text()')#模糊匹配
actor=item.xpath('./div/div[2]//p[4]/a/text()')#获取全部主演
act="、".join(actor)#拼接字符串
act=[act]#数组形式
ren=item.xpath('./div/div[3]/p[2]/text()')
ren=[(ren[0].replace("人评分",""))]#替换掉“人评分”
result=(rank+name+daypiao+weekpiao+yearpiao+time+director+act+ren)
# 写入内容
writer.writerow(result)
fp.close()
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)
print ("该次所获的信息一共使用%s秒"%useTime)
jupyter结果:

然后我们发现在爬了第1、2页后就报错了,显示超出列表队列。

重新对网页进行分析我们可以看到一些电影没有评分,因此我们需要用到try…except来进行错误内容的跳过。
2.
import requests,csv,time
from lxml import etree
#字典型,代理
headers={
"Cookie": "_userCode_=2020419175824138; _userIdentity_=2020419175826736; userId=0; defaultCity=%25E5%25B9%25BF%25E4%25B8%259C%257C364; DefaultCity-CookieKey=364; DefaultDistrict-CookieKey=0; _tt_=B74386D6D79B43F16B312C45BE7A7DB0; __utmz=221034756.1587170071.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); Hm_lvt_6dd1e3b818c756974fb222f0eae5512e=1587171337,1587290283; Hm_lpvt_6dd1e3b818c756974fb222f0eae5512e=1587290283; __utma=221034756.1561762253.1587170071.1587285756.1587290286.4; __utmc=221034756; _ydclearance=b125e678e28b6694bcc33789-5513-4e2b-996c-e7f92cf3080a-1587300401",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36"
}
# 创建文件夹并打开
fp = open("./电影信息2020.csv", 'a', newline='', encoding = 'utf-8-sig')
writer = csv.writer(fp) #写入内容
# 写入内容
writer.writerow(('排名', '名称', '首日票房', '首周票房','年度票房','上映时间','导演','主演', '评价人数'))
for page in range(10):
ajax_url="http://movie.mtime.com/boxoffice/?year=2020&area=china&type=MovieRankingYear&category=all&page=%s&display=list×tamp=1587194660511&version=07bb781100018dd58eafc3b35d42686804c6df8d&dataType=json"%page
response=requests.get(url=ajax_url,headers=headers)
response.json()["html"]
print("第%s页.................."%page)
#解析网页
from lxml import etree
html_etree=etree.HTML(response.json()["html"])#看成一个筛子,树状
li=html_etree.xpath('//div[@class="boxofficelist"]/div/dd')
for item in li:
try:
rank=item.xpath('./div/div[1]/i/text()')
name=item.xpath('./div/div[2]/h3/a/text()')
daypiao=item.xpath('./div/div[2]/p[1]/strong[1]/text()')#首日票房
weekpiao=item.xpath('./div/div[2]/p[1]/strong[2]/text()')#首周票房
yearpiao=item.xpath('./div/div[4]/p[1]/strong/text()')#年度票房
time=item.xpath('./div/div[2]/p[2]/text()')#上映时间
#director=item.xpath('./div/div[2]/b/p[1]/a/text()')
director=item.xpath('./div/div[2]//p[3]/a/text()')#模糊匹配
actor=item.xpath('./div/div[2]//p[4]/a/text()')#获取全部主演
act="、".join(actor)#拼接字符串
act=[act]#数组形式
ren=item.xpath('./div/div[3]/p[2]/text()')
ren=[(ren[0].replace("人评分",""))]#替换掉“人评分”
result=(rank+name+daypiao+weekpiao+yearpiao+time+director+act+ren)
# 写入内容
writer.writerow(result)
except:
pass
fp.close()
jupyter结果:

CSV文件截屏: