Redis Pipeline管道使用
1.Redis单条命令使用场景
Redis客户端连接到Redis服务端执行一条命令需要经历的步骤如下:

以上过程称为Round Trip Time(RTT,往返时间),mget和mset命令节约了RTT,但是大部分指令不支持批量操作。
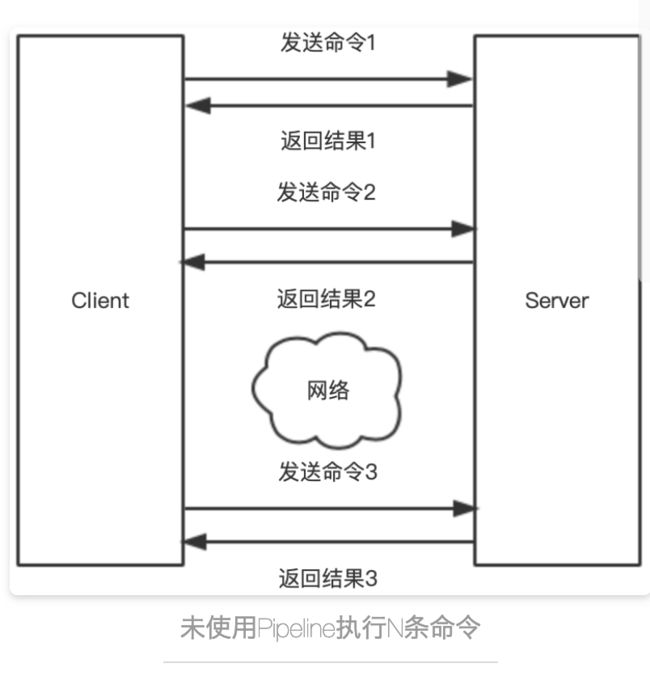
Redis通过TCP来对外提供服务,Client通过Socket连接发起请求,每个请求在命令发出后会阻塞等待Redis服务器进行处理,处理完毕后将结果返回给client。
Redis的Client和Server是采用一问一答的形式进行通信,请求一次给一次响应。而这个过程在排除掉Redis服务本身做复杂操作时的耗时的话,可以看到最耗时的就是这个网络传输过程。每一个命令都对应了发送、接收两个网络传输,假如一个流程需要0.1秒,那么1秒最多只能处理10个请求,将严重制约Redis的性能。
在很多场景下,我们要完成一个业务,可能会对redis做连续的多个操作,譬如库存减一、订单加一、余额扣减等等,这有很多个步骤是需要依次连续执行的。
2.Redis单条命令执行耗时
正常情况下,Redis单条命令的执行时间是毫秒级别的。大部分的Redis命令可以在2ms内返回。因此Redis的执行时非常快的。但是在高并发场景下,同时操作大量的Redis KEY可能并不能满足高性能的要求。
假设有一个请求,需要批量校验某个用户能否参与现有的10000个返利活动,用户能否参与返利活动使用Redis KEY记录和存储的。正常情况下,需要使用for循环遍历每个活动,校验用户能否参加每一个活动。
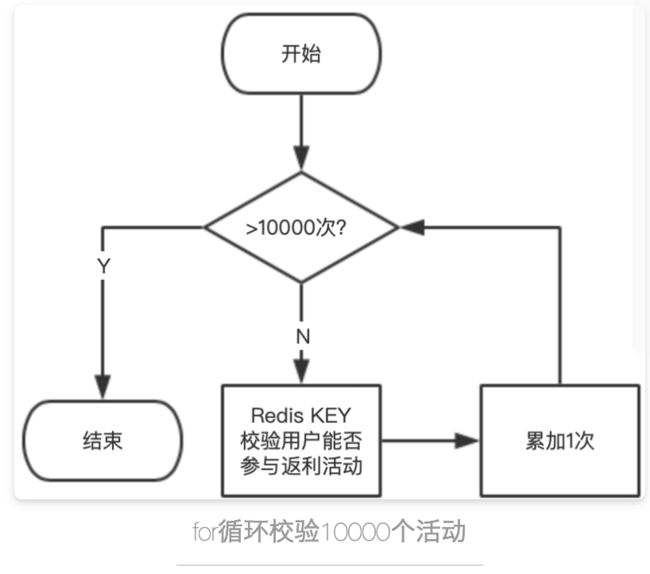
假设每个Redis命令执行时间为1ms,校验10000个活动需要的时间=10000 * 1ms = 10s,即一个接口需要10s才能响应结果,这显然不能满足现实的需求。
3.Redis连接池
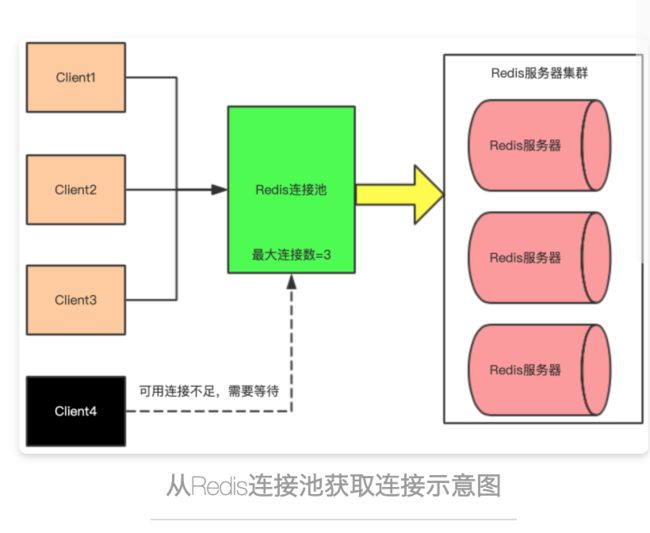
除了第2点中描述的接口响应时间较慢的问题外,还有一个问题:一个接口中进行多次Redis KEY的操作,造成Redis连接池的连接长时间得不到释放,因此可能会造成连接池中的连接很快就被前几个线程所占有,迟迟得不到释放,并发量较高时,大量线程得不到连接池中的连接而造成大量线程等待超时。
4.Redis Pipeline管道命令的使用
Pipeline命令原理如下图所示。

Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。这意味着通常情况下一个请求会遵循以下步骤:
1.客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。 2.服务端处理命令,并将结果返回给客户端。
Redis管道技术可以在服务端未响应时,客户端可以继续向服务端发送请求,并最终一次性读取所有服务端的响应。这样可以最大限度的利用Redis的高性能并节省不必要的网络IO开销。
不使用Pipeline命令执行单条set命令100000次
/**
* 不使用Pipeline命令
* @param count 操作的命令个数
* @return 执行时间
*/
@GetMapping("redis/no/pipeline/{count}")
public String testWithNoPipeline(@PathVariable("count") String count) {
// 开始时间
long start = System.currentTimeMillis();
// 参数校验
if (StringUtils.isEmpty(count)) {
throw new IllegalArgumentException("参数异常");
}
// for循环执行N次Redis操作
for (int i = 0 ; i < Integer.parseInt(count); i++) {
// 设置K-V
stringRedisTemplate.opsForValue().set(String.valueOf(i),
String.valueOf(i), 1, TimeUnit.HOURS);
}
// 结束时间
long end = System.currentTimeMillis();
// 返回总执行时间
return "执行时间等于=" + (end - start) + "毫秒";
}
浏览器输入以下URL:
http://localhost:8080/redis/no/pipeline/10000
验证Redis执行结果如下。
执行结果为2191毫秒。
执行以下命令清空刚刚执行的代码向Redis保存的结果。
flushall
通过Pipeline命令保存10000条数据
/**
* 使用Pipeline命令
* @param count 操作的命令个数
* @return 执行时间
*/
@GetMapping("redis/pipeline/{count}")
public String testWithPipeline(@PathVariable("count") String count) {
// 开始时间
long start = System.currentTimeMillis();
// 参数校验
if (StringUtils.isEmpty(count)) {
throw new IllegalArgumentException("参数异常");
}
/* 插入多条数据 */
stringRedisTemplate.executePipelined(new SessionCallback浏览器输入以下URL:
http://localhost:8080/redis/pipeline/10000
执行以上代码,执行结果为161毫秒。
由以上测试结果可知,Redis Pipeline可以大幅提升多个key交互时的性能。
以上是单条set命令和Pipeline执行set命令执行对比,下面执行单条get命令和Pipeline执行get命令。
测试单条get命令,for循环10000次
/**
* 不使用Pipeline命令单条执行get命令
*
* @param count 操作的命令个数
* @return 执行时间
*/
@GetMapping("redis/no/pipeline/get/{count}")
public Map testGetWithNoPipeline(@PathVariable("count") String count) {
// 开始时间
long start = System.currentTimeMillis();
// 参数校验
if (StringUtils.isEmpty(count)) {
throw new IllegalArgumentException("参数异常");
}
List resultList = new ArrayList<>();
// for循环执行N次Redis操作
for (int i = 0; i < Integer.parseInt(count); i++) {
// 获取K-V
resultList.add(stringRedisTemplate.opsForValue().get(String.valueOf(i)));
}
// 结束时间
long end = System.currentTimeMillis();
Map resultMap = new HashMap<>(4);
resultMap.put("执行时间", (end - start) + "毫秒");
resultMap.put("执行结果", resultList);
// 返回resultMap
return resultMap;
}
执行以下URL:
http://localhost:8080/redis/no/pipeline/get/10000
执行结果如下。

测试Pipeline 执行get命令,获取10000条数据
/**
* 使用Pipeline命令
*
* @param count 操作的命令个数
* @return 执行时间
*/
@GetMapping("redis/pipeline/get/{count}")
public Map testGetWithPipeline(@PathVariable("count") String count) {
// 开始时间
long start = System.currentTimeMillis();
// 参数校验
if (StringUtils.isEmpty(count)) {
throw new IllegalArgumentException("参数异常");
}
// for循环执行N次Redis操作
/* 批量获取多条数据 */
List 执行以下URL:
http://localhost:8080/redis/pipeline/get/10000
执行结果如下。

执行总耗时为18毫秒。
5.总结
使用管道不仅仅是为了降低RTT以减少延迟成本, 实际上使用管道也能大大提高Redis服务器中每秒可执行的总操作量. 这是因为, 在不使用管道的情况下, 尽管操作单个命令开起来十分简单, 但实际上这种频繁的I/O操作造成的消耗是巨大的, 这涉及到系统读写的调用, 这意味着从用户域到内核域.上下文切换会对速度产生极大的损耗.
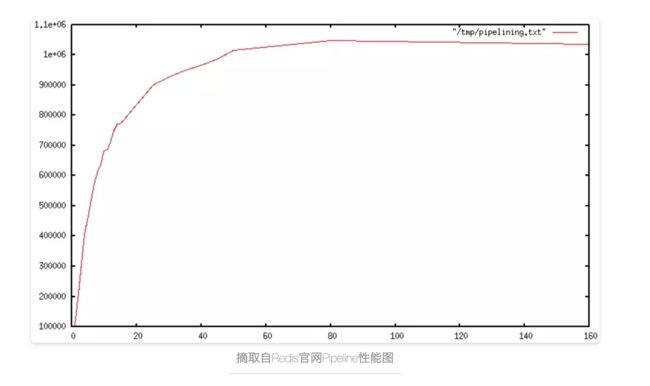
使用管道操作时, 通常使用单个read() 系统调用读取许多命令,并通过单个write()系统调用传递多个回复. 因此, 每秒执行的总查询数最初会随着较长的管道线性增加, 并最终达到不使用管道技术获的10倍, 如下图所示: