java知识加固
native方法表示该方法要用另外一种依赖平台的编程语言实现。
整型默认类型是int ,浮点型默认类型是double。
从JDK1.5以后引入了三种常用新特性:泛型,枚举,注解。
Java的三大特性:封装 继承 多态。
多态
主要表现在方法的多态:方法的重载,方法的覆写。
对象的多态:向上转型 向下转型
java 中的instanceof
java 中的instanceof 运算符是用来在运行时指出对象是否是特定类的一个实例。instanceof通过返回一个布尔值来指出,这个对象是否是这个特定类或者是它的子类的一个实例。
用法:
result = object instanceof class
参数:
Result:布尔类型。
Object:必选项。任意对象表达式。
Class:必选项。任意已定义的对象类。
说明:
如果 object 是 class 的一个实例,则 instanceof 运算符返回 true。如果 object 不是指定类的一个实例,或者 object 是 null,则返回 false。
Java类为了方便开发,专门提供了包装类的使用,而对于包装类的使用,提供了两种数据类型。
对象型(Object的直接子类):Boolean Character(char);
数值型(Number的直接子类):Byte Double Short Long Integer(int) Float
数组
数组动态初始化(声明并开辟数组):数据类型[] 数组名称=new 数据类型[长度];
数组静态初始化:数据类型[] 数组名称={ };
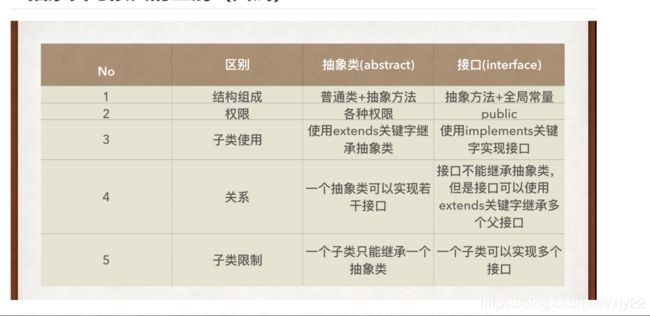
抽象类
1.在普通类的基础上扩充了一些抽象方法而已,要求使用abstract关键字来定义,抽象方法也需要使用abstract关键字来修饰。抽象类中允许不定义任何的抽象方法,但是此时抽象类依然无法直接创建实例化方法。
2.抽象类不能直接产生实例化对象,但是在抽象类中也允许提供构造方法,并且子类也照样遵循对象实例化流程。实例化子类的时候一定要调用父类构造方法。如果父类没有无参构造,那么子类构造必须使用super()明确指出使用父类哪个无参构造方法。
3.所有的抽象类必须有子类,抽象类的子类必须覆写抽象类的所有抽象方法(子类不是抽象类)(方法覆写一定要考虑权限问题,尽量用public).
4.抽象类的对象可以通过对象多态性利用子类为其实例化。
5.private和abstract不能同时使用。
6.抽象类可以实现接口,接口可以继承接口。
7.抽象类不能用final声明,因为final声明的类不允许有子类,而抽象类必须有子类;相应的,抽象方法也不能使用private定义,因为抽象方法必须被覆写。
8.抽象类分为内部抽象类和外部抽象类,内部抽象类可以使用static定义描述外部抽象类,外部类不能使用static来修饰。
接口
接口就是一个抽象方法和全局常量的集合,interface关键字。
子类用implements关键字来实现接口,一个子类可以实现多个接口,可以使用接口来实现多继承的概念,对于接口的子类(不是抽象类)必须覆写接口中的全部抽象方法,随后可以利用子类的向上转型通过实例化子类来得到接口的实例化对象。
接口中只允许public 权限。不管是属性还是方法,其权限都是public
在以后编写接口的饿时候,基本只提供抽象方法,很少在接口里提供全局常量;public不会省略,可以省略abstract.
当一个子类既需要实现接口又需要继承抽象类时,请先使用extends继承一个抽象类,而后使用implements实现多个接口。
一个抽象类可以使用implements实现多个接口,但是接口不能继承抽象类。一个接口可以使用extends继承多个父接口。
接口可以定义一系列的内部接口,包括:内部普通类,内部接口,其中static定义的内部接口就相当于一个外部接口
抽象类与接口的区别
static关键字
可以修饰属性和方法
static属性(类属性)
1.传统属性所具备的特征:保存在堆内存中,且每个对象独享属性。static属性由称为类属性,保存在全局数据区的内存之中,所有对象都可以进行该数据区的访问。
2.访问static属性(类属性)应使用类名称.属性名。
3.所有的非static属性(实例变量)必须在对象实例化后使用,而static属性(类属性)不受对象实例化控制。
static方法(类方法)
1.使用static定义的方法,直接通过类名称访问。
2.所有的static方法不允许调用非static定义的属性和方法。所有的非static方法允许访问static方法或属性。
ArrayList和LinkedList的区别
1.在随机访问的时候A优于L,因为L要移动指针,但是A不需要。
2.在数据的新增和删除操作上,L优于A,因为A需要移动数据,而L不需要。
3.数据结构不同:A基于动态数组的数据结构,L基于链表的数据结构。
4.A的速度要比L的速度快,因为A访问数据的时候不像L是从一端到另一端,比较简单。
请解释HashMap与Hashtable的区别。
HashMap:JDK1.2推出 异步处理,性能高 ,非线程安全,允许存放null(有且只有一个)。
在数据量小的时候HashMap是按照链表的模式存储的,当数据量变大之后为了快速查找,会将这个链表变为红黑树(均衡二叉树)来进行保存,用hash码作为数据定位。
HashTable:JDK1.0推出,同步处理,性能较低,线程安全,key与value都不为空,否则出现NullPointerException
public private protected 默认权限
public :
具有最大的访问权限,可以访问任何一个在classpath下的类,接口,异常等。它往往用于对外的情况,也就是对象或类对外的一种接口形式。
protected:
主要的总用是用来保护子类。子类可以调用它修饰的成员,其他类不可以。
defalut:
有时候也称friendly,它是针对于本包访问的,任何处于本包以下的类,接口,异常等,都可以相互访问,即使是父类没有用protected修饰的成员也可以。
private:
访问权限仅限于本类,是一种封装的体现
public>protected>default>private
堆和栈的区别?
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。
当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。
引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
java中变量在内存中的分配
1、类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期--一直持续到整个"系统"关闭
2、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的"物理位置"。 实例变量的生命周期--当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存
3、局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一旦脱离作用域,内存立即释放
java的内存机制
Java 把内存划分成两种:一种是栈内存,另一种是堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配,当在一段代码块定义一个变量时,Java 就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java 会自动释放掉为该变量分配的内存空间,该内存空间可以立即被另作它用。
堆内存用来存放由 new 创建的对象和数组,在堆中分配的内存,由 Java 虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或者对象之后,还可以在栈中定义一个特殊的变量,让栈中的这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或者对象,引用变量就相当于是为数组或者对象起的一个名称。引用变量是普通的变量,定义时在栈中分配,引用变量在程序运行到其作用域之外后被释放。而数组和对象本身在堆中分配,即使程序运行到使用 new 产生数组或者对象的语句所在的代码块之外,数组和对象本身占据的内存不会被释放,数组和对象在没有引用变量指向它的时候,才变为垃圾,不能在被使用,但仍然占据内存空间不放,在随后的一个不确定的时间被垃圾回收器收走(释放掉)。
这也是 Java 比较占内存的原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
视图
视图是一个内容由查询定义的虚拟表,视图的数据变化会影响到基表,基表的数据变化也会影响到视图。
create view 视图名 as select语句
视图和表的区别:
1.表要占用磁盘空间,视图不需要。
2,。视图不能添加索引。
3.使用视图可以简化查询。
4.视图可以提高安全性。
索引
提高数据库的性能,不用加内存,不用改程序,不用调sql,索引可以让查询速度提高成百上千倍,但是是以插入,更新,删除的速度为代价的,·这些写操作,增加了大量的IO。所以他的价值,在于提高一个海量数据的检索速度。
说明:
1.占用磁盘空间
2.当添加一条记录,除了添加到表中,还要维护二叉树,速度有影响,但不大。
3.当我们添加一个索引,不能够解决所有查询问题,需要分别给字段建立索引。
4.索引是以空间换时间。
索引分类
主键索引,唯一索引,普通索引,全文索引
方法的重载和覆写
方法的重写的返回值类型可以相同也可以不同。

Error和Exception的区别:
Error类描述了Java运行时内部错误和我资源耗尽错误。应用程序不抛出此类异常,这种内部错误一旦出现,除了告知用户并使程序安全终止外,在无能为力。这种情况很少出现。
最重要的是Exception以及其子类。在Exception之下又分为RuntimeException和IOEception。
由于程序错误导致的异常属于RuntimeException;而程序本身没有问题,但由于向I/O错误这类问题导致的异常属于IOException。
Java语言规范将派生于Error类或RuntimeException类的所有异常称为非受查异常;所有的其他异常称为受查异常。
线程休眠(sleep方法)
指的是让线程暂缓执行一下,等到了预计时间之后再回复执行。
会交出CPU,让CPU去执行其他任务。但是不会释放锁,也就是说如果当前线程持有对某个对象的锁,则即使调用sleep方法,其他线程也无法访问。
线程让步(yield方法)
暂停当前正在执行的线程对象
请阐述HTTP/HTTPS的区别以及1个HTTP请求交互的完整过程。
http 是基于 TCP 的无连接、无状态的 HTTP 协议
https 则是基于在 TCP 协议之上,加了一层 SSL/TSL 协议,该协议会结合证书对客户端和服务器之间的通信进行加密,确保安全和可信。
区别如下:
- http 明文传输无加密,而 https 对通信信息进行了加密。
- https 需要申请 CA 证书,并且通信过程,由于加解密过程带来额外的时间和计算的消耗。
- 基于 TCP 协议的 HTTP 协议,默认端口为 80,而基于 SSL/TSL 协议的 HTTPS 协议端口为 443。
HTTP请求交互的完整过程
1.连接 2.请求 3.应答 4.关闭连接。.
JDK JRE JVM的关系

sizeof 不是Java的关键字
String 和StringBuffer最大的区别在于:String的内容无法修改,而StringBuffer的内容可以修改。


计算机网络
1.以太网协议:链接层,规定电信号分组形式
2.MAC地址:数据包必须是从一块网卡传递到另一块网卡。网卡的地址就叫MAC地址。
3数据包:一组电信号构成一个数据包,叫做“帧”,标头和数据(链路层)
ARP协议:一块网卡怎么会知道另一块网卡的MAC地址(链路层)
路由:指如何向不同的网络发送数据包(网络层)。
网络地址:网络层的作用是引进一套新的地址,使我们能够区分不同的计算机是属于同一个子网络,这套地址就叫做网址。(网络层)。
SUBSTR用法:
1.SBUSTR(str,pos);
就是从pos开始的位置,一直截取到最后;(A√)
2.1.SBUSTR(str,pos,len);
就是从pos开始的位置,截取len长度;(B√)
RIGHT用法
right(a,b)函数表示的是从字符表达式最右边一个字符开始返回指定数目的字符.若 b 的值大于 a 的长度,则返回字符表达式的全部字符a.如果 b 为负值或 0,则返回空字符串.
(D√)
内部类:
内部类中不能定义静态成员,内部类可以直接访问外部类中的成员变量,内部类可以定义在外部类的方法外面,也可以定义在外部类的方法体中。创建内部类的实例对象时,一定要先创建外部类的实例对象,然后用这个外部类的实例对象去创建内部类的实例对象,代码如下:
Outer outer = new Outer();
Outer.Inner1 inner1 = outer.new Innner1();
最后,在方法外部定义的内部类前面可以加上 static 关键字,从而成为 Static Nested Class,它不再具有
内部类的特性,所有,从狭义上讲,它不是内部类。