Logstash:如何使用 Logstash Grok 过滤器提取模式
Logstash 是数据管道,可帮助我们处理来自各种来源的日志和其他事件数据。 Logstash 拥有 200 多个插件,可以连接到各种源并将数据流式传输到中央分析系统。 Elastic Stack(Elasticsearch,Logstash和Kibana)是管理和分析日志和事件的最佳解决方案之一。
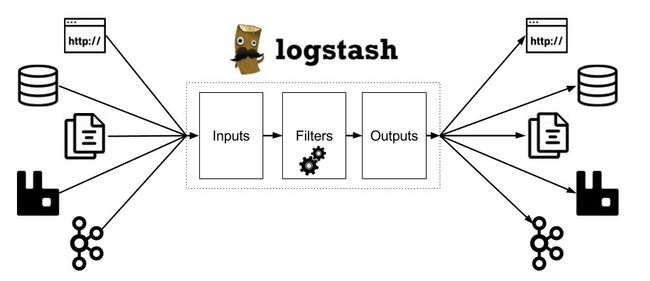
有效分析和查询发送到 Elastic Stack 的数据的能力取决于数据的可读性和质量。 这意味着,如果将非结构化数据(例如纯文本日志)提取到系统中,则必须将其转换为富含有价值字段的结构化形式。 无论数据源是什么,拉动日志并执行一些魔术操作来格式化,转换和丰富它们都是必要的,以确保在将它们发送到 Elasticsearch 之前正确地对其进行了解析。
Logstash 中的数据转换和规范化是使用过滤器插件执行的。本文重点介绍最流行和有用的筛选器插件之一 Logstash Grok 过滤器,该插件用于将非结构化数据解析为结构化数据,并准备好在 Elastic Stack 中进行汇总和分析。这使我们能够使用高级功能,例如对值字段进行统计分析,过滤等。如果我们无法将数据分类并分解为单独的字段,则所有搜索都将是全文搜索,这将使我们无法充分利用 Elasticsearch 和 Kibana 搜索。 Grok 工具非常适合 syslog 日志,Apache 和其他 Web 服务器日志,Mysql 日志,以及一般来说,任何为人类编写的日志格式,包括纯文本。
Grok 过滤器器附带了各种正则表达式和模式,用于你可以在日志中遇到的常见数据类型和表达式(例如 IP,用户名,电子邮件,主机名等)。Logstash 读取日志时,可以使用这些模式来找到我们想要变成结构化字段的日志消息的语义元素。
因此,Grok 过滤器通过将文本模式组合成与您的日志匹配的内容来工作。你可以通过定义 Grok 模式来告诉 Grok 要搜索什么数据:%{SYNTAX:SEMANTIC}
SYNTAX 是将与你的文本匹配的模式的名称。例如,NUMBER模式可以匹配 4.55、4、8 和任何其他数字,而 IP 模式可以匹配54.3.824.2 或 174.49.99.1 等。
SEMANTIC 是赋予匹配文本的标识符。你可以将此标识符视为由 Grok 过滤器创建的键/值对中的键,并且该值是与模式匹配的文本。使用上面的 4.55、4、8 中的示例可以是某个事件的持续时间,而 54.3.824.2 可以是发出请求的客户端。
我们可以使用 Grok 模式将其表示为 %{NUMBER:duration} 和 %{IP:client},然后在过滤器定义中引用它们。
filter {
grok {
match => { "message" => "%{IP:client} %{NUMBER:duration}" }
}
}如前所述,Logstash 附带了许多预定义的模式。 模式由标签和正则表达式组成,例如:
USERNAME [a-zA-Z0-9._-]+让我们看一下其他可用的模式 (你可以在此处找到完整列表):
# Basic Identifiers
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
INT (?:[+-]?(?:[0-9]+))
BASE10NUM (?[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+)))
NUMBER (?:%{BASE10NUM})
BASE16NUM (?# Networking
MAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC})
CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4})
WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2})
COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2})# paths
PATH (?:%{UNIXPATH}|%{WINPATH})
UNIXPATH (/([\w_%!$@:.,+~-]+|\\.)*)+
TTY (?:/dev/(pts|tty([pq])?)(\w+)?/?(?:[0-9]+))
URIHOST %{IPORHOST}(?::%{POSINT:port})?
# uripath comes loosely from RFC1738, but mostly from what Firefox
# doesn't turn into %XX
URIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%&_\-]*)+# Months: January, Feb, 3, 03, 12, December
MONTHNUM (?:0?[1-9]|1[0-2])
MONTHNUM2 (?:0[1-9]|1[0-2])
MONTHDAY (?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) # Log formats
SYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}:# Log Levels
LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)模式的一个强大功能是可以包含其他模式,例如:模式 SYSLOGTIMESTAMP 表达为 %{MONTH} +%{MONTHDAY}%{TIME}
默认情况下,所有语义(例如 DURATION 或 CLIENT)都保存为字符串。 (可选)我们可以向 Grok 模式添加数据类型转换。 例如,%{NUMBER:num:int} 将 num 语义从字符串转换为整数。 当前仅支持 int 和 float 转换。
让我们看一个更实际的示例,以说明 Grok 过滤器的工作原理。 假设我们有这样的 HTTP 日志消息:
55.3.244.1 GET /index.html 15824 0.043许多这样的日志消息存储在 /var/log/http.log 中,因此我们可以使用 Logstash File 输入来添加日志文件的尾部,并在添加新的日志消息时发出事件。 在配置的过滤器部分中,我们定义了语法语义对,这些对使 Grok 过滤器中可用的每个模式与日志消息的特定元素相匹配。
logstash_http.conf
input {
generator {
message => "55.3.244.1 GET /index.html 15824 0.043"
count => 1
}
}
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output {
stdout {
codec => rubydebug
}
}运行上面的配置显示的结果是:

在上面的示例中,我们将日志消息表示为:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}这将为事件添加一些额外的字段(例如 “client” 或 “method”),并将其存储在发送给 Elasticsearch 的索引中。
目标变量
模式可以将匹配的值存储在新字段中。 在 Grok 过滤器中指定字段名称:
filter {
grok {
match => [ "message", "%{USERNAME:user}" ]
}
}这个将匹配小写字母的字符串,并把结果存放于变量 user 中。
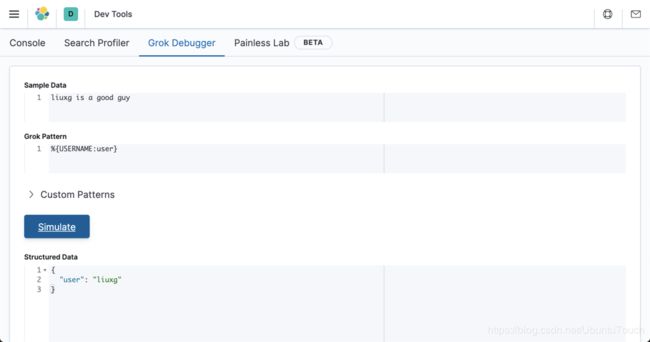
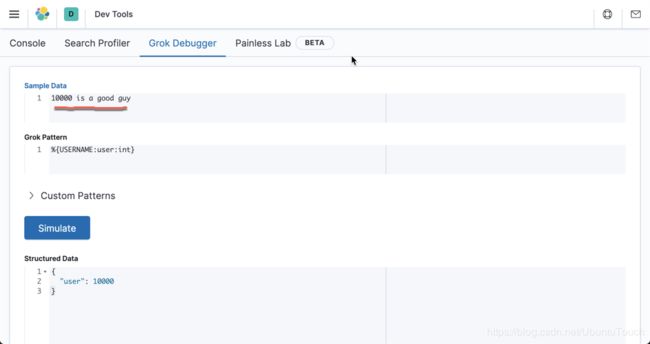
转换
默认情况下,被 Grok 匹配的字段是字符串。 可以在模式中声明数字字段(int 和 float ):
filter {
grok {
match => [ "message", "%{USERNAME:user:int}" ]
}
}
请注意:这只是 Logstash 尝试插入事件时将传递给 Elasticsearch 的提示。 如果该字段已经在索引中存在,并以不同的类型而存在,那么这将不改变当前 Elasticsearch 索引的 mapping。
定制模式
这个在我之前的文章 “Elastic:在 Grok 中运用 custom pattern 来定义 pattern” 已经有描述。你可以详细阅读这篇文章。
有时 Logstash 没有我们需要的模式,因此我们需要一些针对这种情况的选项。
首先,我们可以使用 Oniguruma 语法 进行命名捕获,这将使你匹配一段文本并将其保存为字段:
(?the pattern here) 例如,后缀日志的队列 ID 为10或11个字符的十六进制值。 我们可以像这样轻松捕获:
(?[0-9A-F]{10,11}) 或者,你可以创建一个自定义模式文件。
- 创建一个名为 patterns 的目录,并在其中包含一个名为 extra 的文件。 文件名无关紧要,但请取一个自己认有意义的名字来命名。
- 在该文件中,将所需的模式写为模式名称,一个空格,然后输入该模式的 regexp。
例如,执行上面的后缀队列 ID 示例:
# contents of ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11}然后使用此插件中的 patterns_dir 设置告诉 Logstash 我们的自定义模式目录在哪里。 这是带有示例日志的完整示例:
$ pwd
/Users/liuxg/elastic/logstash-7.8.0
liuxg:logstash-7.8.0 liuxg$ cat ./patterns/extra
# contents of ./patterns/postfix:
POSTFIX_QUEUEID [0-9A-F]{10,11}logstash_custom.conf
input {
generator {
message => "Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<[email protected]>"
count => 1
}
}
filter {
grok {
patterns_dir => ["./patterns"]
match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" }
}
}
output {
stdout {
codec => rubydebug
}
}运行上面的 Logstash 的配置文件:
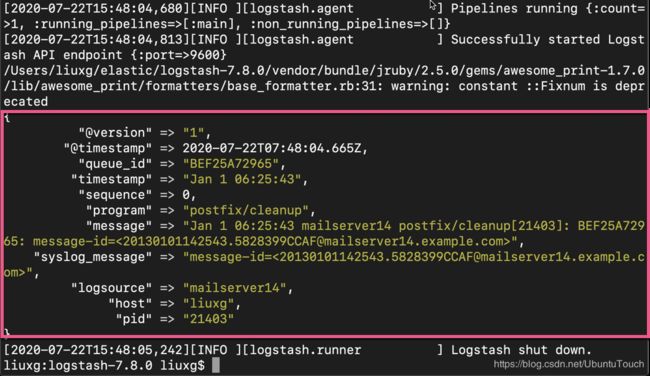
从上面,我们可以看出来 queue_id 的值为 BEF25A72965。
常见的例子
Syslog:
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}Nginx:
grok {
match => [ "message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}"]
overwrite => [ "message" ]
}Apache:
grok {
match => [
"message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}",
"message" , "%{COMMONAPACHELOG}+%{GREEDYDATA:extra_fields}"
]
overwrite => [ "message" ]
}
Mysql:
grok {
match => [ 'message', "(?m)^%{NUMBER:date} *%{NOTSPACE:time} %{GREEDYDATA:message}"
]
overwrite => [ 'message' ]
add_field => { "mysql_time" => "%{date} %{time}" }
}Elasticsearch:
grok {
match => ["message", "\[%{TIMESTAMP_ISO8601:timestamp}\]\[%{DATA:loglevel}%{SPACE}\]\[%{DATA:source}%{SPACE}\]%{SPACE}\[%{DATA:node}\]%{SPACE}\[%{DATA:index}\] %{NOTSPACE} \[%{DATA:updated-type}\]", "message", "\[%{TIMESTAMP_ISO8601:timestamp}\]\[%{DATA:loglevel}%{SPACE}\]\[%{DATA:source}%{SPACE}\]%{SPACE}\[%{DATA:node}\] (\[%{NOTSPACE:Index}\]\[%{NUMBER:shards}\])?%{GREEDYDATA}"]
}定制应用日志:
让我们考虑以下应用程序日志:
2015-04-17 16:32:03.805 ERROR [grok-pattern-demo-app,BDS567TNP,2424PLI34934934KNS67,true] 54345 --- [nio-8080-exec-1] org.qbox.logstash.GrokApplicarion : this is a sample message或
2015-04-17 16:32:03.805 ERROR [grok-pattern-demo-app,BDS567TNP,2424PLI34934934KNS67,true] 54345 --- [nio-8080-exec-1] org.qbox.logstash.GrokApplicarion : this is a sample message我们为上述应用程序日志配置了以下Grok模式:
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} *%{LOGLEVEL:level} \[%{DATA:application},%{DATA:minQId},%{DATA:maxQId},%{DATA:debug}] %{DATA:pid} --- *\[%{DATA:thread}] %{JAVACLASS:class} *: %{GREEDYDATA:log}" }logstash_app.conf
input {
generator {
message => "2015-04-17 16:32:03.805 ERROR [grok-pattern-demo-app,BDS567TNP,2424PLI34934934KNS67,true] 54345 --- [nio-8080-exec-1] org.qbox.logstash.GrokApplicarion : this is a sample message"
count => 1
}
}
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} *%{LOGLEVEL:level} \[%{DATA:application},%{DATA:minQId},%{DATA:maxQId},%{DATA:debug}] %{DATA:pid} --- *\[%{DATA:thread}] %{JAVACLASS:class} *: %{GREEDYDATA:log}" }
}
}
output {
stdout {
codec => rubydebug
}
}
Dissect Filter
Grok 过滤器可以完成工作-但可能会遇到性能问题,尤其是在模式不匹配的情况下。 另一种选择是改为使用基于分隔符的 Dissect 过滤器。 不幸的是,没有针对此的应用程序,但是编写一个基于分隔符的过滤器要比基于正则表达式的过滤器容易得多。 与上述等效的映射为:
%{timestamp} %{+timestamp} %{level}[%{application},%{minQId},%{maxQId},%{debug}]\n
%{pid} %{}[%{thread}] %{class}:%{log}从基于正则表达式的过滤器移至基于分隔符的过滤器时,会有细微的差异。 一些字符串最终会用空格填充。 有两种处理方法:
更改应用程序中的日志记录模式,这可能会使直接日志读取更加困难
- 使用 Logstash 剥离其他空间
- 使用第二个选项,最终的过滤器配置配置为:
filter {
dissect {
mapping => { "message" => ... }
}
mutate {
strip => [ "log", "class" ]
}
}总结
Grok 是一个表达式库,可轻松从日志中提取数据。 您可以从数百种可用的 Grok 模式中进行选择。 Logstash 开箱即用地支持许多内置模式,用于过滤单词,数字和日期之类的项目(请参阅此处支持的模式的完整列表)。 如果找不到所需的模式,则可以编写自己的自定义模式。
Grok 过滤器功能强大,被许多人用来构造数据。 但是,根据要解析的特定日志格式,编写过滤器表达式可能是非常复杂的任务。 基于分隔符的 dissect 过滤器是一种替代方法,它使操作变得更加容易-当然也会增加有一些额外的处理代价。 如果出现性能问题,这也是一种选择。
更多阅读:
【1】Elastic:在 Grok 中运用 custom pattern 来定义 pattern
【2】Logstash:Grok filter 入门
【3】Logstash:Data转换,分析,提取,丰富及核心操作