等待事件之Row Cache Lock
等待事件之Row Cache Lock
| 名称 | P1 | P2 | P3 | 原因 | 处理 |
| row cache lock | 字典的Cache号,其值为V$ROWCACHE.CACHE# | Mode:Mode Held | request:Mode Requested | row cache lock等待事件是一个共享池相关的等待事件,是由于对字典缓冲的访问造成的。每一个行缓冲队列锁都对应一个特定的数据字典对象,这被叫做队列锁类型,并可以在V$ROWCACHE视图中找到。在AWR中需要查看Dictionary Cache Stats部分用以确定问题。常见的原因有如下几点: ① 序列没有设置CACHE属性,导致序列争用 ② 表空间不足引起 表空间的扩展速度跟不上表空间的使用速度会发生该等待事件 ③ Shared Pool不足,需要增加共享池 ④ 用户密码错误或给出了空密码并且频繁登录 |
根据P1值查询V$ROWCACHE视图(SELECT A.PARAMETER FROM V$ROWCACHE A WHERE CACHE# =P1;),进而确定队列类型。若为DC_SEQUENCES则增大序列的CACHE值;若为DC_USERS则可能是当用户密码错误或密码为空时用户频繁登录导致,进而查询审计来确定(SELECT * FROM DBA_AUDIT_TRAIL WHERE RETURNCODE IN (1017, 1005);。1017代表密码错误,1005代表空密码);其它类型很可能是Shared Pool过小导致。 |
运行DDL必须请求一个行缓冲锁(row cache lock)来锁住数据字典(Data Dictionary)信息。共享池(Shared Pool)包含来自数据字典的的行缓冲区,可以减少磁盘的I/O访问,并允许对行进行加锁。数据字典行锁被叫做行缓冲队列锁(Row Cache Enqueue Locks)。这个队列锁结构从共享池中按需求分配,当这些请求在等待并超时就会看到行缓冲队列锁。row cache lock等待事件是一个共享池相关的等待事件,是由于对字典缓冲的访问造成的。每一个行缓冲队列锁都对应一个特定的数据字典对象,这被叫做队列锁类型,并可以在V$ROWCACHE视图中找到。
SELECT * FROM V$EVENT_NAME D WHERE D.NAME = 'row cache lock';
SELECT *
FROM DBA_HIST_ROWCACHE_SUMMARY D
WHERE D.SNAP_ID BETWEEN 1 AND 3014
AND D.GETS > 0;
SELECT * FROM V$ROWCACHE WHERE CACHE# IN ('7', '10');
SELECT A.PARAMETER FROM V$ROWCACHE A WHERE CACHE# =P1;
SELECT * FROM DBA_AUDIT_TRAIL d WHERE /*RETURNCODE IN (1017) AND*/ d.action_name='LOGON' AND D.returncode>0 AND D.returncode<>1017;
[root@rhel6lhr ~]# oerr ora 1005
01005, 00000, "null password given; logon denied"
// *Cause:
// *Action:
[root@rhel6lhr ~]# oerr ora 1017
01017, 00000, "invalid username/password; logon denied"
// *Cause:
// *Action:
[root@rhel6lhr ~]#
在AWR中需要查看Dictionary Cache Stats部分用以确定问题。
常见队列锁类型
行缓冲队列锁等待的调优基于每一个队列锁类型的行为,其中常见的有:
① DC_SEQUENCES:在使用序列的时候将发生该行缓冲队列锁。调优方式是检查序列是否指定了缓冲选项并确定这个缓冲值可以承受预期的并发insert操作。Check for appropriate caching of sequences for the application requirements.
② DC_USED_EXTENTS和DC_FREE_EXTENTS:该行缓冲队列锁可能在空间管理碰到表空间分裂或者没有足够区大小时发生。调优方法是检查表空间是否分裂了、区大小是否太小或者表空间是人工管理。
③ DC_TABLESPACES:该行缓冲队列锁会在分配新区是发生。如果区大小设置得过小,程序将经常申请新区,这将导致冲突。调优方法是快速地增加区的数量。Probably the most likely cause is the allocation of new extents. If extent sizes are set low then the application may constantly be requesting new extents and causing contention. Do you have objects with small extent sizes that are rapidly growing? (You may be able to spot these by looking for objects with large numbers of extents). Check the trace for insert/update activity, check the objects inserted into for number of extents.
④ DC_OBJECTS:该行缓冲队列锁会在重编译对象的时候发生。当对象编译时将申请一个排他锁阻塞其他行为。通过检查非法对象和依赖关系来调优。
⑤ DC_SEGMENTS:该行缓冲队列锁会在段分配的时候发生,观察持有这个队列锁的会话在做什么。This is likely to be down to segment allocation. Identify what the session holding the enqueue is doing and use errorstacks to diagnose.
⑥ DC_USERS:Deadlock and resulting “WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!” can occur if a session issues a GRANT to a user, and that user is in the process of logging on to the database.dc_users是和用户用错误密码登陆有关,In 11g there is an intentional delay between allowing failed logon attempts to retry. For some specific application types this can cause a problem as the row cache entry is locked for the duration of the delay . This can lead to excessive row cache lock waits for DC_USERS for specific users / schemas.
…
After 3 successive failures a sleep delay is introduced starting at 3 seconds and extending to 10 seconds max. During each delay the user X row cache lock is held in exclusive mode preventing any concurrent logon attempt as user X (and preventing any other operation which would need the row cache lock for user X).
⑦ DB_ROLLBACK_SEGMENTS:This is due to rollback segment allocation. Just like dc_segments,identify what is holding the enqueue and also generate errorstacks. Remember that on a multi-node system (RAC) the holder may be on another node and so multiple systemstates from each node will be required.
⑧ DC_AWR_CONTROL:This enqueue is related to control of the Automatic Workload Repository. As such any operation manipulating the repository may hold this so look for processes blocking these.
DC_SEQUENCES
For DC_SEQUENCES, consider caching sequences using the cache option.
DC_OBJECTS
Look for any object compilation activity which might require an exclusive lock, blocking other activities
DC_SEGMENTS
Contention here is most likely to be due to segment allocation. Investigate what segments are being created at the time.
DC_USERS
This may occur if a session issues a GRANT to a user and that user is in the process of logging on to the database. Investigate why grants are being made while the users are active.
DC_TABLESPACES
The most likely cause is the allocation of new extents. If extent sizes are set low then the application may constantly be requesting new extents and causing contention. Do you have objects with small extent sizes that are rapidly growing? (You may be able to spot these by looking for objects with large numbers of extents). Check the trace for insert/update activity, check the objects inserted into for number of extents.
Resolving Issues Where 'Row Cache Lock' Waits are Occurring (文档 ID 1476670.1)
In this Document
| Purpose |
| Troubleshooting Steps |
| Problem Confirmation: |
| Row Cache Lock |
| Reducing Waits |
| Known Issues |
| References |
APPLIES TO:
Oracle Database - Standard Edition - Version 10.2.0.1 and laterOracle Database - Enterprise Edition - Version 10.2.0.1 and later
Oracle Database - Personal Edition - Version 10.2.0.1 and later
Information in this document applies to any platform.
PURPOSE
TROUBLESHOOTING STEPS
Brief Definition:
The shared pool contains a cache of rows from the data dictionary that helps reduce physical I/O on the data dictionary tables. The row cache lock is used primarily to serialize changes to the data dictionary and is waited on when a lock on a data dictionary cache is required. Waits on this event usually indicate some form of DDL occuring, or possibly recursive operations such as storage management and incrementing sequence numbers.
Problem Confirmation:
- Significant wait for latch: row cache objects
- Slow overall performance with row cache lock
- High CPU usage
Row Cache Lock
When DDLs execute, they must acquire locks on the row cache in order to access and change the Data Dictionary information. Once the locks are taken then they can be allowed to modify individual rows in the data dictionary.
Reducing Waits
1. The data dictionary resides in the shared pool. If the shared pool is not sized correctly then the data dictionary might not be fully cached. This should be handled automatically with the automatic shared memory tuning feature. The following documents provide more details:
Document 270935.1 Shared pool sizing
2. Find which cache is being waited for:
SQL> select p1text,p1,p2text,p2,p3text,p3 from v$session where event='row cache lock';
P1TEXT P1 P2TEXT P2 P3TEXT P3
cache id 8 mode 0 request 3
SQL> select parameter,count,gets,getmisses,modifications from v$rowcache where cache#=8;
PARAMETER COUNT GETS GETMISSES MODIFICATIONS
DC_SEQUENCES 869 76843 508432 4500
In this example the cache is the "DC_SEQUENCES" cache.
3. Take cache dependent actions:
DC_SEQUENCES
For DC_SEQUENCES, consider caching sequences using the cache option.
DC_OBJECTS
Look for any object compilation activity which might require an exclusive lock, blocking other activities
DC_SEGMENTS
Contention here is most likely to be due to segment allocation. Investigate what segments are being created at the time.
DC_USERS
This may occur if a session issues a GRANT to a user and that user is in the process of logging on to the database. Investigate why grants are being made while the users are active.
DC_TABLESPACES
The most likely cause is the allocation of new extents. If extent sizes are set low then the application may constantly be requesting new extents and causing contention. Do you have objects with small extent sizes that are rapidly growing? (You may be able to spot these by looking for objects with large numbers of extents). Check the trace for insert/update activity, check the objects inserted into for number of extents.
4. For further information on row cache issues, review the following:
Measuring Success
Once you have applied the changes to resolve the issues you have found, compare the latest AWR to the AWR that led you here via Guided Resolution (that AWR becomes your baseline). Look at the percentage decrease total wait time for this event. If there are still issues, re- evaluate those and address them according to the specific symptom.
Known Issues
Document 2372926.8 "row cache objects" latch contention on DC_USERS row cache
Document 1466896.1 High Waits on 'Row Cache Lock' with Pipelined Functions After Upgrade to 11.2.0.3
Document 13502860.8 Bug 13502860 - "row cache lock" contention on SYS_PLSQL_xx objects using PIPELINED functions
REFERENCES
NOTE:34609.1 - WAITEVENT: "row cache lock" Reference Note
WAITEVENT: "row cache lock" Reference Note (文档 ID 34609.1)
"row cache lock" Reference Note
This is a reference note for the wait event "row cache lock" which includes the following subsections:- Brief definition
- Individual wait details (eg: For waits seen in V$SESSION_WAIT)
- Systemwide wait details (eg: For waits seen in V$SYSTEM_EVENT)
- Reducing waits / wait times
- Troubleshooting
- Known Bugs
Definition:
Versions: 7.3 - 12.1Documentation: 12.1 11.2 11.1 10.2 10.1
This event is used to wait for a lock on a data dictionary cache specified by "cache id" (P1).
If running Real Application Clusters (RAC) then LCK0 is signalled to get the row cache lock for the foreground waiting on this event. The LCK0 process will get the lock asynchronously. In exclusive mode the foreground process will try to get the lock.
Individual Waits:
Parameters:
P1 = cache - ID of the dictionary cache P2 = mode - Mode held P3 = request - Mode requested- cache - ID of the dictionary cache
Row cache lock we are waiting for. Note that the actual CACHE# values differ between Oracle versions. The cache can be found using this select - "PARAMETER" is the cache name:
SELECT cache#, type, parameter FROM v$rowcache WHERE cache# = &P1 ;
In a RAC environment the row cache locks use global enqueues of type "Q[A-Z]" with the lock id being the hashed object name.
- mode - Mode held
The mode the lock is currently held in:
KQRMNULL 0 null mode - not locked KQRMS 3 share mode KQRMX 5 exclusive mode KQRMFAIL 10 fail to acquire instance lock
- request - Mode requested
The mode the lock is requested in:
KQRMNULL 0 null mode - not locked KQRMS 3 share mode KQRMX 5 exclusive mode KQRMFAIL 10 fail to acquire instance lock
Wait Time:
In exclusive mode any process other than PMON will timeout after 8 hours (10000 waits of 3 seconds)In RAC the foreground will wait 60 seconds for the LCK0 to get the lock, the foreground will wait in infinite loop until the lock has been granted (LCK0 will notify foreground).
In either case PMON will wait for only 5 seconds.
If a session times out when waiting for a row cache lock then it will report this to the alert log and tracefile with a message like:
WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK
Finding Blockers:
Holders and requesters can be seen in view X$KQRFP for parent objects, and X$KQRFS for subordinates.
eg: The following select will show all holders of parent row cache objects so can be used to help find the blocking session.(KQRFPSES is the address of the holding session V$SESSION.SADDR)SELECT * FROM x$kqrfp WHERE kqrfpmod!=0;
Systemwide Waits:
It is important to determine which cache is being waited for. The V$ROWCACHE view gives an overview of which caches are being used most, but the waits may not necessarily be on the most used cache. The V$ACTIVE_SESSION_HISTORY view can be used to get an idea of which cache ids (P1) are involved in waits. If the issue is general across various caches (different cache ids) then the shared pool may need increasing in size to allow more dictionary information to be cached If the issue is focused on a specific cache id then options typically depend on the cache involved - see the Troubleshootingsection below.
Reducing Waits / Wait times:
Options to reduce waits depends on the specific cache that has the contention. See the documents in the Troubleshooting section below for advice on various caches.
Troubleshooting
See the following documents for help troubleshooting issues relating to "row cache lock" waitsDocument:1476670.1 Resolving Issues Where 'Row Cache Lock' Waits are Occurring
Document:278316.1 Troubleshooting "WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!"
Known Issues / Bugs:
You can restrict the list below to issues likely to affect one of the following versions by clicking the relevant button:
'*' indicates that an alert exists for that issue. '+' indicates a particularly notable issue / bug. See Note:1944526.1 for details of other symbols used
NB Prob Bug Fixed Description - 17828499 12.1.0.1.4, 12.1.0.2, 12.2.0.1 Opening PDB hangs waiting for row cache lock on open UPGRADE - 16921340 12.1.0.1.1, 12.1.0.2, 12.2.0.1 Non-CDB to PDB plugin hangs II 13884774 12.1.0.2, 12.2.0.1 Deadlock from concurrent select/ALTER SUMMARY and ALTER TABLE if query_rewrite_enabled set to true/force - superseded II 16994952 12.1.0.1 Unable to unschedule propagation due to CJQ self-deadlock / hang II 14117976 11.2.0.3.BP14, 11.2.0.4, 12.1.0.1 Database hangs when executing multiple MV DDL's in parallel III 13496395 11.2.0.4, 12.1.0.1 Hang / deadlock involving ACCOUNT_STATUS object for concurrent LOGON and ALTER USER III 7715339 11.2.0.1 Logon failures causes "row cache lock" waits - Allow disable of logon delay III 21153142 12.2.0.1 Row cache lock self deadlock accessing seed PDB II 21091431 12.1.0.2.160419, 12.1.0.2.DBBP13, 12.2.0.1 row cache lock during trigger creation using editions II 19907473 12.2.0.1 GEN0 process causing database hang III 15850031 11.2.0.4, 12.1.0.2, 12.2.0.1 Rare instance hang: deadlock between 'row cache lock' and 'cursor: pin S wait for X' II 13622515 11.2.0.4, 12.1.0.2, 12.2.0.1 library cache <-> row cache deadlock / hang when altering constraint with MV involved - superseded II 13869467 12.1.0.2 Many waits for 'row cache lock' in RAC while creating many tables with constraints II 13979519 11.2.0.3.BP11, 11.2.0.4, 12.1.0.1 Locks on dc_users kept too long II 13916228 11.2.0.4, 12.1.0.1 Enabling/disabling constraints makes DML timeout in RAC - superseded II 13502860 11.2.0.4, 12.1.0.1 "row cache lock" contention on SYS_PLSQL_xx objects using PIPELINED functions - 13387978 11.2.0.4, 12.1.0.1 Sessions running TRUNCATE causing a deadlock, even if the constraints are disabled - 12953743 11.2.0.3.BP13, 11.2.0.4, 12.1.0.1 Parallel CTAS of table with a Securefile is slower than parallel IAS / PIDL I 12889054 11.2.0.2.BP16, 11.2.0.3.BP05, 11.2.0.4, 12.1.0.1 AWR snapshot hangs on dc_objects row_cache_lock held by ctas job D - 12792862 11.2.0.4, 12.1.0.1 Performance of INSERT using binary xml is very slow due to "row cache lock" in RAC environment - superseded II 12351027 11.2.0.4, 12.1.0.1 Redefinition causing deadlock between "row cache lock" and "library cache lock" II 11693365 11.2.0.3, 12.1.0.1 Concurrent Drop table and Select on Reference constraint table hangs (deadlock) I 10382754 11.2.0.2.BP17, 11.2.0.3, 12.1.0.1 Poor performance/ rowcache contention in 11g with partitioning due to invalidation of objects IIII 10204505 11.2.0.3, 12.1.0.1 SGA autotune can cause row cache misses, library cache reloads and parsing II 10126219 11.2.0.1.BP08, 11.2.0.2.BP02, 11.2.0.3, 12.1.0.1 Undetected deadlock 'library cache lock'/'row cache lock' with concurrent DDLs on partition tables. II 9952554 11.2.0.2.8, 11.2.0.2.BP18, 11.2.0.3, 12.1.0.1 Undetected deadlock 'library cache lock'/'row cache lock' with a session modifying a constraint II 9866045 11.2.0.3, 12.1.0.1 Long wait on 'wait for master scn' in LCK causing long row cache lock waits III 9776608 11.2.0.2, 12.1.0.1 Hang from concurrent login to same account with a wrong password II 9278979 11.2.0.2, 12.1.0.1 Instance hang / ORA-4021 with OPTIMIZER_USE_PENDING_STATISTICS = true I 8268775 11.1.0.7.4, 11.2.0.1.2, 11.2.0.1.BP07, 11.2.0.2, 12.1.0.1 High US enqueue contention during a login storm or session failover - 8364676 11.1.0.7.2, 11.2.0.1 row cache lock waits from background space preallocation III 7529174 10.2.0.5, 11.1.0.7.3, 11.2.0.1 Deadlock / hang between SMON and foreground process - 7416901 11.1.0.7.1, 11.2.0.1 Deadlock between QC and PQ slaves when CELL_PARTITION_LARGE_EXTENTS = ALWAYS II 7313166 10.2.0.5, 11.2.0.1 Startup hang with self deadlock on dc_rollback_segments II 6870994 10.2.0.5, 11.1.0.7.3, 11.2.0.1 High US enqueue / rowcache lock while trying to online a NEW undo segment III 6027068 10.2.0.5, 11.2.0.1 Contention on ORA_TQ_BASE$ sequence - 5756769 10.2.0.4.1, 10.2.0.5, 11.1.0.7, 11.2.0.1 Deadlock between Create MVIEW and DML III 6143420 10.2.0.5, 11.1.0.6 Deadlock involving "ROW CACHE LOCK" on dc_users AND "CURSOR: PIN S WAIT ON X" III 6004916 10.2.0.5, 11.1.0.6 Hang involving row cache enqueues in RAC (ORA-4021) II 5883112 10.2.0.4, 11.1.0.6 False deadlock in RAC II 5138741 10.2.0.4, 11.1.0.6 High waits on 'row cache lock' when using materialized views on RAC II 4604972 11.1.0.6 Deadlock on dc_users by Concurrent Grant/Revoke - 4579381 10.1.0.5, 10.2.0.2, 11.1.0.6 Deadlock on DC_USERS in RAC (ORA-4020) - 4446011 9.2.0.8, 10.1.0.5, 10.2.0.2, 11.1.0.6 Hang with row cache lock deadlock from concurrent ALTER USER / TRUNCATE II 4390868 10.1.0.5, 10.2.0.3, 11.1.0.6 Contention on DC_SEGMENTS due to small cache size on SYS.AUDSES$ - 4313246 9.2.0.8, 10.1.0.5, 10.2.0.2, 11.1.0.6 PLSQL execution can hold dc_users row cache lock leading to hang / deadlocks I 4153150 9.2.0.8, 10.2.0.2, 11.1.0.6 Deadlock on dc_rollback_segments from concurrent parallel load and undo segment creation I 6051177 10.2.0.4.1, 10.2.0.5 Hang / deadlock between coalesce and DBMS_STATS.gather_table_stats - 5983020 10.2.0.4 MMON deadlock with user session executing ALTER USER - 4275733 9.2.0.8, 10.1.0.5, 10.2.0.1 Deadlock between library cache lock and row cache lock from concurrent rename partition I 5641198 10.2.0.1 Some waits may be longer than needed ("row cache lock") in RAC - 4137000 10.1.0.5, 10.2.0.1 Concurrent SPLIT PARTITION can deadlock / hang - 3627263 9.2.0.6, 10.1.0.4, 10.2.0.1 Deadlock / hang during RAC instance startup II 3424721 9.2.0.6, 10.1.0.3, 10.2.0.1 Hang/deadlock from ALTER INDEX REBUILD on partition with concurrent SQL - 2615271 9.2.0.6, 10.1.0.2 Deadlock from concurrent GRANT and logon
Related:
Document:1628089.1 AWR Report Interpretation Checklist for Diagnosing Database Performance Issues
Document:1359094.1 How to Use AWR Reports to Diagnose Database Performance Issues
Document:1274511.1 General SQL_TRACE / 10046 trace Gathering Examples
Troubleshooting: "WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! " (文档 ID 278316.1)
故障排除:"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! " (文档 ID 2016422.1)
文档内容
| 用途 |
| 排错步骤 |
| 什么是 row cache enqueue 锁(Row Cache Enqueue Lock)? |
| "WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 警告信息是什么意思? |
| "WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 可能的原因 |
| SGA收缩(shrink)/调整大小的操作(resize) |
| row cache enqueue 类型 |
| DC_TABLESPACES |
| DC_SEQUENCES |
| DC_USERS |
| DC_OBJECT_IDS |
| DC_SEGMENTS |
| DC_ROLLBACK_SEGMENTS |
| DC_TABLE_SCNS |
| DC_AWR_CONTROL |
| 我可以收集哪些信息,以确定原因? |
| Systemstate dump |
| AWR,ADDM 和 ASH 报告 |
| 如何分析收集到的诊断信息? |
| Systemstate dump |
| 示例1: |
| 示例2: |
| AWR 报告 |
| 10g 以前的版本可能存在的问题 |
| 其他问题疑难解答 |
| 参考 |
适用于:
Oracle Database - Personal Edition - 版本 8.0.6.0 和更高版本Oracle Database - Enterprise Edition - 版本 8.0.6.0 和更高版本
Oracle Database - Standard Edition - 版本 8.0.6.0 和更高版本
本文档所含信息适用于所有平台
用途
本文档的目的是帮助排查原因"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! "
排错步骤
什么是 row cache enqueue 锁(Row Cache Enqueue Lock)?
行缓存(Row Cache)或数据字典缓存(Data Dictionary Cache)是保存数据字典信息的共享池的内存区域。row cache 保存数据时并不是以数据块的形式,而是以行的形式。row cache enqueue 锁是在数据字典行的锁。此 enqueue 是关于特定数据字典对象的。这就是所谓的 enqueue 类型,可以在视图 V$rowcache 中找到。
对于每个版本 row cache 类型的列表,请参阅:
"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 警告信息是什么意思?
当我们试图获得 row cache 锁,这种等待事件将被使用。
当 row cache 冲突发生时,如果不能在一个预定的时间周期内得到 enqueue,将在 USER_DUMP_DEST 或 background_dump_dest 目录下生成一个跟踪文件,这取决于是用户还是后台进程创建的跟踪文件。alert.log 通常会相应的更新警告消息和跟踪文件的位置。
数据库检测到核心资源被持有太久并通知管理员,从而让这种情况可以得到解决。这也可能伴随着数据库挂起或变慢。
alert.log 的消息和生成的跟踪文件趋向于包含消息:
如果不能立即获取 rowcache entry 锁,那么进入一个循环,先释放 row cache 对象闩锁,等待(等待上述等待事件),重新获得闩锁,然后再次尝试获取 rowcache 锁。在单实例模式,会重复 1000次直到进程报错“WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK”。在 RAC 环境会一直重复,直到不能获得实例锁或者被中断。
Systemstate dump 可以提供一些有用的信息诊断争用的原因。
"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 可能的原因
SGA收缩(shrink)/调整大小的操作(resize)
如果 SGA 动态地改变大小,需要持有各种 latches 来避免其它进程同时操作,直到操作完成。如果调整大小需要一段时间,或者是经常发生,你会看到"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!"的发生。定位这种情况的方法是,有很多'SGA: allocation forcing component growth'等待事件,或 AWR 的 TOP 列表有类似等待,以及阻塞等待"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 的会话在等待'SGA: allocation forcing component growth'(或类似)。有一些可用的代码修复,请参阅:
Document 9267837.8 Bug 9267837 - Auto-SGA policy may see larger resizes than needed
row cache enqueue 类型
对于每一个 enqueue 类型,都有对应的一些操作会需要获取这类 enqueue。队列的类型,可能给出由于操作可能导致的问题的指示。一些常见的原因如下:
DC_TABLESPACES最可能的原因是新 extent 的分配。如果 extent 大小设置过小,那么应用程序可能会不断地要求新的 extent,这可能导致争用。你有很小的 extent 尺寸,正在迅速增长的对象吗?(通过查找具有大量 extents 的对象可以定位它们)。检查 insert/update 活动的 trace,查找那些就有很多 extents 的对象。
DC_SEQUENCES检查应用程序用到的 sequence 的 cache 的大小:
Document 395314.1 RAC Hangs due to small cache size on SYS.AUDSES$ - fixed in 10.2.0.3
Document 6027068.8 Bug 6027068 - Contention on ORA_TQ_BASE sequence -fixed in 10.2.0.5 and 11.2.0.1
一个会话正在对一个用户执行 GRANT,与此同时此用户正在登录到数据库中,此时可能会发生死锁或导致"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 。
Document 6143420.8 Bug 6143420 - Deadlock involving "ROW CACHE LOCK" on dc_users AND "CURSOR: PIN S WAIT ON X"- fixed in 10.2.0.5 and 11.1.0.6 DC_OBJECTS
Document 12772404.8 Bug 12772404 - Significant "row cache objects" latch contention when using VPD
这很可能是 segment 的分配导致的。确定持有锁的用户正在做什么并使用 errorstacks 进行诊断。
DC_ROLLBACK_SEGMENTS这可能是由于 rollback 段的分配导致的。正如 dc_segments,确定谁持有锁并收集 errorstack 来进行诊断。请记住,在多节点系统(RAC)上,持有者可能在另一节点上,因此需要所有节点的 systemstate。
DC_TABLE_SCNS 此 enqueue 关系到 AWR(Automatic Workload Repository)的控制权。任何操纵 AWR 资料库的操作将持有它. 要分析这个问题,需要查找是那些进程阻塞了它们。
RAC 相关的 Bugs
Document 8666117.8 Bug 8666117 - High row cache latch contention in RAC - fixed in 11.2.0.2 and 12.1
Document 9866045.8 Bug 9866045 - Long wait on 'wait for master scn' in LCK causing long row cache lock waits - fixed in 12.1
我可以收集哪些信息,以确定原因?
Systemstate dump
当问题发生时,错误会记入 alert.log,并自动产生一个 systemstate dump 文件。
> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! pid=37
System State dumped to trace file /oracle/diag/rdbms/..../.trc
AWR,ADDM 和 ASH 报告
收集两份 AWR 报告,一份有问题时间段的,另一个是没有问题时间段的,因为这些可以帮助我们理解问题发生时数据库的状况 AWR,ADDM,ASH 报告,可以相互取长补短,从而更完整地理解整个问题。
取决于 AWR 快照生成的时间间隔,收集最小时间间隔的报告。默认的快照是一个小时的时间间隔。
SQL>@$ORACLE_HOME/rdbms/admin/addmrpt.sql
SQL>@$ORACLE_HOME/rdbms/admin/ashrpt.sql
鉴于分析 systemstate 是一件很复杂的事情,您可以创建一个服务请求,并上传 alert.log,systemstate dump,以及问题发生前和问题发生时的 AWR 报告请 Oracle 技术支持来分析。
如何分析收集到的诊断信息?
Systemstate dump
通常情况下, row cache enqueue 是一系列事件的一部分,阻塞了申请 row cache enqueue 的进程的进程很可能被另一个进程阻塞。Row cache enqueue 经常是问题的表象。
Systemstate dump 可以帮助查找申请的是哪一个 row cache ,并可能有助于发现阻塞进程。
Unix process pid: 10846, image: oracle@cpdb4532
*** 2011-05-13 08:08:58.775
*** SERVICE NAME:(ALFCMR_SERVICE) 2011-05-13 08:08:58.775
*** SESSION ID:(1076.796) 2011-05-13 08:08:58.775
> WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK! <<<
row cache enqueue: session: 0x1df57ade8, mode: N, request: S
trace 的标题显示下列内容:
- 等待 row cache enqueue 锁的 Oracle 进程号(PID)(在这个案例,进程 77)。
- 正在申请的 row cache enqueue 的模式(请求:S)。
因此,在上述例子中,进程 77 是在请求以共享模式获得 row cache(请求:S)。
Systemstate 包含数据库中每一个进程的状态信息,因此可以在 systemstate 中查找这个进程:
----------------------------------------
.
.
----------------------------------------
SO: 0x1cdf11958, type: 50, owner: 0x17d198288, flag: INIT/-/-/0x00
row cache enqueue: count=1 session=0x1df57ade8 object=0x1dc9a5d30, request=S
savepoint=0x87b70d
row cache parent object: address=0x1dc9a5d30 cid=7(dc_users)
.
.
从上面我们看到,进程 77 请求共享模式获得 row cache dc_users。
进程 77 处于等待状态,意味着被其它进程阻塞,我们现在需要检查 systemstate 判断谁持有资源并阻塞了这个进程。
搜索引用的对象,在这个例子中,是 object=0x1dc9a5d30。
这样做完以后,我们发现,进程 218 正以独占模式持有这个对象:
----------------------------------------
.
.
SO: 0x1cdf118f8, type: 50, owner: 0x1ceb0f178, flag: INIT/-/-/0x00
row cache enqueue: count=1 session=0x1da54cf68 object=0x1dc9a5d30, request=X
savepoint=0x11e
row cache parent object: address=0x1dc9a5d30 cid=7(dc_users)
独占模式的请求,将会一直阻塞共享模式的请求,直到该进程独占模式的请求被满足并稍后释放了这个资源。因此,这将阻止其他共享模式请求。请注意,这是请求独占而不是独占持有,所以这个请求也一定被阻塞了。查看其他进程中,我们看到进程 164 在以共享模式(mode=s)持有这个对象。
----------------------------------------
.
.
O/S info: user: u1m, term: , ospid: 1234, machine: cpc44711
program:
last wait for 'SQL*Net message from client' blocking sess=0x(nil) seq=36289 wait_time=6943 seconds since wait started=2539
driver id=54435000, #bytes=1, =0
.
.
SO: 0x1cdf11418, type: 50, owner: 0x1ccc26120, flag: INIT/-/-/0x00
row cache enqueue: count=2 session=0x1df578318 object=0x1dc9a5d30, mode=S
savepoint=0xb1bd8e
row cache parent object: address=0x1dc9a5d30 cid=7(dc_users)
hash=fc968070 typ=11 transaction=(nil) flags=00000002
own=0x1dc9a5e00[0x1cdf11448,0x1cdf11448] wat=0x1dc9a5e10[0x1cdf11928,0x17d5192e0] mode=S
因此,进程 164 以共享模式持有 row cache enqueue(mode= S),从而防止了进程 218 以独占模式获得该 row cache enqueue。此外,我们看到,进程 164 在 ON CPU(systemstate 显示最后一个等待是'SQL*Net message from client',而不是等待'SQL*Net message from client')。为了进一步诊断,技术支持需要检查堆栈调用,以确定为什么这个进程在 ON CPU 并持有该队列这么久(从开始已经等待了2539秒)。
在这个例子中,进程 18(MMON)等待以共享模式获得类型为 dc_awr_control 的 row cache。
With the Partitioning, Oracle Label Security, OLAP, Data Mining
and Real Application Testing options
ORACLE_HOME = /opt/oracle10/product/10.2.0
System name: SunOS
Node name: saecopt51
Release: 5.10
Version: Generic_144488-04
Machine: sun4v
Instance name: PORT_V16
Redo thread mounted by this instance: 1
Oracle process number: 18
Unix process pid: 6196, image: oracle@sae (MMON)
.
.
PROCESS 18:
----------------------------------------
.
.
last wait for 'ksdxexeotherwait' wait_time=0.000013 sec, seconds since wait started=6
.
.
SO: 39bf1f0e8, type: 50, owner: 3980783a0, flag: INIT/-/-/0x00
row cache enqueue: count=1 session=3be37ea80 object=39a79f090, request=S
savepoint=0x41f0ae
row cache parent object: address=39a79f090 cid=22(dc_awr_control)
hash=6f60197e typ=9 transaction=3bc39f560 flags=0000002a
own=39a79f160[39bf1f178,39bf1f178] wat=39a79f170[39bf1f118,39bf1f118] mode=X
.
.
对象(object=39a79f090)的 row cache lock 被进程 269 以独占模式(mode=x)持有。进程在等待'SGA: allocation forcing component growth'。
----------------------------------------
.
.
waiting for 'SGA: allocation forcing component growth' wait_time=0, seconds since wait started=3
.
.
SO: 39bf1f148, type: 50, owner: 3bc39f560, flag: INIT/-/-/0x00
row cache enqueue: count=1 session=3be1b7c98 object=39a79f090, mode=X
savepoint=0x41efe8
row cache parent object: address=39a79f090 cid=22(dc_awr_control)
hash=6f60197e typ=9 transaction=3bc39f560 flags=0000002a
own=39a79f160[39bf1f178,39bf1f178] wat=39a79f170[39bf1f118,39bf1f118] mode=X
.
.
因此根本原因就是 SGA 的大小调整,等待 row cache 是次要结果。
我们使用该期间的 AWR 报告看相关信息:
AWR 报告
Top 5 Timed Events Avg %Total
~~~~~~~~~~~~~~~~~~ wait Call
Event Waits Time (s) (ms) Time Wait Class
------------------------------ ------------ ----------- ------ ------ ----------
SGA: allocation forcing compon 42,067,317 38,469 1 7.6 Other
CPU time 2,796 0.6
db file sequential read 132,906 929 7 0.2 User I/O
latch free 4,282,858 704 0 0.1 Other
log file switch (checkpoint in 904 560 620 0.1 Configurat
-------------------------------------------------------------
我们可以清楚地看到,在 Top 5 等待事件中,整个系统中有针对此事件的一个显著等待;并且'SGA: allocation forcing component growth' 是这一时间点的一个主要问题。"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!" 消息的根本原因就是内存调整活动,TOP 5 的等待事件甚至不显示等待“row cache"症状。
如果调整内存大小没有那么严重,有些时候没有"WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!"消息。 - 主要是因为没有达到在此之前提到的阈值。但是,您可能会看到其他等待事件。在以下文献中概述了一个常见的例子:
Document 742599.1 High 'cursor: pin S wait on X' and/or 'library cache lock' Waits Generated by Frequent Shared Pool/Buffer Cache Resize Activity
对于频繁的内存调整,有几个潜在的可用修复,请参阅:
Document 9267837.8 Bug 9267837 - Auto-SGA policy may see larger resizes than needed
10g 以前的版本可能存在的问题
10g 之前的版本,检测 row cache 级别死锁的方法有限。为了尽量减少发生死锁的可能性,可能的解决方法:
- 设置 TIMED_STATISTICS=FALSE
- 设置 _row_cache_cursors=20 以上(默认值 10)
- 不要做任何 tracing
其他问题疑难解答
对于其他性能问题的故障排除,请参阅:
Bug 12772404 - Significant "row cache objects" latch contention when using VPD (Doc ID 12772404.8)
参考
BUG:11693365 - GETTING ERROR 'WAITED TOOL LONG FOR ROW CACHE ENQUEUE LOCK'BUG:5756769 - ROW CACHE DEADLOCK "WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!"
NOTE:11693365.8 - Bug 11693365 - Concurrent Drop table and Select on Reference constraint table hangs (deadlock)
NOTE:1377446.1 - * Troubleshooting Performance Issues
NOTE:30802.1 - Init.ora Parameter "ROW_CACHE_CURSORS" Reference Note
NOTE:395314.1 - RAC Hangs due to small cache size on SYS.AUDSES$
NOTE:4604972.8 - Bug 4604972 - Deadlock on dc_users by Concurrent Grant/Revoke
NOTE:468334.1 - How to Match a Row Cache Object Child Latch to its Row Cache
NOTE:5756769.8 - Bug 5756769 - Deadlock between Create MVIEW and DML
NOTE:6004916.8 - Bug 6004916 - Hang involving row cache enqueues in RAC (ORA-4021)
NOTE:6027068.8 - Bug 6027068 - Contention on ORA_TQ_BASE$ sequence
NOTE:6143420.8 - Bug 6143420 - Deadlock involving "ROW CACHE LOCK" on dc_users AND "CURSOR: PIN S WAIT ON X"
NOTE:742599.1 - High 'Cursor: Pin S Wait On X', 'Library Cache Lock' And "Latch: Shared Pool" Waits due to Shared Pool/Buffer Cache Resize Activity
NOTE:853652.1 - RAC and Sequences
NOTE:8666117.8 - Bug 8666117 - High row cache latch contention in RAC
NOTE:9866045.8 - Bug 9866045 - Long wait on 'wait for master scn' in LCK causing long row cache lock waits
BUG:8666117 - LCK0 PROCESS STUCK AT WAITING FOR "LATCH: ROW CACHE OBJECTS"
一次awr报告分析(密码错误引发sql执行时间过长)
预备知识:
1)row cache lock事件
--内存share pool分为library cache,dictionary cache;而row cache lock对象分布在dictionary cache中,是由于对于字典缓冲的访问造成的;
--这类属于latch类的资源竞争,相当耗CPU,如果并发量大的话,容易down机
如果发现这个等待十分高,一般来说可能由于2种原因,一是共享池太小了,需要增加共享池,另外一种情况是SQL分析过于频繁,对于共享池的并发访问量过大。对于任何一种情况,绝大多数情况下加大共享池会有助于降低该等待,不过加大共享池的时候也要注意,并不一定所有的情况下增加共享池都会有明显的效果。特别是对于第二种情况,精确的分析十分重要。另外进一步分析,弄清楚哪些ROW CACHE的等待最为严重,有助于解决问题。
row cache lock事件的调优基于每一个队列锁类型的行为,常见的 队列锁类型 有:
-------DC_SEQUENCES:在使用序列的时候将发生该行缓冲队列锁。调优方式是检查序列是否指定了缓冲选项并确定这个缓冲值可以承受预期的并发insert操作。
Check for appropriate caching of sequences for the application requirements.
-------DC_USED_EXTENTS和DC_FREE_EXTENTS:该行缓冲队列锁可能在空间管理碰到表空间分裂或者没有足够区大小时发生。调优方法是检查表空间是否分裂了、区大小是否太小或者表空间是人工管理。
-------DC_TABLESPACES:该行缓冲队列锁会在分配新区是发生。如果区大小设置得过小,程序将经常申请新区,这将导致冲突。调优方法是快速地增加区的数量。
Probably the most likely cause is the allocation of new extents. If extent sizes are set low then the application may constantly be requesting new extents and causing contention. Do you have objects with small extent sizes that are rapidly growing? (You may be able to spot these by looking for objects with large numbers of extents). Check the trace for insert/update activity, check the objects inserted into for number of extents.
-------DC_OBJECTS:该行缓冲队列锁会在重编译对象的时候发生。当对象编译时将申请一个排他锁阻塞其他行为。通过检查非法对象和依赖关系来调优。
-------DC_SEGMENTS:该行缓冲队列锁会在段分配的时候发生,观察持有这个队列锁的会话在做什么。
This is likely to be down to segment allocation. Identify what the session holding the enqueue is doing and use errorstacks to diagnose.
-------DC_USERS:Deadlock and resulting “WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!” can occur if a session issues a GRANT to a user, and that user is in the process of logging on to the database.
-------DB_ROLLBACK_SEGMENTS:This is due to rollback segment allocation. Just like dc_segments,identify what is holding the enqueue and also generate errorstacks. Remember that on a multi-node system (RAC) the holder may be on another node and so multiple systemstates from each node will be required.
-------DC_AWR_CONTROL:This enqueue is related to control of the Automatic Workload Repository. As such any operation manipulating the repository may hold this so look for processes blocking these.
2)相关视图字段说明:
ROW CACHE LOCK基础说明
P1 – Cache Id
P2 – Mode Held
P3 – Mode Requested
mode 和REQUEST的取值:
KQRMNULL 0 null mode – not locked
KQRMS 3 share mode
KQRMX 5 exclusive mode
KQRMFAIL 10 fail to acquire instance lock
3)SQL查询
-----查询row cache lock等待
select * from v$session_wait where wait_class = 'row cache lock';
查出p1的值
-----查询rowcache 名称
根据p1的值来查询
select * from v$rowcache where cache# = &p1;
其他:
select event,p1 from v$session a where a.username is not null and a.status='ACTIVE';
4) dba_hist_active_sess_history视图
dba_hist_active_sess_history视图记录了内存中活动会话的历史信息,而动态性能视图V$ACTIVE_SESSION_HISTORY则记录了当前活动会话信息。 通过dba_hist_active_sess_history视图关联v$sqlarea和DBA_HIST_SNAPSHOT可以跟踪到某个时间段内的sql。当然能跟踪到的sql多少取决于v$sqlarea,毕竟只有还保留在v$sqlarea中的sql才能跟踪到。
AWR报告分析
数据库出现状况是8月30号下午3点到4点,于是拉取了两份AWR报告,一份是8月30号下午3点到4点,另一份是31号下午3点到4点,将两份报告比对着看,不同的地方应该就是有问题的地方。
1)发现top 5的前台事件中,排第一的不是DB CPU。默认正常情况下,DB CPU会排第一。
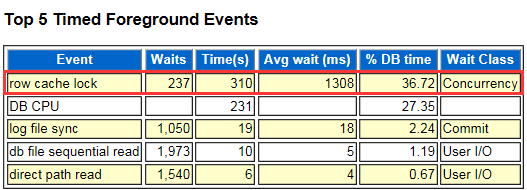
2)继续看 Wait Events Statistics ,发现排第一也不是DB CPU,而是connection management call elapsed time,看名字感觉和数据库连接有关。

3)继续比对,发现dc_users的Pct Miss比较大,超过了20%
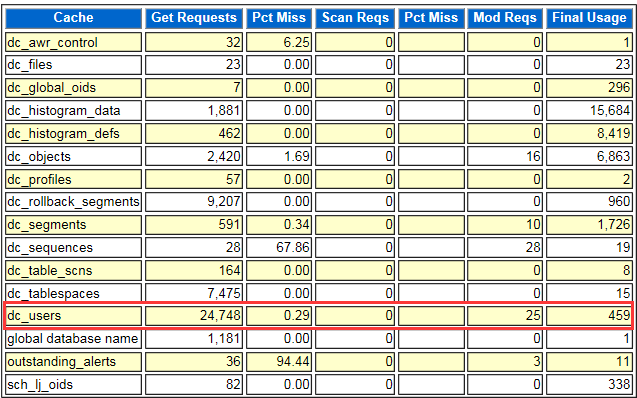
4)查看可疑的sql语句:

标红的sql执行速度很慢,有些异常。
SQL> select to_char(sample_time, 'YY-MM-DD HH24:MI:SS') sample_time,
2 instance_number,
3 sql_id,
4 P1,
5 event,
6 wait_class
7 from dba_hist_active_sess_history
8 where sample_time between
9 to_date('16-08-29 13:00:00', 'YY-MM-DD HH24:MI:SS') and
10 to_date('16-08-29 13:30:00', 'YY-MM-DD HH24:MI:SS')
11 and sql_id in ('bvtu633rnwrwv',
12 '4a6uhr508t0p6',
13 'fpm2zazkfqhy6',
14 'bhrcaykh5tzsw',
15 '9fxv1px768bd5')
16 order by 1
17 ;
SAMPLE_TIME INSTANCE_NUMBER SQL_ID P1 EVENT WAIT_CLASS
----------------- --------------- ------------- ---------- --------------------- ---------------------
16-08-29 13:00:59 1 4a6uhr508t0p6 10 row cache lock Concurrency
16-08-29 13:01:09 1 4a6uhr508t0p6 10 row cache lock Concurrency
16-08-29 13:01:19 1 4a6uhr508t0p6 10 row cache lock Concurrency
16-08-29 13:01:29 1 4a6uhr508t0p6 7 row cache lock Concurrency
16-08-29 13:01:39 1 bvtu633rnwrwv 10 row cache lock Concurrency
16-08-29 13:01:49 1 bvtu633rnwrwv 10 row cache lock Concurrency
16-08-29 13:01:59 1 bvtu633rnwrwv 10 row cache lock Concurrency
16-08-29 13:02:10 1 bvtu633rnwrwv 7 row cache lock Concurrency
16-08-29 13:02:20 1 fpm2zazkfqhy6 10 row cache lock Concurrency
16-08-29 13:02:30 1 fpm2zazkfqhy6 10 row cache lock Concurrency
16-08-29 13:02:40 1 fpm2zazkfqhy6 10 row cache lock Concurrency
16-08-29 13:02:41 2 bvtu633rnwrwv 7 row cache lock Concurrency
16-08-29 13:02:50 1 fpm2zazkfqhy6 7 row cache lock Concurrency
16-08-29 13:04:31 1 bhrcaykh5tzsw 10 row cache lock Concurrency
16-08-29 13:04:41 1 bhrcaykh5tzsw 10 row cache lock Concurrency
16-08-29 13:04:51 1 bhrcaykh5tzsw 7 row cache lock Concurrency
16-08-29 13:06:32 1 9fxv1px768bd5 10 row cache lock Concurrency
16-08-29 13:06:42 1 9fxv1px768bd5 10 row cache lock Concurrency
18 rows selected
根据上面的sql,发现sql导致的等待事件是row cache lock。再根据P1=7或者10,查出等待事件是发生在具体哪个类别上
SQL> select cache#,parameter from v$rowcache where cache# in ('7','10');
CACHE# PARAMETER
---------- --------------------------------
10 dc_users
7 dc_users
7 dc_users
7 dc_users
根据上面的sql,发现参数类别是dc_users,网上说dc_users是和用户用错误密码登陆有关:
In 11g there is an intentional delay between allowing failed logon attempts to retry. For some specific application types this can cause a problem as the row cache entry is locked for the duration of the delay . This can lead to excessive row cache lock waits for DC_USERS for specific users / schemas.
…
After 3 successive failures a sleep delay is introduced starting at 3 seconds and extending to 10 seconds max. During each delay the user X row cache lock is held in exclusive mode preventing any concurrent logon attempt as user X (and preventing any other operation which would need the row cache lock for user X).
验证一下,看是否在发生row cache lock期间,有用户登陆失败。
SQL> select username,
2 userhost,
3 to_char(timestamp, 'YY-MM-DD HH24:MI:SS') timestamp,
4 action_name
5 from dba_audit_trail
6 where action_name = 'LOGON'
7 and priv_used is null
8 and timestamp between
9 to_date('16-08-29 13:00:00', 'YY-MM-DD HH24:MI:SS') and
10 to_date('16-08-29 13:30:00', 'YY-MM-DD HH24:MI:SS');
USERNAME USERHOST TIMESTAMP ACTION_NAME
------------------------------ --------------------- ----------------- ----------------------------
MAPP_PLATFORM IDC-APP-02 16-08-29 13:03:51 LOGON
MAPP_PLATFORM IDC-APP-01 16-08-29 13:03:41 LOGON
MAPP_PLATFORM IDC-APP-02 16-08-29 13:03:31 LOGON
MAPP_PLATFORM IDC-APP-01 16-08-29 13:03:21 LOGON
MAPP_PLATFORM IDC-APP-02 16-08-29 13:03:11 LOGON
MAPP_PLATFORM IDC-APP-01 16-08-29 13:03:01 LOGON
MAPP_PLATFORM IDC-APP-02 16-08-29 13:02:51 LOGON
MAPP_PLATFORM IDC-APP-01 16-08-29 13:02:41 LOGON
MAPP_PLATFORM IDC-APP-02 16-08-29 13:02:31 LOGON
。。。。
发现用户MAPP_PLATFORM从8.14到8.31,一直以错误密码尝试登陆数据库,验证了以错误密码登陆会导致row cache lock同时sql执行慢的现象发生。
进一步查询登录审计信息:
select * from
(
select os_username,userhost,terminal,username,count(*) failures
from dba_audit_trail
where returncode = 1017 and timestamp between to_date ('2016-8-29 11:30:00','yyyy-mm-dd hh24:mi:ss') and to_date ('2016-8-29 13:30:00','yyyy-mm-dd hh24:mi:ss')
group by os_username,userhost,username,terminal
order by 5 desc );
returncode = 1017 这里的1017就是oracle内部定义的错误返回代码值。
实际上不管用户提供的密码是否正确,Oracle都会为新的connection分配一个shadow process,该服务进程为了进一步验证用户信息都不得不获取少量资源;如果以此为契机,即便在无法正常登录的情况下依然能在短期内造成实例僵死。
About Me
...............................................................................................................................
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-05-09 09:00 ~ 2017-05-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。





来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/26736162/viewspace-2139754/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/26736162/viewspace-2139754/