CPU缓存
在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是,确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存。
基本描述
缓存的存储结构
结构上,一个直接映射(Direct Mapped)缓存由若干缓存块(Cache Block,或Cache Line)构成。每个缓存块存储具有连续内存地址的若干个存储单元。在32位计算机上这通常是一个双字(dword),即四个字节。因此,每个双字具有唯一的块内偏移量。
每个缓存块有一个索引(Index),它一般是内存地址的低端部分,但不含块内偏移和字节偏移所占的最低若干位。一个数据总量为4KB、缓存块大小为16B的直接映射缓存一共有256个缓存块,其索引范围为0到255。使用一个简单的移位函数,就可以求得任意内存地址对应的缓存块的索引。由于这是一种多对一映射,必须在存储一段数据的同时标示出这些数据在内存中的确切位置。所以每个缓存块都配有一个标签(Tag)。拼接标签值和此缓存块的索引,即可求得缓存块的内存地址。如果再加上块内偏移,就能得出任意一块数据的对应内存地址。
因此,在缓存大小不变的情况下,缓存块大小和缓存块总数成反比关系。下图中所示的缓存块来自一个数据总量为4KB、每个缓存块大小为16B的直接映射缓存,其标签长度为20bits( {\displaystyle 32-\log _{2}(4096\div 16)-\log _{2}16=20})。

此外,每个缓存块还可对应若干标志位,包括有效位(valid bit)、脏位(dirty bit)、使用位(use bit)等。这些位在保证正确性、排除冲突、优化性能等方面起着重要作用。
运作流程
下面简要描述一个假想的直接映射缓存的工作流程。这个缓存共有四个缓存块,每个块16字节,即4个字,因此共有64字节存储空间。使用写回(Write back)策略以保证数据一致性。
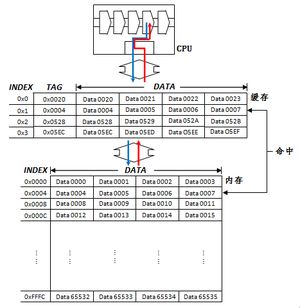
CPU缓存的运作流程(注意内存左侧给出的地址是字地址而不是字节地址)
系统启动时,缓存内没有任何数据。之后,数据逐渐被载入或换出缓存。假设在此后某一时间点,缓存和内存布局如右图所示。此时,若处理器执行数据读取指令,控制逻辑依如下流程:
- (将地址由高至低划分为四个部分:标签、索引、块内偏移、字节偏移。其中块内偏移和字节偏移各占两位,后者在以下操作中不使用。)
- 用索引定位到相应的缓存块。
- 用标签尝试匹配该缓存块的对应标签值。如果存在这样的匹配,称为命中(Hit);否则称为未命中(Miss)。
- 如命中,用块内偏移将已定位缓存块内的特定数据段取出,送回处理器。
- 如未命中,先用此块地址(标签+索引)从内存读取数据并载入到当前缓存块,再用块内偏移将位于此块内的特定数据单元取出,送回处理器。这里要注意的是,(1)读入的数据会冲掉之前的内容。为保证数据一致性,必须先将数据块内的现有内容写回内存。(2)尽管处理器请求的只是一个字,缓存仍必须在读取的时候把整个数据块都填充满。(3)缓存的读取是按缓存块大小为边界对齐的。对于大小为16字节的缓存块,任何因为0x0000、或0x0001、或0x0002、或0x0003造成的未命中,都会导致位于内存0x0000—0x0003的全部四个字被读入块中。
在右图中,如此时处理器请求的地址在0x0020到0x0023之间,或在0x0004到0x0007之间,或在0x0528到0x052B之间,或在0x05EC到0x05EF之间,均会命中。其余地址则全部未命中。
而处理器执行数据写入指令时,控制逻辑依如下流程:
- 用索引定位到相应的缓存块。
- 用标签尝试匹配该缓存块的对应标签值。其结果为命中或未命中。
- 如命中,用块内偏移定位此块内的目标字。然后直接改写这个字。
- 如未命中,依系统设计不同可有两种处理策略,分别称为按写分配(Write allocate)和不按写分配(No-write allocate)。如果是按写分配,则先如处理读未命中一样,将未命中数据读入缓存,然后再将数据写到被读入的字单元。如果是不按写分配,则直接将数据写回内存。
组相联
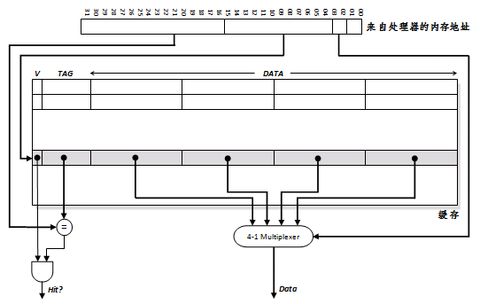
使用CPU地址查找直接匹配缓存的过程。首先以索引定位索引块,之后同时查看标签是否匹配,以及有效位是否被设置。如果标签匹配且数据有效,则通过4-1数据选择器,以块内偏移为输入,选定存储单元。
直接映射
为了便于数据查找,一般规定内存数据只能置于缓存的特定区域。对于直接映射缓存,每一个内存块地址都可通过模运算对应到一个唯一缓存块上。注意这是一种多对一映射:多个内存块地址须共享一个缓存区域。
{\displaystyle I=A_{mb}\mod N}
其中I为缓存索引,Amb为内存块地址,N为缓存块总数。
使用内存块地址而不是内存地址是因为缓存块通常包含一组连续的内存单元数据。以缓存块为32字节的直接映射缓存为例,内存地址Am到缓存索引的计算为
{\displaystyle I=\left(A_{m}\div 32\right)\mod N}
由于缓存字节数和缓存块数均为2的幂,上述运算可以由硬件通过移位极快地完成。
N路组相联
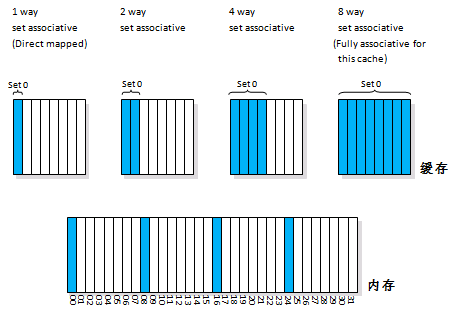
一、二、四、八路组相联缓存的比较
直接匹配缓存尽管在电路逻辑上十分简单,但是存在显著的冲突问题。由于多个不同的内存块仅共享一个缓存块,一旦发生缓存失效就必须将缓存块的当前内容清除出去。这种做法不但因为频繁的更换缓存内容造成了大量延迟,而且未能有效利用程序运行期所具有的时间局部性。
组相联(Set Associativity)是解决这一问题的主要办法。使用组相联的缓存把存储空间组织成多个组,每个组有若干数据块。通过建立内存数据和组索引的对应关系,一个内存块可以被载入到对应组内的任一数据块上。
以右图为例, 如使用2路组相联,内存地址为0、8、16、24的数据均可被置于缓存第0组中两个数据块的任意一个;如果使用4路组相联,内存地址为0、8、16、24的数据均可被置于缓存第0组中四个数据块的任意一个。一般地,
{\displaystyle I=\left(A_{m}\div Nw\div N_{a}\right)\mod N}
其中,I为缓存索引,Am为内存地址,Nw为缓存块内字数, Na为相联路数, N为组数。当使用组相联时,在通过索引定位到对应组之后,必须进一步地与所有缓存块的标签值进行匹配,以确定查找是否命中。这在一定程度上增加了电路复杂性,因此会导致查找速度有所降低。
此外,在不增大缓存大小的前提下单纯地增加组相联的路数,将不会改变缓存和内存的对应比例。再以右图为例,对于2路组相联,尽管第0组内有两个缓存块,但是该组现在也是内存块1、9、17、25的目标块。
直接匹配可以被认为是单路组相联。经验规则表明,在缓存小于128KB时,欲达到相同失效率,一个双路组相联缓存仅需相当于直接匹配缓存一半的存储空间[1]。
全相联
组相联的一个极端是全相联。这种缓存意味着内存中的数据块可以被放置到缓存的任意区域。这种相联完全免去了索引的使用,而直接通过在整个缓存空间上匹配标签进行查找。 由于这样的查找造成的电路延迟最长,因此仅在特殊场合,如缓存极小时,才会使用。
置换策略
对于组相联缓存,当一个组的全部缓存块都被占满后,如果再次发生缓存失效,就必须选择一个缓存块来替换掉。存在多种策略决定哪个块被替换。
显然,最理想的替换块应当是距下一次被访问最晚的那个。这种理想策略无法真正实现,但它为设计其他策略提供了方向。
先进先出算法(FIFO)替换掉进入组内时间最长的缓存块。最久未使用算法(LRU)则跟踪各个缓存块的使用状况,并根据统计比较出哪个块已经最长时间未被访问。对于2路以上相联,这个算法的时间代价会非常高。
对最久未使用算法的一个近似是非最近使用(NMRU)。这个算法仅记录哪一个缓存块是最近被使用的。在替换时,会随机替换掉任何一个其他的块。故称非最近使用。相比于LRU,这种算法仅需硬件为每一个缓存块增加一个使用位(use bit)即可。
此外,也可使用纯粹的随机替换法。测试表明完全随机替换的性能近似于LRU[2]。
写操作
回写策略
为了和下级存储(如内存)保持数据一致性,就必须把数据更新适时传播下去。这种传播通过回写来完成。一般有两种回写策略:写回(Write back)和写通(Write through)。
写回是指,仅当一个缓存块需要被替换回内存时,才将其内容写入内存。如果缓存命中,则总是不用更新内存。为了减少内存写操作,缓存块通常还设有一个脏位(dirty bit),用以标识该块在被载入之后是否发生过更新。如果一个缓存块在被置换回内存之前从未被写入过,则可以免去回写操作。
写回的优点是节省了大量的写操作。这主要是因为,对一个数据块内不同单元的更新仅需一次写操作即可完成。这种内存带宽上的节省进一步降低了能耗,因此颇适用于嵌入式系统。
| 回写策略 | 分配策略 | 当……时 | 写到…… |
|---|---|---|---|
| 写回 | 分配 | 命中 | 缓存 |
| 写回 | 分配 | 失效 | 缓存 |
| 写回 | 非分配 | 命中 | 缓存 |
| 写回 | 非分配 | 失效 | 内存 |
| 写通 | 分配 | 命中 | 缓存和内存 |
| 写通 | 分配 | 失效 | 缓存和内存 |
| 写通 | 非分配 | 命中 | 缓存和内存 |
| 写通 | 非分配 | 失效 | 内存 |
写通是指,每当缓存接收到写数据指令,都直接将数据写回到内存。如果此数据地址也在缓存中,则必须同时更新缓存。由于这种设计会引发造成大量写内存操作,有必要设置一个缓冲来减少硬件冲突。这个缓冲称作写缓冲器(Write buffer),通常不超过4个缓存块大小。不过,出于同样的目的,写缓冲器也可以用于写回型缓存。
写通较写回易于实现,并且能更简单地维持数据一致性。
按写分配与不按写分配
当发生写失效时,缓存可有两种处理策略,分别称为按写分配(Write allocate)和不按写分配(No-write allocate)。
按写分配是指,先如处理读失效一样,将所需数据读入缓存,然后再将数据写到被读入的单元。不按写分配则总是直接将数据写回内存。
设计缓存时可以使用回写策略和分配策略的任意组合。对于不同组合,发生数据写操作时的行为也有所不同。如右表所示。
地址翻译

实缓存的翻译步骤:1,访问TLB,将虚拟地址转换成物理地址。2,用物理地址的索引段定位缓存。3,用物理地址的标签段进行比较以决定是否命中。
由于计算机程序一般使用虚拟地址,一个必须决定的设计策略是缓存的地址标签及索引是使用虚拟地址还是物理地址。
虚缓存
一个简单的方案就是缓存的标签和索引均使用虚拟地址。这种缓存称为虚缓存(virtual cache)。这种缓存的优点是仅在缓存失效时才需要进行页面翻译。由于缓存命中率很高,需要翻译的次数也相对较少。
但是这种技术也存在严重的问题。
第一,引入虚拟地址的一个重要原因是在软件(操作系统)级进行页面保护,以防止进程间相互侵犯地址空间。由于这种保护是通过页表和翻译旁视缓冲器(TLB)中的保护位(protection bit)实现的,直接使用虚拟地址来访问数据等于绕过了页面保护。一个解决办法是在缓存失效时查看TLB对应表项的保护位以确定是否可以加载缺失的数据。
第二,由于不同进程使用相同的虚拟地址空间,在切换进程后会出现整个缓存都不再对应新进程的有效数据。如果前后两个进程使用了相同的地址区间,就可能会造成缓存命中,却访问了错误的地址,导致程序错误。有两个解决办法:(1)进程切换后清空缓存。代价过高。(2)使用进程标识符(PID)作为缓存标签的一部分,以区分不同进程的地址空间。
第三,别名问题(Alias)。由于操作系统可能允许页面别名,即多个虚拟页面映射至同一物理页面,使用虚拟地址做标签将可能导致一份数据在缓存中出现多份拷贝的情形。这种情况下如果对其中一份拷贝作出修改,而其他拷贝没有同步更新,则数据丧失整合性,导致程序错误。有两个解决办法:(1)硬件级反别名。当缓存载入目标数据时,确认缓存内没有缓存块的标签是此地址的别名。如果有则不载入,而直接返回别名缓存块内的数据。(2)页面着色(Page Coloring)。这种技术是由操作系统对页面别名作出限制,使指向同一页面的别名页面具有相同的低端地址。这样,只要缓存的索引范围足够小,就能保证在缓存中决不会出现来自不同别名页面的数据。
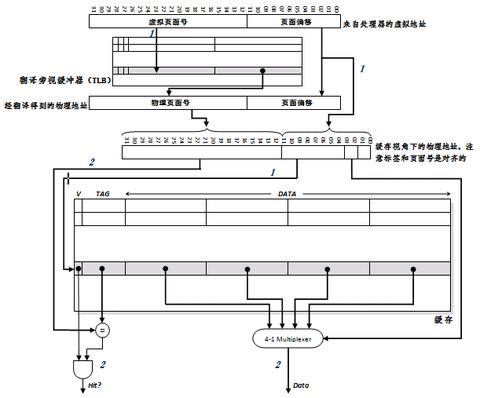
虚索引、实标签缓存的翻译步骤:1,访问TLB,将虚拟地址转换成物理地址;同时,以虚拟地址的页内偏移(但不含最后若干位的缓存段内偏移)直接作为索引定位缓存。2,用物理地址的标签段进行比较以决定是否命中。
第四,输入输出问题。由于输入输出系统通常只使用物理地址,虚缓存必须引入一种逆映射技术来实现虚拟地址到物理地址的转换。
实缓存
实缓存(physical cache)完全使用物理地址做缓存块的标签和索引,故地址翻译必须在访问缓存之前进行。这种传统方法所以可行的一个重要原因是TLB的访问周期非常短(因为本质上TLB也是一个缓存),因而可以被纳入流水线。
但是,由于地址翻译发生在缓存访问之前,会比虚缓存更加频繁地造成TLB。(相比之下,虚缓存仅在本身失效的前提下才会访问TLB,进而有可能引发TLB失效)实缓存在运行中存在这样一种可能:首先触发了一个TLB失效,然后从页表中更换TLB表项(假定页表中能找到)。然后再重新访问TLB,翻译地址,最后发现数据不在缓存中。[3]
虚索引、实标签缓存
一个折中方案是同时使用虚索引和实标签(virtually indexed, physically tagged)。这种缓存利用了页面技术的一个特征,即虚拟地址和物理地址享有相同的页内偏移值(page offset)。这样,可以使用页内偏移作为缓存索引,同时使用物理页面号作为标签。这种混合方式的好处在于,其既能有效消除诸如别名引用等纯虚缓存的固有问题,又可以通过对TLB和缓存的并行访问来缩短流水线延迟。
这种技术的一个缺点是,在使用直接匹配缓存的前提下,缓存大小不能超过页面大小,否则页面偏移范围就不足以覆盖缓存索引范围。这个弊端可以通过提高组相联路数来改善。
多级缓存
引入动机
介于处理器和内存二者之间的缓存有两个天然冲突的性能指标:速度和容积。如果只向处理器看齐而追求速度,则必然要靠减少容积来换取访问时间;如果只向内存看齐而追求容积,则必然以增加处理器的访问时间为牺牲。这种矛盾促使人们考虑使用多级缓存。
| 级别 | 大小 | 相联度 | 命中时间 |
|---|---|---|---|
| L1 | 64KB | 双路 | 3周期 |
| L2 | 512KB | 16路 | +9周期 |
| L3 | 2MB | 32路 | ~+38周期 |
在一个两级缓存体系中,一级缓存靠近处理器一侧,二级缓存靠近内存一侧。当一级缓存发生失效时,它向二级缓存发出请求。如果请求在二级缓存上命中,则数据交还给一级缓存;如失效,二级缓存进一步向内存发出请求。对于三级缓存可依此类推。
通常,更接近内存的缓存有着更大容积,但是速度也更慢。以AMD Opteron X4处理器为例,见右表比较[4]。
值得注意的是,无论如何,低级缓存的局部命中率总是低于高级缓存。这是因为数据的时空局部性在一级缓存上基本上已经利用殆尽。
设计考虑
虽然功能类似,但不同级别的缓存在设计和实现上也有不同之处。
尽管一般而言,在存储体系结构中低级存储总是包含高级存储的全部数据,但对于多级缓存则未必。相反地,存在一种多级排他性(Multilevel exclusion)的设计。此种设计意指高级缓存中的内容和低级缓存的内容完全不相交。这样,如果一个高级缓存请求失效,并在次级缓存中命中的话,次级缓存会将命中数据和高级缓存中的一项进行交换,以保证排他性。
多级排他性的好处是在存储预算有限的前提下可以让低级缓存更多地存储数据。否则低级缓存的大量空间将不得不用于覆盖高级缓存中的数据,这无益于提高低级缓存的命中率。
当然,也可以如内存对缓存般,使用多级包容性(Multilevel inclusion)设计。这种设计的优点是比较容易方便查看缓存和内存间的数据一致性,因为仅检查最低一级缓存即可。对于多级排他性缓存这种检查必须在各级上分别进行。这种设计的一个主要缺点是,一旦低级缓存由于失效而被更新,就必须相应更新在高级缓存上所有对应的数据。因此,通常令各级缓存的缓存块大小一致,从而减少低级对高级的不必要更新。
此外,各级缓存的写策略也不相同。对于一个两级缓存系统,一级缓存可能会使用写通来简化实现,而二级缓存使用写回确保数据一致性。
性能评估
性能评估模型
评估缓存的性能通常使用平均内存访问时间(Average Memory Access Time, AMAT)这一指标。在一个简化模型中,该值可依下式求得:
{\displaystyle AMAT=T_{hit}+MR\times MP}
式中三项的意义:

不同大小、不同组相联缓存运行SPEC CPU2000整数程序的失效率比较。注意每条曲线均呈三段式下降,这实际上分别体现了容量失效(容量过小时)、冲突失效和强制失效(容量逼近无限大时)。
- {\displaystyle T_{hit}}为命中时间(Hit Time):从定位缓存块、经标签比较并选中,一直到传回数据所需的时间。
- {\displaystyle MR}为失效率(Miss Rate):在特定次数的内存访问中,发生缓存失效次数所占的比重。
- {\displaystyle MP}为失效代价(Miss Penalty):从定位缓存块、经标签比较判定失效,然后再从内存中定位数据并载入缓存,最后直到把目标数据返回所需的时间。
失效分析
Mark Hill在对缓存失效的情形进行研究后给出了三种缓存失效的原因,称为3C。
- 强制失效(Compulsory miss),又称冷失效(Cold start miss),指地址第一次被引用时的失效。改变缓存大小或相联度都不能影响这类失效。
- 容量失效(Capacity miss),是指某段数据由于缓存已满而被逐出后,当缓存再一次企图访问此数据时造成的失效。改变缓存块大小或相联度都不能影响这类失效。
- 冲突失效(Conflict miss),是指内存中不同的块被映射到缓存中相同的组或块,导致访问时产生冲突而失效。也叫Collision misses 或者 Interference misses。这类失效对于全相联缓存并不存在。
此外,在多处理器系统中,还存在为保证各处理器缓存之间的数据一致性而进行数据清空/无效化所造成的失效。这类失效称为一致失效(Coherency miss)。
优化技术
根据AMAT的计算式,可以看出优化缓存可从三个方面入手:一、减少命中时间;二、降低失效率;三、减轻失效代价。此外,增加缓存访问带宽也能有效较低AMAT。
存在多种优化技术来实现削减三个构成变量对AMAT造成的影响。应注意的是,由于缓存的内在性质,某些技术可能在减少一个因子的同时,增加了另一个因子。
减少命中时间
虚索引、实标签缓存
理论上,完全使用虚拟地址可以获得更快的缓存访问速度,因为这样仅在缓存失效时才会进行地址翻译。但是,如前所述,这种纯虚地址缓存由于绕开了操作系统对进程访问地址的软件控制,会存在不少问题。
为了能接近虚缓存的访问速度,又能避开虚缓存带来的种种问题,引入了所谓虚索引、实标签缓存(virtually indexed, physically tagged)。这种结构的缓存可以令地址翻译和缓存查询并发进行,大大加快了缓存的访问速度。详见地址翻译一节。
小而简单的缓存[编辑]
由于电路延迟很大程度上取决于存储芯片的大小,所以可考虑使用较小容量的缓存以保证最短的访问周期。这么做的另一个好处是,由于一级缓存足够小,可以把二级缓存的全部或部分也集成到CPU芯片上,从而减少了二级缓存的命中时间。
AMD从K6到Opteron连续三代CPU的一级缓存容量都没有任何增长(均为64KB)正是基于这个原因[5]。
另一方面,考虑使用简单的缓存,如直接匹配缓存,也可较组相联缓存减少命中时间。
路预测[编辑]
所谓路预测(Way prediction),是指在组相联缓存中,跟踪同一组内不同缓存块的使用情况,然后在访问到来时,不经比较直接返回预测的缓存块。当然,标签比较仍然会进行,并且如果发现比较结果不同于预测结果,就会重新送出正确的缓存块。也就是说,错误预测会造成一个缓存块长度的延迟。
模拟表明路预测的准确率超过85%[6]。这种技术非常适合于投机执行(Speculative Execution)处理器,因为这种处理器有完善的机制来保证在投机失败之后取消已经派发的指令。
追踪缓存
与一般的指令缓存存储静态连续地址不同,追踪缓存(Trace Cache)存储的是基于执行历史的动态地址序列。这实际上是把分支预测的结果用在了缓存上。由于只存储沿某一特定分支路径才会遇到的指令,这种缓存可比传统缓存更节省空间。
追踪缓存的缺点是实现复杂,因为必须设法连续存储的数据并不会按照2的幂次字长对齐。此外,对于不同执行路径要分开存储。如果这些执行路径中存在相同地址的指令,这些指令就只好被分别存到两个地方。这反而造成了低效的空间利用。
Intel的Pentium 4处理器使用了这一复杂技术。值得一提的是,Pentium 4追踪缓存存储的不是从内存抓取的原始指令,而是已经过解码的微操作,从而进一步节省掉了指令解码上要花的时间。
增加访问带宽
缓存流水线化
将一级缓存并入流水线是一般做法。这种做法可行性在于一级缓存的访问时间通常都极短,可能只有一到数个CPU周期。此外,由于TLB也是一种高速缓存硬件,故也可以纳入流水线。
非阻塞缓存
一般而言,当缓存发生失效时,处理器必须停滞(stall),等待缓存将数据从次级存储中读取出来。
当时,对于跨序执行(Out-of-order Execution)处理器,由于多条指令在不同处理单元中并发执行,某一条指令引发的缓存失效应该只造成其所在处理单元的停滞,而不影响其他处理单元和指令派发单元继续流水。因此,有必要设计这样一种缓存,使之能够在处理缓存失效的同时,继续接受来自处理器的访问请求。这称为非阻塞缓存(Non-blocking cache)。
降低失效率
使用更大的数据块
使用大数据块有助于利用空间局部性降低失效率,但其代价是更高的失效代价。这是因为,一旦失效,就必须把整个数据块都重新填满。
使用更大的缓存
单纯增大缓存的容量也是降低失效率的一个办法。不过显然这也增大了命中时间。
高组相联缓存
使用多路组相联可以减少冲突失效。但其后果是缓存电路逻辑复杂化,故增大了命中时间。
编译器优化
存在多种编译器优化技术来间接影响缓存的使用模式。下面仅举几例,且均假定编译器采用行主序(Row-major order)存储数组:
1. 循环交换(Loop Interchange)
考虑一个对二维数组a[100][5000]的循环处理
a[100][5000] = ... //初始化
for (j = 0; j < 5000; j = j + 1) {
for (i = 0; i < 100; i = i + 1)
a[i][j] = 2 * a[i][j];
}
如果源代码的外循环遍历行,而内循环遍历列,则总是会造成大量的缓存失效。这是因为当失效时,缓存从内存中抓取的整个数据块几乎都是同行不同列的数据,而这些数据在接下来的内循环中完全无法被重复利用。
通过循环交换改进如下
a[100][5000] = ... //初始化
for (i = 0; i < 100; i = i + 1) {
for (j = 0; j < 5000; j = j + 1)
a[i][j] = 2 * a[i][j];
}
这样,缓存因为a[i][0]失效而从内存中抓取的数据块实际上覆盖了a[i][0]到a[i][7]的全部数据(假定使用32字节大小的缓存块,每个整型值占四字节)。这样后边连续七次内循环均可告命中。
2. 循环合并(Loop fusion)
考虑下边的代码
a[1000] = ... //初始化
for (i = 0; i < 1000; i = i + 1)
a[i] = 2 * a[i];
for (i = 0; i < 1000; i = i + 1)
b[i] = a[i] + CONSTANT;
如果编译器可以证明两个循环体可以合并到一个基本块而不影响程序结果,则应该进行合并。这是因为,通过合并,原来第二个循环的语句在访问内存时必然会命中。
合并后的代码
a[1000] = ... //初始化
for (i = 0; i < 1000; i = i + 1) {
a[i] = 2 * a[i];
b[i] = a[i] + CONSTANT;//对a[i]的访问必然命中缓存
}
3. 循环分块(Blocking)
当循环遍历的内存范围很大(例如一个大数组)时,由于缓存容积有限,可能会导致每次遍历结束时留下的缓存布局完全无法被接下来的一次遍历利用。这种情形下对循环进行分块就十分有意义。
假设现在使用了一个非常小的全相联缓存,只有四个缓存段,每个16字节。二维整型数组b和c的大小均为1024*1024,并被存储上内存的连续地址上。由于每个整数占4个字节,故在这个缓存最多只能容纳16个整数。假定该缓存使用LRU置换策略。首先考虑未经过优化的代码。这个代码段遍历整个矩阵,每次遍历过程中交替访问由i和j分别指定的向量b[i][0]-b[i][1023]和c[0][j]-c[1023][j]。
b[1024] = ... //初始化
c[1024] = ... //初始化
for (i = 0; i < 1024; i = i + 1) {
for (j = 0; j < 1024; j = j + 1) {
for (k = 0; k < 1024; k = k + 1)
... = b[i][k] + c[k][j];
}
}
由于缓存极小,这段代码效率十分低。考虑当i=0、j=0时,最内循环最后一次遍历中,在访问完b[i][k](实际上是b[0][1023])之后,但还没有访问c[k][j](实际上是c[1023][0])的情形,缓存内容如下图所示。
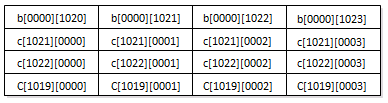
之后,访问c[1023][0],缓存被刷新为
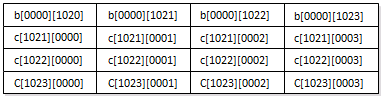
这样一个结果无疑对于下一次遍历(i=0、j=1)毫无价值。因为在k自增到4之前,所有数据都无法被重复利用,结果只能被换出。但如果改成
b[1024] = ... //初始化
c[1024] = ... //初始化
int B = 4;
for (jj = 0; jj < 1024; jj = jj + B) {
for (kk = 0; kk < 1024; kk = kk + B) {
for (i = 0; i < 1024; i = i + 1) {
for (j = jj; j < min(jj + B, 1024); j = j + 1) {
for (k = kk; k < min(kk + B, 1024); k = k + 1)
... = b[i][k] + c[k][j];
}
}
}
}
再次考虑当jj=0、kk=0、i=0、j=0时,最内循环最后一次遍历中,在访问完b[i][k](实际上是b[0][3])之后,但还没有访问c[k][j](实际上是c[3][0])的情形,缓存内容如下图所示。
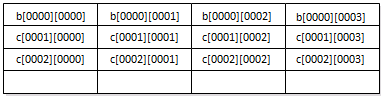
之后,访问c[3][0],缓存被刷新为
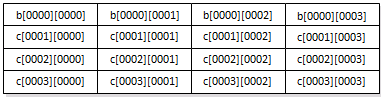
这样的结果对于下一次遍历(jj=0、kk=0、i=0、j=1)就十分有价值,因为所需数据的大部分,包括b[0][0]-b[0][3]和c[1][1]-c[3][1],全都已在缓存中。
此外,还有数组合并(Array merge)、循环分解(Loop fission)、分支取直(Branch Straightening)等多种技术。
预取
为了利用空间局部性,同时也为了覆盖传输延迟,可以随机性地在数据被用到之前就将其取入缓存。这一技术称为预取(Prefetch)。本质上讲,加载整个缓存块其实即是一种预取。
预取可以通过硬件或软件控制。典型的硬件指令预取会在缓存因失效从内存载入一个块的同时,把该块之后紧邻的一个块也传输过来。第二个块不会直接进入缓存,而是被排入指令流缓冲器(Instruction Stream Buffer)中。之后,当第二个内存访问指令到来时,会并行尝试从缓存和流缓冲器中读取。如果该数据恰好在流缓冲器中,则取消缓存访问指令,并将返回流缓冲器中的数据。同时,发出起一次新的预取。如果数据并不在流缓冲器中,则需要将缓冲器清空。
软件控制则多由编译器进行。指令集会提供预取指令供编译器优化时使用。编译器则负责分析代码,并把预取指令适当地插入其中。这类指令直接把目标预取数据载入缓存。
在使用预取技术时,必须妥善考虑进行时机和实施强度。如果过早地进行预取,则有可能在预取数据被用到之前就已经因为冲突置换被清除。如果预取得太多或太频繁,则预取数据有可能将那些更加确实地会被用到的数据取代出缓存。
减轻失效代价
多级缓存
相对于单级缓存,多级缓存的性能模型可以下式表示:
{\displaystyle AMAT=T_{L1.hit}+MR_{L1}\times MP_{L1}}
{\displaystyle MP_{L1}=T_{L2.hit}+MR_{L2}\times MP_{L2}}
由于全局失效率等于两个局部失效率{\displaystyle MR_{L1}}和{\displaystyle MR_{L2}}之积,故使用多级缓存降低了失效率。
读失效优先策略
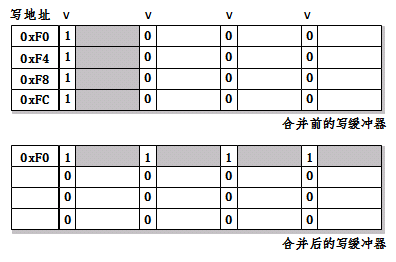
合并写缓冲器。注意每个字前都有一个有效位,用于标识跟在此位置后的字是否需要写入内存。
对于使用写缓冲器的缓存,当出现读失效时会遇到一个问题:所要读取的数据已经被修改,但是还没有更新到内存。也就是说,新数据还在写缓冲器中。
解决方案有二:一、等待,直到写缓冲器清空。这种方法显然效率不高。二、在读缓存的同时检查写缓冲器,确认最新数据是否在已在写缓冲器中。如果有则直接从写缓冲器返回。这种方法的本质是相比于回写操作,赋予读失效处理更高的优先级。
关键词优先
如前述,缓存从内存读取数据时需要把整个缓存块都填满,再返回偏移指定单元给处理器。但其实可以做这样的优化,即令缓存从对应内存块的相应偏移位置,也就是关键词(Critical word),开始读数据,然后一旦第一个数据单元被传回,就立即将其交给处理器。
另有一个叫做早重启(Early Restart)的类似技术。这种技术仍然从内存块的起始位置按常序传输数据,但是一旦关键词数据返回,就将其传回处理器。可见,这种方法在减少处理器停滞上逊于关键词优先法。
合并写缓冲器
写缓冲器通常可以令1到4个缓存块排队等待回写。但事实上大部分写操作都只是针对缓存块的某一个单元进行的。同时,因为经常会出现对一块连续内存按序进行写操作(比如初始化一个数组),所以可以考虑将连续的写操作合并为一个写操作。
特殊的缓存结构
指令-数据分离缓存
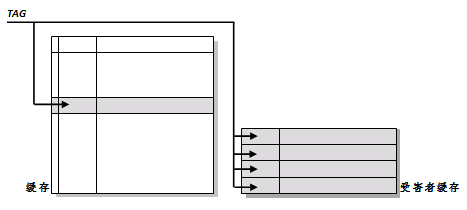
受害者缓存。标签比较同时在选中缓存块和受害者缓存全域上进行。
由于流水线会在指令抓取和内存访问两个阶段上访问内存,如不增加缓存端口将会造成结构性冒险(Structural hazard)。一种办法是使用两片一级缓存,分别服务于指令抓取和内存访问两个阶段。这样,前一个一级缓存称为指令缓存,后一个则为数据缓存。从处理器的观点来看,这相当于采用了哈佛架构的存储系统。
受害者缓存
所谓受害者缓存(Victim Cache),是一个与直接匹配或低相联缓存并用的、容量很小的全相联缓存。当一个数据块被逐出缓存时,并不直接丢弃,而是暂先进入受害者缓存。如果受害者缓存已满,就替换掉其中一项。当进行缓存标签匹配时,在与索引指向标签匹配的同时,并行查看受害者缓存,如果在受害者缓存发现匹配,就将其此数据块与缓存中的不匹配数据块做交换,同时返回给处理器。
受害者缓存的意图是弥补因为低相联度造成的频繁替换所损失的时间局部性。