消息队列面试解析系列(四)- 消息可靠性投递的实现原理

丢失消息则丢了数据,这是我们不能接受的,否则MQ意义何在?
因此主流MQ其实都提供了可靠性投递机制,确保即使网络异常,消息也能可靠传递,而不会丢失。
如果发现还是丢失消息了,多半是开发者问题,很可能没有正确配置MQ。不同MQ在保证消息可靠传递方面的实现原理其实也是一样的。
1 验证丢失的消息
大公司一般都通过分布式链路追踪系统,很方便追踪每条消息。
如果是中小公司,也有个简单方案验证。即利用MQ的有序性:
- 在Producer端,给每个发出的消息附加一个连续递增的序号
- 然后在Consumer端检查这序号的连续性
- Consumer收到消息序号严格递增,则无消息丢失
- 若存在序号不连续,则丢了消息
通过缺失的序号还能确定到底丢失的哪条消息
大多MQ客户端支持拦截器,可在Pro发消息前的拦截器中注入序号到消息中,在Con收消息的拦截器中检测序号连续性。
- 好处
消息验证代码不会侵入业务代码。系统稳定后也方便将验证逻辑关闭/删除。
分布式系统下实现验证方法,须注意:
- Kafka、RocketMQ不保证在Topic上的严格顺序,只保证分区上的消息有序,所以在发消息时须指定分区。且在每个分区单独验证消息序号连续性。
如果系统的Producer多实例,由于并不好协调多Producer之间的发送顺序,所以也需要每个Producer分别生成消息序号,且需要附加Producer标识,在Con端按每个Pro分别验证序号连续性。
Consumer实例数量最好和分区数量一一对应,如此便可方便在Con内验证消息序号连续性。
2 确保消息可靠传递
有小伙伴要问了,到底哪些地方会导致丢消息,又该如何避免呢?
- 消息从生产到消费完成的阶段
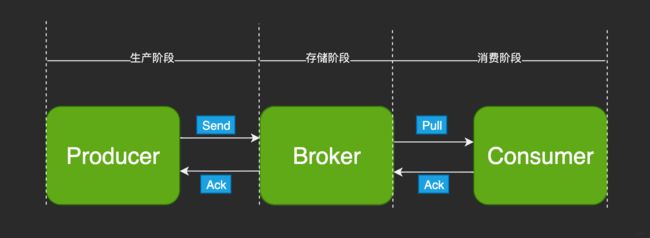
2.1 生产阶段
在Producer创建消息出来,通过网络传输发送到Broker。
MQ通过最常用的请求确认机制保证消息可靠传递:
调用发消息方法时,MQ客户端把消息发至于Broker,Broker收到后,给客户端返回确认响应,表明已收。客户端收到响应后,完成一次正常消息的发送。
只要Pro收到Broker的确认,即可保证消息在生产阶段不会丢失。
- 有些MQ长时间未收到发送确认响应后,会自动重试
- 若重试失败,以返回值或者异常方式通知用户
写发消息代码时,注意正确处理返回值或捕获异常,即可保证该阶段消息不会丢失。
示例
以Kafka为例看可靠发送消息:
同步发送时,只要注意捕获异常即可。
try {
RecordMetadata metadata = producer.send(record).get();
System.out.println("消息发送成功。");
} catch (Throwable e) {
System.out.println("消息发送失败!");
System.out.println(e);
}
异步发送,则需在回调方法检查。
很多丢消息的原因即在使用异步发送时,却未在回调里检查发送结果。
producer.send(record, (metadata, exception) -> {
if (metadata != null) {
System.out.println("消息发送成功。");
} else {
System.out.println("消息发送失败!");
System.out.println(exception);
}
});
2.2 存储阶段
消息在Broker端存储,如果是集群,消息会在该阶段被复制到其他副本。
正常情况下,只要Broker正常运行,就不会丢失消息。
但若Broker异常,比如进程卡死或服务器宕机,则可能丢失消息。
如果对消息可靠性要求非常高,可通过配置Broker参数避免因为宕机丢消息。
对单节点Broker,需配置Broker参数:在收消息后,将消息写进磁盘后再给Pro发确认响应,这即使宕机,也不会丢消息,恢复后还可继续消费。
- 如在RocketMQ中,需将默认的异步刷盘方式flushDiskType

- 配置为SYNC_FLUSH同步刷盘。

若Broker属多节点集群,需配置Broker集群:至少将消息发到2个以上节点,再给客户端发确认响应。如此一来,当某Broker宕机,其它Broker可替代宕机节点,也不会发生消息丢失。
2.3 消费阶段
Con从Broker拉消息,经过网络传输发到Con。
该阶段采用和生产阶段类似的确认机制保证可靠传递。
客户端从Broker拉取消息后,执行用户的消费业务逻辑,成功后,才会给Broker发送消费确认响应。如果Broker没有收到消费确认响应,下次拉消息的时候还会返回同一条消息,确保消息不会在网络传输过程中丢失,也不会因为客户端在执行消费逻辑中出错导致丢失。
编写消费代码时注意,不要在收到消息后就立即发消费确认,而在执行完所有消费业务逻辑后,再发送消费确认。
见如下以Python语言消费RabbitMQ消息为例,实现可靠的消费代码:
def callback(ch, method, properties, body):
print(" [x] 收到消息 %r" % body)
# 在这儿处理收到的消息
database.save(body)
print(" [x] 消费完成")
# 完成消费业务逻辑后发送消费确认响应
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(queue='hello', on_message_callback=callback)
在消费的回调方法callback中,正确顺序是
- 先把消息存到数据库
- 然后再发送消费确认响应
这样如果保存消息到数据库失败,就不会执行消费确认代码,下次拉到的还是该消息,直至消费成功。
3 总结
一条消息从发送到消费整个流程,MQ如何确保消息可靠投递不丢失。该过程可分三阶段,每阶段都需正确编写代码且正确配置,才能配合MQ可靠机制,确保消息不丢失。
- 生产阶段,需捕获消息发送的错误,并重发消息
- 存储阶段,可通过配置刷盘和复制相关的参数,让消息写进多个副本的磁盘,确保消息不会因某Broker宕机或磁盘损坏而丢失
- 消费阶段,要在处理完全部消费业务逻辑后,再发消费确认
理解这几阶段原理后,若再出现丢消息,可通过在代码中加日志,定位哪个阶段出问题了,再进一步分析。
4 面试场景快问快答
两消费者先后去拉消息,是否会拉到同条
拉消息时,消费者A pull后,没有发确认给Broker就宕机(或因代码问题超时阻塞),这时消息应该还在Broker,消费者B如果此时pull,是否会拉取到那条给消费者A的消息?即
首先,MQ一般都有协调机制,不会让这情况出现。但由于网络不确定性,这情况极小概率也会出现。
在同一消费组内,A消费者拉走index=10的消息,还没发确认,这时这分区的消费位置还是10,B消费者来拉消息,可能有2种情况:
- 超时前,Broker认为该分区还被A占用,会拒绝B请求
- 超时后,Broker认为A已经超时没返回,此次消费失败,但当前消费位置还是10,B再来拉消息,会给它返回10这条消息
消费者处理重复消息
若消息在网络传输过程发送错误,由于发送方收不到确认,会通过重发保证消息不丢失。但若确认响应在网络传输时丢失,也会导致重发消息。即无论Broker、Consumer都可能收到重复消息,编写消费代码时,就得考虑这情况。
在消费消息的代码中,该如何处理这种重复消息,才不会影响业务逻辑的正确性呢?
产生重复消息原因:
- 发送消息阶段,发送重复的消息
- 消费消息阶段,消费重复的消息
一般消息中都会存在个唯一性东西。不管是MQ本身的msgId
还是业务订单号之类,可在DB中存在一个消费表,对这唯一性东西建立唯一索引。
每次处理消费者逻辑前先insert,让DB帮我们去重。

解决方案:业务端去重
- 建立一个消息表,consumer消费之前,拿到消息做insert操作,用消息id做唯一主键,重复消费会导致主键冲突
- 利用redis,给消息分配一个全局id,只要消费过该消息,将消息以K-V(< id,message>)形式写入redis,消费消息之前,根据key去redis查询是否有对应记录。
当Pro发消息给Broker时(send方法),此方法会在Broker收到消息并正常储存后才返回,期间应该会阻塞,即如果Broker配置同步刷盘,可能会增加调用时间(只能出现对消息敏感场景)。
=======================
消费端支持幂等操作,业务上一般有难度。可考虑消费端增加去冗余机制,例如缓存最新消费成功的N条消息的SN,收到消息后,先确认是否是消费过的消息,如果是,直接ACK并放弃消费。
思路没问题。
=======================
幂等性是一种办法,如果做不到幂等性,那么在消费端需要存储消费的消息ID,关键这个ID什么时候存?
- 如果是消费前存,那么消费失败,下次消费同样消息,是否会认为上次已经成功?
- 如果在消费成功后存,那么消费会不会出现部分成功情况?除非满足事务ACID特性。
如果靠ID连续性检查,是不是一个producer只对应一个consumer?
不用,Producer发消息时带着ProducerId并要指定分区发送,Consumer消费时,需按照每个Producer来检查序号连续性。
=======================
如果Producer的某条消息ack因网络故障丢失,那么Producer此时重发消息的唯一标识应该和之前那条消息一样,那只需在Consumer接受消息前判断是否有相同标识的消息,如果有则拦截。
还可在消费端业务逻辑接口中做幂等判断,前面那种可以做到不侵入到业务代码。
非常好!但需要考虑,在分布式环境中“Consumer接受消息前判断是否有相同标识的消息”该如何实现呢?
=======================
检测消息丢失是在还没上线之前做的测试,但是会不会可能在线下没出现消息不一致,但是在线上的时候出现消息丢失了?线上检测消息丢失逻辑会关闭,那线上是会有其他的检测机制么?
这个检测逻辑可以在线上做,不会影响业务。