【论文笔记】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
本文主要用于记录谷歌发表于2018年的一篇论文。该论文提出的BERT模型被各地学者媒体美誉为NLP新一代大杀器。本笔记主要为方便初学者快速入门,以及自我回顾。
论文链接:https://arxiv.org/pdf/1706.03762.pdf
基本目录如下:
- 摘要
- 核心思想
- 总结
------------------第一菇 - 摘要------------------
1.1 论文摘要
本文作者推出了一套新的语言表达模型BERT,全称为Bidirectional Encoder Representations from Transformers。与近年来提出的语言模型不一样的地方在于,BERT不再仅仅是只关注一个词前文或后文的信息,而是整个模型的所有层都去关注其整个上下文的语境信息。实验结果证明,使用预训练过的BERT模型,仅仅在后面再包一层输出层,并对其进行微调训练,就可以取得很不错的结果。具体有多不错,那就是刷爆了NLP领域的11大任务,甚至有几项任务的准确率已经超过了人类。
------------------第二菇 - 核心思想------------------
2.1 论文模型背景
其实BERT模型本身的提出,说实话,并不是什么划时代的产物,只不过他的效果直接刷爆了NLP的各项任务(谷歌家强大的计算资源也是原因之一,想复现这篇论文难度也是很大),看起来比较震撼。所以,该篇论文之所以有那么高的评价,倒不是模型本身有多出色,或者预训练方法有多标新立异,我个人更愿意称其为近年NLP领域突破的集大成者(确实是一个里程碑)。因此,为了能更好的理解这篇文章所表达的内涵,光是看这一篇文章是远远不够的,所以,不同于以往直接深入文章核心,这里先随着论文一起聊聊本文的模型背景。
在NLP领域,语言模型的预训练早已被证明是提高下游模型表现的不二选择,从目前提出的预训练方法来看,主要可以分为两个类型如下,
1)基于特征(Feature-Based)主要的代表有ELMO,用做任务的模型来学习提前预训练好的语言模型内部隐状态的组合参数。(详情可参见我的另一篇论文笔记来讲ELMO的)。
2)微调(Fine-Tuning)主要的代表有OpenAI GPT,用做任务的数据来微调已经训练好的语言模型。
但是以上的预训练都存在一个问题,即在预训练的时候,仅仅考虑了文本的单向顺序,不论是从左到右,还是从右到左,始终不能很好的解决想同时学习这个词汇上下文的信息的问题(ELMO那篇其实也是Bi-directional LM,但确实没有做到同时学习这点,毕竟只是把从左到右和从右到左拼接在一起。。。暂时不知道作者这么说的意思具体指什么,我目前就单纯的理解为作者提出的这个思想核心在于“同时”,而其他NLP的Bi依然停留在分别训练再concact的层面)。因此本文的最大的创新点也就在此了,提出了一种新的预训练语言模型的方法。除此之外,本论文的其他几大贡献为,
1)用实验证实利用完整预训练的语言模型,能大大减轻业务端的网络结构的复杂度,上一些轻型的模型就能够取得很好的效果,甚至超过那些专为业务设计的复杂网络结构。
2)作者预训练的这一套BERT模型,刷爆了各大任务指标,希望这一套模型能成为NLP领域的ResNet,开创NLP新时代!
2.2 论文模型结构
论文的模型倒没有什么特别的创新,主要还是Transformer那一套(不熟悉的同学可以看我另一篇笔记,里面有详细的介绍),这里直接贴一张原论文的图,想必大家应该也能看懂。(原论文对于BERT还有BASE和LARGE的区别,BASE主要是为了对标比较OPENAI GPT)
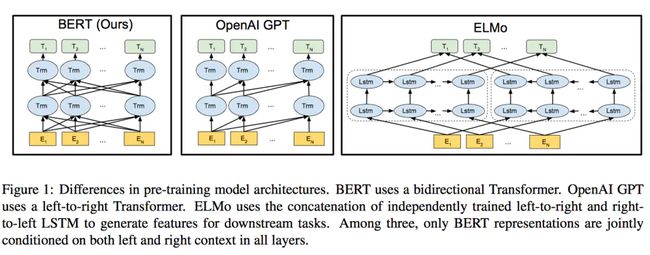
model_structure.png
(PS. 看模型图,这个真的是做到了上下文信息一起进去了,所有的token都有一个指向每一个Transformer的箭头)
以及顺便得再提一下,模型的输入包括三个部分,分别为
1)基于词级别的词向量(分隔以后)
2)基于位置的向量
3)每一个句子的向量(分隔以后)
具体可以见下图,应该说是很清楚了,
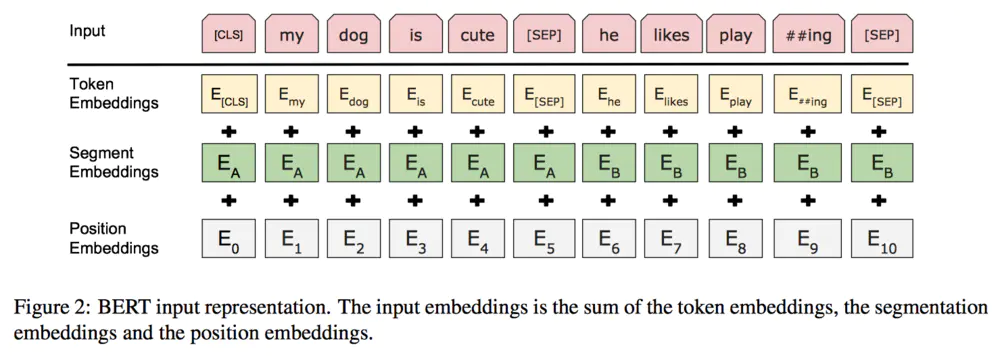
model_input.png
2.3 论文预训练方法 - Masked LM
接下来重点解析一下作者的预训练方法。为了训练一个深度双向表示模型,作者提出了一种屏蔽一句话中的部分词的训练方法,然后让模型来预测屏蔽的那个词(同比于CBOW,就是根据这个词的上下文,去预测每一个词,损失函数由所有词的loss组成,而本文的loss只来源于那些被屏蔽的词)。在作者的实验设置中,大约15%的词被随机屏蔽。但是这样的训练方法有两个缺陷。
1)预训练阶段与微调阶段不一致,因为微调阶段是不会有【MASK】存在的,所以考虑到这一层面,作者也不总是将随机选择的词屏蔽为MASK,主要的操作如下描述(相信大家一定看的懂,就不翻译了)

masked_LM.png
这样预训练的好处就是,此时模型是不知道要去预测哪一个词的,所以就能达到作者想训练一个深度双向模型的目的(输入见上)。并且作者还强调了一下,随机屏蔽的这一点量,似乎并不会影响文本的语言理解。
2)正因为从理论上来讲每一次都只有15%的词是来被训练到的,所以,需要更多预训练的计算与时间成本。而作者也在后文实验证实了该方法确实收敛的较慢,但是效果好呀!(对于这种,只要做好一次,就能一劳永逸的预训练模型,时间和计算成本的增加对谷歌来说确实是小case哈哈)
关于该预训练方法的图解如下【1】
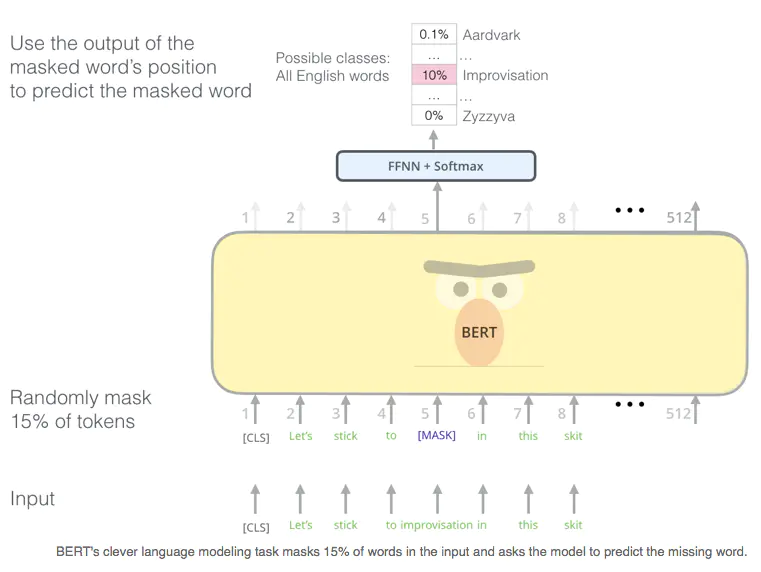
Masked LM.png
2.3 论文预训练方法 - Next Sentence Prediction
这个预训练方法就比较好直观的理解了,该预训练方法主要是为了增加模型对句子间关系的理解能力。因此作者设计了一种二分类预训练方法,让模型来判断,B句是不是A句的后面一句。其中,作者的样本集为平均分布,即一半是正确的,一半是错误的。最终,模型能达到97%-98%的准确率。关于该预训练方法的图解如下【1】。
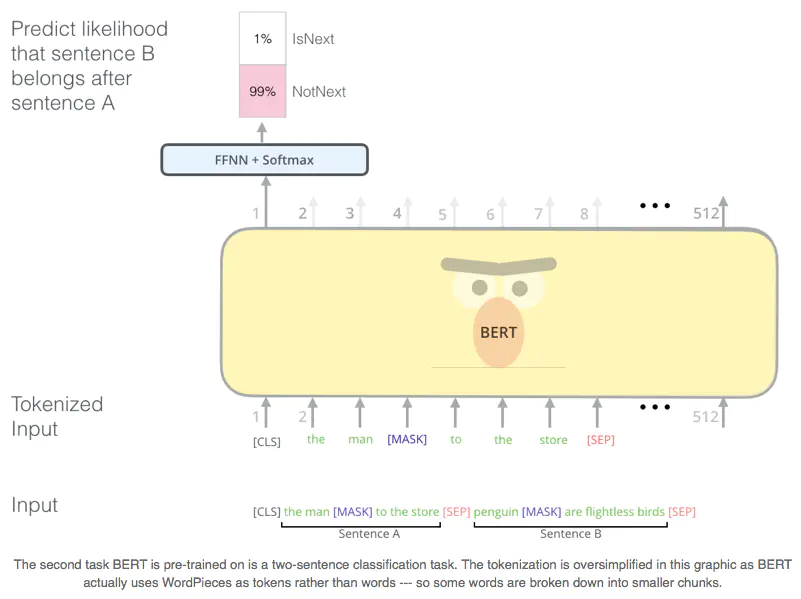
Next Sentence Prediction.png
2.4 论文预训练与微调的过程
与传统的LM模型训练过程相似,BERT的训练也遵循基本的套路(大家可参见ULMFiT,我的另一篇笔记也有详实的介绍)。作者强调了一下,训练数据集选取的一个关键,就是要选取基于文本的(document-level)而不仅仅是基于句子的(sentence-level),主要是为了让模型学会long contiguous sequences。接下来原论文中就提了一下预训练的细节,有兴趣的同学可以了解一下(大概很难复现?)。
2.5 论文实验结果分析
论文作者把自己提出的整套框架在各大NLP任务上实现了一遍,并且最后还对模型的训练过程做了一些实验对比,这里就不具体展现了。有兴趣的读者可以自行研读。值得一提的是,谷歌有开源的tensor2tensor,有空还是可以读一遍源码,或者工业界的小伙伴,可以学一波应用(资源允许的话)。
------------------第三菇 - 总结------------------
3.1 总结
到这里,整篇论文的核心思想及其创新点已经说清楚了。本论文主要集中在于阐述BERT的核心思想,并且解释了如何实现整一套BERT,附上了详实的对比实验,来验证模型的可行性。
作者:蘑菇轰炸机
链接:https://www.jianshu.com/p/4cb1f255cd7c
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
参考资料:https://jalammar.github.io/illustrated-bert/