【Python实例第15讲】分类概率图
机器学习训练营——机器学习爱好者的自由交流空间(入群联系qq:2279055353)
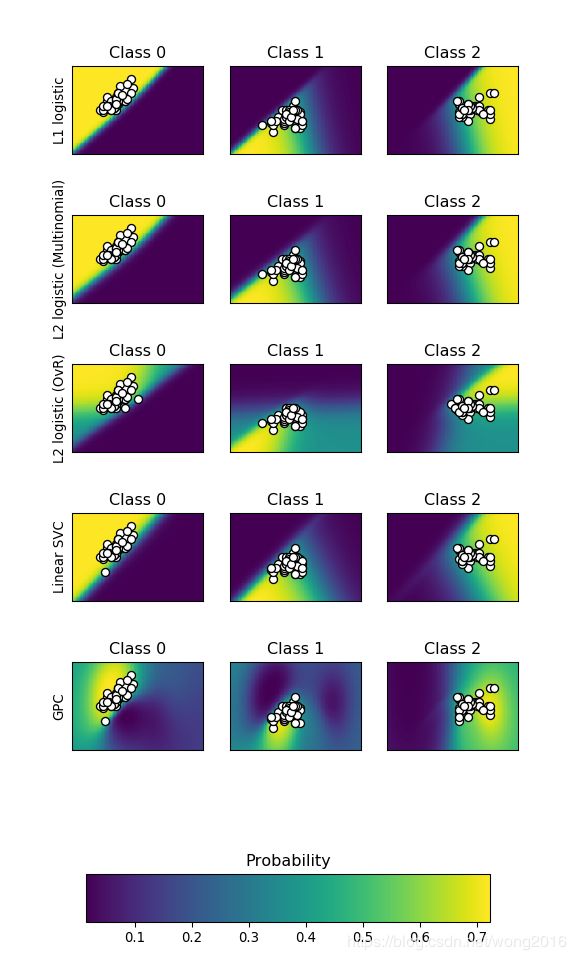
这个例子将用图形表示不同分类器的分类概率。所谓“分类概率”,是指某个数据点属于各个类别的概率。将所有数据点属于任何类的概率,用颜色深浅表示,作出分类概率图。
在这里,我们使用一个三类的数据集,分别用支持向量机(SVC)、L1 and L2惩罚的Logistic回归和高斯过程分类。默认情况下,线性SVC并不是一个概率分类器,但是可以通过设置参数probability=True改变。具有One v.s. Rest的Logistic回归并不是一个多类别分类器,因此,在分隔类2,类3时要比其它分类器复杂些。
实例详解
首先,导入必需的库。
print(__doc__)
# Author: Alexandre Gramfort
# License: BSD 3 clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn import datasets
本例使用的是鸢尾花数据集iris, 并且只用前2个特征作图。
iris = datasets.load_iris()
X = iris.data[:, 0:2] # we only take the first two features for visualization
y = iris.target
n_features = X.shape[1]
定义不同的分类器,它们是:
-
L1惩罚的Logistic回归
-
L2惩罚的多类Logistic回归
-
L2惩罚的二类Logistic回归
-
线性SVC
-
高斯过程分类GPC
C = 10
kernel = 1.0 * RBF([1.0, 1.0]) # for GPC
# Create different classifiers.
classifiers = {
'L1 logistic': LogisticRegression(C=C, penalty='l1',
solver='saga',
multi_class='multinomial',
max_iter=10000),
'L2 logistic (Multinomial)': LogisticRegression(C=C, penalty='l2',
solver='saga',
multi_class='multinomial',
max_iter=10000),
'L2 logistic (OvR)': LogisticRegression(C=C, penalty='l2',
solver='saga',
multi_class='ovr',
max_iter=10000),
'Linear SVC': SVC(kernel='linear', C=C, probability=True,
random_state=0),
'GPC': GaussianProcessClassifier(kernel)
}
n_classifiers = len(classifiers)
画出分类概率图。
plt.figure(figsize=(3 * 2, n_classifiers * 2))
plt.subplots_adjust(bottom=.2, top=.95)
xx = np.linspace(3, 9, 100)
yy = np.linspace(1, 5, 100).T
xx, yy = np.meshgrid(xx, yy)
Xfull = np.c_[xx.ravel(), yy.ravel()]
for index, (name, classifier) in enumerate(classifiers.items()):
classifier.fit(X, y)
y_pred = classifier.predict(X)
accuracy = accuracy_score(y, y_pred)
print("Accuracy (train) for %s: %0.1f%% " % (name, accuracy * 100))
# View probabilities:
probas = classifier.predict_proba(Xfull)
n_classes = np.unique(y_pred).size
for k in range(n_classes):
plt.subplot(n_classifiers, n_classes, index * n_classes + k + 1)
plt.title("Class %d" % k)
if k == 0:
plt.ylabel(name)
imshow_handle = plt.imshow(probas[:, k].reshape((100, 100)),
extent=(3, 9, 1, 5), origin='lower')
plt.xticks(())
plt.yticks(())
idx = (y_pred == k)
if idx.any():
plt.scatter(X[idx, 0], X[idx, 1], marker='o', c='w', edgecolor='k')
ax = plt.axes([0.15, 0.04, 0.7, 0.05])
plt.title("Probability")
plt.colorbar(imshow_handle, cax=ax, orientation='horizontal')
plt.show()

阅读更多精彩内容,请关注微信公众号:统计学习与大数据