MapReduce其他功能
序列化 – Writable
序列化/反序列化机制:当自定义了一个类之后,如果想要产生的对象在hadoop中进行传输,那么需要这个类实现Hadoop提供的Writable的接口只需要将按序写出并进行序列化/反序列化
Writable案例1:统计每一个人产生的总流量
文件:flow.txt
13877779999 bj zs 2145
13766668888 sh ls 1028
13766668888 sh ls 9987
13877779999 bj zs 5678
13544445555 sz ww 10577
13877779999 sh zs 2145
13766668888 sh ls 9987
pojo
public class Flow implements Writable{
private String phone;
private String city;
private String name;
private int flow;
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getCity() {
return city;
}
public void setCity(String city) {
this.city = city;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getFlow() {
return flow;
}
public void setFlow(int flow) {
this.flow = flow;
}
// 反序列化
@Override
public void readFields(DataInput in) throws IOException {
// 按照序列化的顺序一个一个将数据读取出来
this.phone = in.readUTF();
this.city = in.readUTF();
this.name = in.readUTF();
this.flow = in.readInt();
}
// 序列化
@Override
public void write(DataOutput out) throws IOException {
// 按照顺序将属性一个一个的写出即可
out.writeUTF(phone);
out.writeUTF(city);
out.writeUTF(name);
out.writeInt(flow);
}
}
Mapper
public class FlowMapper extends Mapper {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Flow f = new Flow();
f.setPhone(arr[0]);
f.setCity(arr[1]);
f.setName(arr[2]);
f.setFlow(Integer.parseInt(arr[3]));
context.write(new Text(f.getPhone()), f);
}
}
Reducer
public class FlowReducer extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
String name = null;
for (Flow val : values) {
name = val.getName();
sum += val.getFlow();
}
context.write(new Text(key.toString() + " " + name), new IntWritable(sum));
}
}
Driver
public class FlowDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.flow.FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://10.42.87.122:9000/mr/flow.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://10.42.87.122:9000/flowresult"));
if (!job.waitForCompletion(true))
return;
}
}
Writable案例2:统计每一个学生的总成绩
文本:score.txt(人名 语文 数学 英语)
Bob 90 64 92
Alex 64 63 68
Grace 57 86 24
Henry 39 79 78
Adair 88 82 64
Chad 66 74 37
Colin 64 86 74
Eden 71 85 43
Grover 99 86 43
pojo
public class Student implements Writable {
private String name;
private int chinese;
private int math;
private int english;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getChinese() {
return chinese;
}
public void setChinese(int chinese) {
this.chinese = chinese;
}
public int getMath() {
return math;
}
public void setMath(int math) {
this.math = math;
}
public int getEnglish() {
return english;
}
public void setEnglish(int english) {
this.english = english;
}
@Override
public void readFields(DataInput in) throws IOException {
this.name = in.readUTF();
this.chinese = in.readInt();
this.math = in.readInt();
this.english = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(name);
out.writeInt(chinese);
out.writeInt(math);
out.writeInt(english);
}
}
Mapper
public class SumScoreMapper extends Mapper {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Student s = new Student();
s.setName(arr[0]);
s.setChinese(Integer.parseInt(arr[1]));
s.setMath(Integer.parseInt(arr[2]));
s.setEnglish(Integer.parseInt(arr[3]));
context.write(new Text(s.getName()), s);
}
}
Reducer
public class SumScoreReducer extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Student val : values) {
sum += (val.getChinese() + val.getMath() + val.getEnglish());
}
context.write(key, new IntWritable(sum));
}
}
Driver
public class SumScoreDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.sumscore.SumScoreDriver.class);
job.setMapperClass(SumScoreMapper.class);
job.setReducerClass(SumScoreReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Student.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://10.42.87.122:9000/mr/score.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://10.42.87.122:9000/sumresult"));
if (!job.waitForCompletion(true))
return;
}
}
控制分区 – Partitioner
分区操作时shuffle操作中的一个重要过程,作用就是将map的结果按照规则分发到不同的reduce中进行处理,从而按照分区得到多个输出结果
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类,HashPartitioner是mapreduce的默认partitioner 计算方式是 : which reducer(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
**注 ?*默认情况下reduceTask数量为1
很多时候MR自带的分区规则并不能满足我们的需求,为了实现特定的效果,我们可以自己定义分区规则
分区 - Partitioner:默认是按照键的哈希码进行分区,但是实际使用过程中需要手动指定分区情况,就需要写一个类继承Partitioner来指定分区。— 每一个分区会对一个ReduceTask
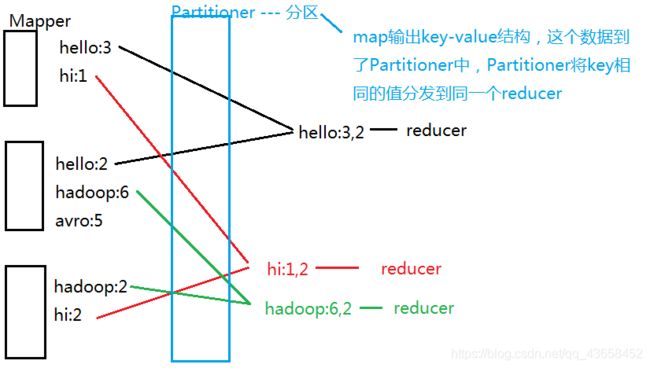
Partitioner案例1:按照不同城市统计每一个城市中每一个人产生的流量
文件: flow.txt(同上)
pojo(同上)
Partitioner
// 指定分区
public class FlowPartitioner extends Partitioner {
@Override
public int getPartition(Text key, Flow value, int numPartitions) {
String city = value.getCity();
if(city.equals("bj"))
return 0;
else if(city.equals("sh"))
return 1;
else
return 2;
}
}
Mapper
public class FlowMapper extends Mapper {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Flow f = new Flow();
f.setPhone(arr[0]);
f.setCity(arr[1]);
f.setName(arr[2]);
f.setFlow(Integer.parseInt(arr[3]));
context.write(new Text(f.getPhone()), f);
}
}
Reducer
public class FlowReducer extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Flow val : values) {
sum += val.getFlow();
}
context.write(key, new IntWritable(sum));
}
}
Driver
public class FlowDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.flow2.FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Flow.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定分区
job.setPartitionerClass(FlowPartitioner.class);
// 指定分区锁对应的reducer的额数量,只能大于 不能小于
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, new Path("hdfs://10.42.87.122:9000/mr/flow.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://10.42.87.122:9000/fpresult"));
if (!job.waitForCompletion(true))
return;
}
}
Partitioner案例2:按照月份求每一个同学在每一个月中的总分 - score1目录
文件
chinese.txt
1 zhang 89
2 zhang 73
3 zhang 67
1 wang 49
2 wang 83
3 wang 27
1 li 77
2 li 66
3 li 89
english.txt
1 zhang 55
2 zhang 69
3 zhang 75
1 wang 44
2 wang 64
3 wang 86
1 li 76
2 li 84
3 li 93
math.txt
1 zhang 85
2 zhang 59
3 zhang 95
1 wang 74
2 wang 67
3 wang 96
1 li 45
2 li 76
3 li 67
pojo
public class Student implements Writable {
private int month;
private String name;
private int score;
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public void readFields(DataInput in) throws IOException {
this.month = in.readInt();
this.name = in.readUTF();
this.score = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(month);
out.writeUTF(name);
out.writeInt(score);
}
}
Partitioner
public class ScorePatitioner extends Partitioner {
@Override
public int getPartition(Text key, Student value, int numPartitions) {
int month = value.getMonth();
return month - 1;
}
}
Mapper
ublic class ScoreMapper extends Mapper {
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(" ");
Student s = new Student();
s.setMonth(Integer.parseInt(arr[0]));
s.setName(arr[1]);
s.setScore(Integer.parseInt(arr[2]));
context.write(new Text(s.getName()), s);
}
}
Reducer
public class ScoreReducer extends Reducer {
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (Student val : values) {
sum += val.getScore();
}
context.write(key, new IntWritable(sum));
}
}
Driver
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(cn.tedu.score.ScoreDriver.class);
job.setMapperClass(ScoreMapper.class);
job.setReducerClass(ScoreReducer.class);
job.setPartitionerClass(ScorePatitioner.class);
job.setNumReduceTasks(3);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Student.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://10.42.87.122:9000/mr/score1"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://10.42.87.122:9000/scoreresult"));
if (!job.waitForCompletion(true))
return;
}
}
合并数据 – Combiner

Combiner实际上就是一个Reducer
Combiner - 合并。在Map任务结束后,会产生大量的数据,如果将这些数据直接交给reduce会增加reduce的任务量,所以可以先将map之后的数据进行一次合并,再交给reduce进行最后的规约
排序 – Comparable
排序 - 在Hadoop中, 在Map任务结束后,会按照键进行排序,如果需要手动指定排序规则,那么就需要对象对应的类实现Comparable接口
(待补充)