爬取B站直播流 - http+flv的相关研究
参考链接
- HTTP-FLV直播初探
- HTTP-FLV的两种方式
- Json将&符号转成了 \u0026
- python requests提示警告InsecureRequestWarning
爬取B站直播流
目录
1. 前言说明
2. 具体的分析
3. 爬取难点分析
4. 编程实现
5. 其它
6. 心得体会
一、前言说明 ↶
- 前言
这个小项目也立了有一段时间,最近捣鼓了一阵子,把上次遗留下来的问题算是解决。
本次博文的目标就是从B站直播间爬取B站的直播流,相当于将B站的直播录制成视频下载到本地硬盘上的过程,当然录制直播流也有很多的软件,比如 B站录播姬 。 但是,自己实现直播流的抓取也是很有意思的,培养一些解决问题的能力。 - 说明
本次博文写作形式,主要是依据自己爬取过程中,思考的流程,写下来的。简单地说,假设如何找到要爬的人是第一步,爬取视频到本地硬盘就是最后一步,而这里恰恰准备从如何爬取视频到本地硬盘,往前推如何找要爬的人。
二、具体的分析 ↶
第一步、找到爬取链接
-
随便找一个直播,打开 F12,点击 NetWork,刷新页面,加载时间最长的那个就是要抓取的链接

-
找到这个一直在加载的数据包

链接如下:
https://cn-zjhz2-cmcc-live-02.live-play.acgvideo.com/live-bvc/604475/live_3519797_5988404.flv?expires=1571389082&ssig=w2uQYxdOMz_13I31gT83zg&oi=2026667884&trid=49028817a2b2453281c3b0c0b73ead3b&pt=web&order=1&platform=web&pSession=mpEyCmnd-56GW-4E8y-1Ywj-DZ8S5HpYGX49 -
进一步分析这个链接
从链接中,可以得出这是一个 Flv 文件。从网上搜索资料查看,基本可以推测B站的直播形式大概是:HTTP+FLV 的方式。
补充说明:
业界常见的一种 HTTP 直播协议是将直播流式数据虚拟成为一个无限大的 FLV(FLASH VIDEO) 文件,并通过 HTTP 协议进行传输。客户端仅发送一次 HTTP GET 请求,请求中携带需要访问的直播流名,服务器返回 HTTP 响应,不携带消息体内容长度直接发送无限长 FLV 文件内容,或者使用 HTTP CHUNK 模式将无限长 FLV 文件按分段模式发送。客户端获得 HTTP 消息体中的 FLV 内容时即可播放。
emmm…
这不就是我们想要找到的原因,描述的跟B站的直播流传输一模一样,理论上下载这个flv文件,也是无限大的,除非 up 主下播。 -
简单验证一下,是否可以下载这个链接
① 浏览器尝试【需要更改头部】


② 简短的写一个程序
import requests
import sys
def download(url):
size = 0
chunk_size = 1024
response = requests.get(url, headers={'Referer': 'https://live.bilibili.com',}, stream=True, verify=False)
with open('None.flv', 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size += len(data)
file.flush()
sys.stdout.write(' [下载进度]:%.2fMB' % float(size /1024/1024 ) + '\r')
if __name__ == '__main__':
url = 'https://cn-zjhz2-cmcc-live-02.live-play.acgvideo.com/live-bvc/604475/live_3519797_5988404.flv?expires=1571389082&ssig=w2uQYxdOMz_13I31gT83zg&oi=2026667884&trid=49028817a2b2453281c3b0c0b73ead3b&pt=web&order=1&platform=web&pSession=mpEyCmnd-56GW-4E8y-1Ywj-DZ8S5HpYGX49'
download(url)
爬到的数据如下:
![]()
实际上,两种方式没什么差别,都要构造满足下载的条件,就是一些头部信息,如 User-Agent、Host、Referer等等。
总结,通过这个方式,实际上就求证了爬取的可行性,那么接下来的问题就到了如何获取链接的问题,因为,如果我们每个直播都需要这么整,也挺麻烦的。
第二步、获取 URL 链接
-
尝试在HTML代码中,搜查 URL 的踪迹

竟然如此顺利的获取到了flv的链接,不可思议。那么,我们的思路可以是:访问某个一个 UP 主的主播页面,获取HTML代码,匹配此文文本,提取 flv 链接,再用上面的方法就可以下载到 flv 直播流了。当然这个思路是可行的。 -
事实上,尝试的过程中还发现了一个特例
图没有截上,以后有机会补一张。页面中没有出现这样的匹配字样,而且链接的形式与一般的直播链接形式不一样,所以这就导致编写的程序可能会有特例出现,就是 BUG 的来源。
后续:
链接形式如:
在 HTML 代码中无法直接寻到想要的 flv 链接,因此要一劳永逸就不能采用这个办法了。 -
采取其它途径获取链接,搜索其它信息

找到一个有用的接口 api,可以返回我们想要的信息。【注意:经过我的总结和推测,如果 HTML 有嵌入链接,那么就不会有这个数据包,反过来,如果没有嵌入 HTML,那么可以抓到这个数据包,但是值得令人庆幸的一点,这个接口是通用的,无论什么直播间都能返回相应的链接】 -
查看具体返回内容

通过这种方式,我们成功地得到了下载的 URL,为了让我们更加方便的获取链接,我们还需要知道另一个参数,让我们看一下这个请求的链接:
https://api.live.bilibili.com/room/v1/Room/playUrl?cid=7734200&qn=0&platform=web
很明显,我们需要一个 cid 号,那么 cid 号怎么得到呢?让我们接着往下看。
第三步、获取拼接所需的 cid
这里省略一部分【比较麻烦的论述部分】,直接说结果吧:
事实上这里的 cid 就是房间号
https://live.bilibili.com/48267
大部分,链接中都有一串数字,如果把它拼接在下面这个链接中:
https://api.live.bilibili.com/room/v1/Room/playUrl?cid=+cid号+&qn=0&platform=web
拼接为:https://api.live.bilibili.com/room/v1/Room/playUrl?cid=48267&qn=0&platform=web
就会返回:
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"current_quality": 4,
"accept_quality": ["4", "3"],
"current_qn": 10000,
"quality_description": [{
"qn": 10000,
"desc": "原画"
}, {
"qn": 150,
"desc": "高清"
}],
"durl": [{
"url": "https://cn-zjjh2-cmcc-live-02.live-play.acgvideo.com/live-bvc/303336/live_9076081_6412632.flv?expires=1571405656\u0026ssig=Dp6fSPJ_La5jb1zF2ym7bA\u0026oi=2026667884\u0026trid=691b736ef3a64033b63ee183fc489cb9\u0026pt=web\u0026order=1",
"length": 0,
"order": 1,
"stream_type": 0
}, {
"url": "https://bvc.live-play.acgvideo.com/live-bvc/905820/live_9076081_6412632.flv?wsSecret=c1e4430ab9cc63d85c38585d560228ed\u0026wsTime=1571405656\u0026trid=691b736ef3a64033b63ee183fc489cb9\u0026pt=web\u0026oi=2026667884\u0026order=2\u0026sig=no",
"length": 0,
"order": 1,
"stream_type": 0
}, {
"url": "https://txy.live-play.acgvideo.com/live-txy/340458/live_9076081_6412632.flv?wsSecret=7cb979f741a517eb60c42241120b2e16\u0026wsTime=1571405656\u0026trid=691b736ef3a64033b63ee183fc489cb9\u0026pt=web\u0026oi=2026667884\u0026order=3\u0026sig=no",
"length": 0,
"order": 1,
"stream_type": 0
}, {
"url": "https://txy.live-play.acgvideo.com/live-txy/663379/live_9076081_6412632.flv?wsSecret=a322c8ecf638bb428da681a40fe77298\u0026wsTime=1571405656\u0026trid=691b736ef3a64033b63ee183fc489cb9\u0026pt=web\u0026oi=2026667884\u0026order=4\u0026sig=no",
"length": 0,
"order": 1,
"stream_type": 0
}]
}
}
里面就有我们所需要的链接。
第四步、关于房间号的获取问题
这里的问题主要是,有的房间号是 55# 这样的形式,实际上可能在程序中会有 bug,那么有什么方式可以方便的获取房间号呢?
事实上,答案藏在了用户空间【space】的页面中,也就是说这个房间号跟用户 uid 挂的上钩,因为你的 uid 肯定只能用你的自己直播房间。
因此,可以找到一个相对有用的接口:
https://api.live.bilibili.com/room/v1/Room/getRoomInfoOld?mid=+ mid号
经过测试,这里的 mid = uid。
举例:
uid号:9076081
mid号:9076081
拼接链接:https://api.live.bilibili.com/room/v1/Room/getRoomInfoOld?mid=9076081
访问可得到:
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"roomStatus": 1,
"roundStatus": 0,
"liveStatus": 1,
"url": "https://live.bilibili.com/48267",
"title": "魔兽RPG",
"cover": "http://i0.hdslb.com/bfs/live/room_cover/c558f1c1eceb78feafe42ab064734addebfa7a87.jpg",
"online": 19611,
"roomid": 48267,
"broadcast_type": 0,
"online_hidden": 0
}
}
里面的 roomid 就是此 uid 所代表的用户的直播间号,这样就可以拼接之前那个链接了。
在这一部分的最后,总结一下爬取的流程:
这里就以:哔哩哔哩英雄联盟赛事 为例子说明
账号名:哔哩哔哩英雄联盟赛事
uid:50329118
① 首先获取 roomId,拼接链接:
https://api.live.bilibili.com/room/v1/Room/getRoomInfoOld?mid=50329118
访问,得:
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"roomStatus": 1,
"roundStatus": 0,
"liveStatus": 1,
"url": "https://live.bilibili.com/7734200",
"title": "21:00 GRF vs C9 2019英雄联盟全球总决赛",
"cover": "http://i0.hdslb.com/bfs/vc/cd4e58b1c2a93ec687182bf888ccb3dc28c02cdf.jpg",
"online": 2679095,
"roomid": 7734200,
"broadcast_type": 0,
"online_hidden": 0
}
}
得到房间号:7734200
② 获取 url,拼接链接
https://api.live.bilibili.com/room/v1/Room/playUrl?cid=7734200&qn=0&platform=web
访问,得:
{
"code": 0,
"message": "0",
"ttl": 1,
"data": {
"current_quality": 4,
"accept_quality": ["4", "3", "2"],
"current_qn": 400,
"quality_description": [{
"qn": 10000,
"desc": "原画"
}, {
"qn": 400,
"desc": "蓝光"
}, {
"qn": 250,
"desc": "超清"
}, {
"qn": 150,
"desc": "高清"
}, {
"qn": 80,
"desc": "流畅"
}],
"durl": [{
"url": "https://cn-zjhz-cmcc-live-01.live-play.acgvideo.com/live-bvc/270476/live_7734200_bs_1348183_4000.flv?expires=1571406554\u0026ssig=dBx3JCa5-T0g68hxpX0ZYw\u0026oi=2026667884\u0026trid=88572cffe6674dbea4fe3591fbbd4522\u0026pt=web\u0026order=1",
"length": 0,
"order": 1,
"stream_type": 0
}, {
"url": "https://txy.live-play.acgvideo.com/live-txy/485051/live_7734200_bs_1348183_4000.flv?wsSecret=b07b8cacdaeea77a72728ed77e28ae5c\u0026wsTime=1571406554\u0026trid=88572cffe6674dbea4fe3591fbbd4522\u0026pt=web\u0026oi=2026667884\u0026order=2\u0026sig=no",
"length": 0,
"order": 1,
"stream_type": 0
}, {
"url": "https://bvc.live-play.acgvideo.com/live-bvc/913478/live_7734200_bs_1348183_4000.flv?wsSecret=5cfb156b8b3aba398b16f3f1ecd6e28f\u0026wsTime=1571406554\u0026trid=88572cffe6674dbea4fe3591fbbd4522\u0026pt=web\u0026oi=2026667884\u0026order=3\u0026sig=no",
"length": 0,
"order": 1,
"stream_type": 0
}, {
"url": "https://js.live-play.acgvideo.com/live-js/363279/live_7734200_bs_1348183_4000.flv?wsSecret=1f71efc02819502f3eed575a02450aab\u0026wsTime=1571406554\u0026trid=88572cffe6674dbea4fe3591fbbd4522\u0026pt=web\u0026oi=2026667884\u0026order=4\u0026sig=no",
"length": 0,
"order": 1,
"stream_type": 0
}]
}
}
得到,链接:
https://cn-zjhz-cmcc-live-01.live-play.acgvideo.com/live-bvc/270476/live_7734200_bs_1348183_4000.flv?expires=1571406554\u0026ssig=dBx3JCa5-T0g68hxpX0ZYw\u0026oi=2026667884\u0026trid=88572cffe6674dbea4fe3591fbbd4522\u0026pt=web\u0026order=1
【里面的 \u0026 相当于 &,Json 将它转化成 \u0026,有兴趣的可以查找相关资料。】
③ 可以此链接尝试下载
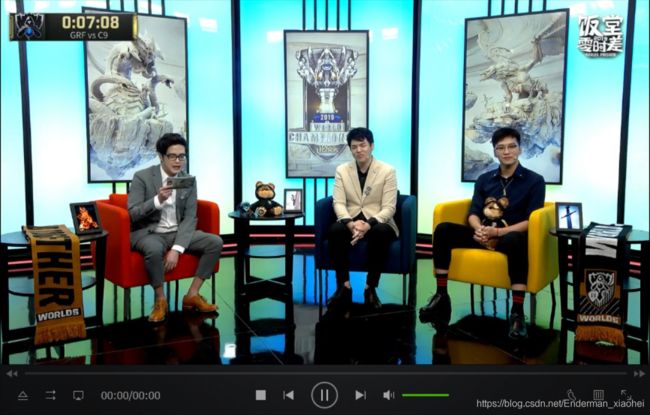
【但是,却没有出现进度条,不过,这个问题到后面再说】
三、爬取难点分析 ↶
关于爬取的难点,事实上最重要的有两点,我们已经解决了其中之一。
难点如下:
① 如何获取要爬取的 URL
② 如何定量爬取直播流【因为直播下载到本地是很大的,不可能一直等着下载直到直播结束(可有可能)】
关于定量爬取直播流:
① 对于浏览器这样直接下载,直接中断下载即可,缓存文件更改一个后缀名,就可以直接播放。
② 对于编写程序方面,需要控制一个变量,如果超过这个值,就停止存储直播数据。
虽然这样想很简单,但是这是困住我一阵子的一个问题,因为我当时并不清楚直播数据中断也可以播放的事实,因为特殊的文档数据若是下载一般可不能打开,但是这些视频格式的文件却可以,还是懂的不多,要多多尝试。
四、编程实现 ↶
下面的代码是基于 Python 3
前面也说了很多【废话也很多,(*^▽^*)】,就直接贴代码了【理论上应该没有 bug】:
import requests
import re, json
import sys
#from requests.packages.urllib3.exceptions import InsecureRequestWarning
#requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
# 取消注释可以去掉出现的警告
class LiveVideoDownload(object):
def __init__(self, up_id, size=10, filename='None.flv'):
self.up_id = up_id
self.size_all = size
self.filename = filename
self.roomIdRegex = r'"//live\.bilibili\.com/{.*?}"'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'}
def getRoomId(self):
url = 'https://api.live.bilibili.com/room/v1/Room/getRoomInfoOld?mid={}'.format(self.up_id)
self.Referer = 'https://space.bilibili.com/{}/'.format(self.up_id)
self.headers['Host'] = 'api.live.bilibili.com'
self.headers['Referer'] = self.Referer
response = requests.get(url=url, headers=self.headers).json()
room_id = response['data']['roomid']
return room_id
def getJsonFile(self, room_id):
url = 'https://api.live.bilibili.com/room/v1/Room/playUrl?cid={}'.format(room_id)
content = requests.get(url=url, headers=self.headers).text
return content
def extract(self):
room_id = self.getRoomId()
data = self.getJsonFile(room_id)
data_json = json.loads(data)
download_url = data_json['data']['durl'][0]['url']
host = download_url[8:].split('/')[0]
return download_url, host
def download(self):
content = self.extract()
url, host = content
headers = self.headers
headers['host'] = host
headers['referer'] = self.Referer
# 下载
size = 0
chunk_size = 1024
response = requests.get(url, headers=headers, stream=True, verify=False)
with open(self.filename, 'wb') as file:
for data in response.iter_content(chunk_size = chunk_size):
file.write(data)
size += len(data)
file.flush()
if self.size_all > 0:
sys.stdout.write(' [下载进度]:%.2fMB/%.2fMB' % (float(size/10/ (self.size_all*1024*1024) * 100), self.size_all) + '\r')
if size > self.size_all*1024*1024:
break
else:
sys.stdout.write(' [下载进度]:%.2fMB' % float(size/1024/1024) + '\r')
print('下载完成')
if __name__ == '__main__':
up_id = '50329118' # uid 号
size_MB = 20 # size_MB=0 无限制下载,size_MB >0, 下载量为 [size_MB] MB
filename = 'xxx.flv' #下载文件名
liveVideo = LiveVideoDownload(up_id=up_id,
size=size_MB,
filename=filename)
liveVideo.download()
实现的过程,基本上就是之前那些分析的过程,不过使用代码实现了对B站直播流的下载。
五、其它 ↶
还记得上面说的,视频显示问题,确实我也没有找到一个直接的方法或者原因去解释这个问题。但是,我想了一个曲线救国的方式,我想尝试用格式工厂转换它的格式,比如说转换为 mp4,看看会不会变为正常显示的情况。那就开整吧!
转换前:

- 打开格式工厂【右键】
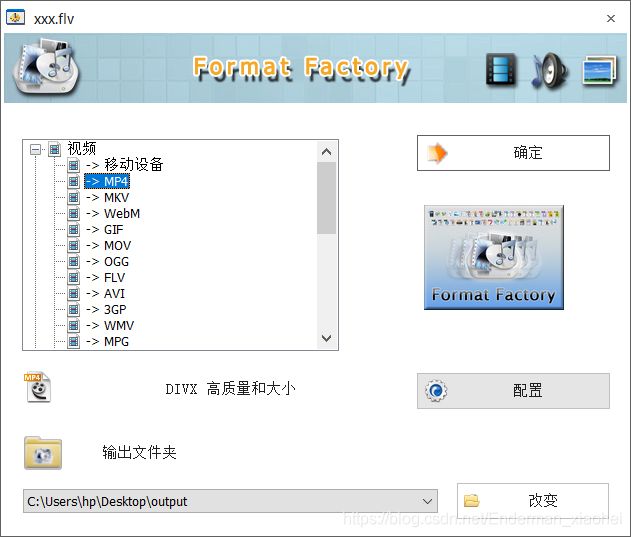
- 点击开始

- 得到 mp4 文件

转换后:

可以看到下面出现了时间。
六、心得体会 ↶
比较仔细的写了如何爬取B站的直播流,工具的熟练使用还是很重要的。最后,吐槽一下,写这样的博文还是很累的,不过也是积累的一种方式吧。要坚持~!(´・ω・)ノ(._.`)
点我回顶部 ☚
Fin.