运筹系列45:连续优化问题的python代码
Optimization algorithms is very similar to root finding algorithms. The general structure goes something like: a) start with an initial guess, b) calculate the result of the guess, c) update the guess based on the result and some further conditions, d) repeat until you’re satisfied with the result.
The difference is: root finding algorithms stops when variable f ( x ) f(x) f(x) converges to 0, whereas optimization algorithms stops when ∇ f ( x ) \nabla f(x) ∇f(x) converges to 0.
1 Basic funtion
It is import to get the derivate value in continuous optimization problems. We can get it by approximate method:
# calculate derivation
from scipy.optimize import *
f = lambda x: x[0]**2+x[1]**2 - 20
approx_fprime([3,2],f,0.0001)
Or we can calculate the value directly if we know the explicit form.
2 Gradinet descent
GD algorithm use f ( x ) = f ( x n ) + ( x − x n ) ∇ f ( x n ) f(x) = f(x_n)+(x-x_n)\nabla f(x_n) f(x)=f(xn)+(x−xn)∇f(xn) to find the direction to move for optimization, and move a certain step.
def GD(f, x, delta = 0.1,tol=.0001):
print(str(x)+":"+str(f(x)))
xn = x - delta * approx_fprime(x,f,0.0001)
if abs(f(x)-f(xn))> tol:
GD(f,xn,delta,tol)
f = lambda x: np.sum((x-2)**2) + 20
GD(f, np.array([1,2]))
In the above example, we know f ( x ) f(x) f(x), but not f ′ ( x ) f'(x) f′(x). In some cases, we know the derivative function f ′ ( x ) f'(x) f′(x). In this case, we can replace approx_fprime ( x , f , 0.0001 ) (x,f,0.0001) (x,f,0.0001) by f ′ ( x ) f'(x) f′(x).
x_iters = []
def f(x):
return (x[0]-2)**2+(x[1]-2)**2+20
fd = lambda x: (x-2) * 2
def GD1(f, fd, x, delta = 0.01,tol=.0001):
x_iters.append(x.reshape([len(x),1]))
xn = x - delta * fd(x)
if abs(f(x)-f(xn))> tol:
GD1(f,fd,xn,delta,tol)
GD1(f,fd,np.array([1,2]))
3. Least square problem and pytorch
In deep learning, we use very simple functions to fit the real relationship. For example, we assume that fs(x) = t[0] * x[0] + t[1] * x[1] + t[2] * x[2] + …, and we have several samples [x1,y1],[x2,y2],…
The loss function is Loss = ( f s ( x 1 ) − y 1 ) 2 + ( f s ( x 2 ) − y 2 ) 2 + . . . (fs(x1)-y1)^2+(fs(x2)-y2)^2+... (fs(x1)−y1)2+(fs(x2)−y2)2+...
Then L o s s ′ ∣ t [ 0 ] Loss'|_{t[0]} Loss′∣t[0] = 2 ∗ ( f s ( x 1 ) − y 1 ) ∗ x 1 [ 0 ] + 2 ∗ ( f s ( x 1 ) − y 2 ) ∗ x 2 [ 0 ] + . . . 2*(fs(x1)-y1)*x1[0]+2*(fs(x1)-y2)*x2[0]+... 2∗(fs(x1)−y1)∗x1[0]+2∗(fs(x1)−y2)∗x2[0]+...
L o s s ′ ∣ t [ 1 ] Loss'|_{t[1]} Loss′∣t[1] = 2 ∗ ( f s ( x 1 ) − y 1 ) ∗ x 1 [ 1 ] + 2 ∗ ( f s ( x 2 ) − y 2 ) ∗ x 2 [ 1 ] + . . . 2*(fs(x1)-y1)*x1[1]+2*(fs(x2)-y2)*x2[1]+... 2∗(fs(x1)−y1)∗x1[1]+2∗(fs(x2)−y2)∗x2[1]+...
…
In short, we should minimize Loss function with LossD= 2 ∗ ( f s ( x 1 ) − y 1 ) ∗ x 1 + 2 ∗ ( f s ( x 2 ) − y 2 ) ∗ x 2 + . . . 2*(fs(x1)-y1)*x1+2*(fs(x2)-y2)*x2+... 2∗(fs(x1)−y1)∗x1+2∗(fs(x2)−y2)∗x2+..., that means LossD should converges to 0 by gradient algorithm.
def Loss(t):
return np.sum((np.sum(t*X,axis = 1) - Y) **2)
def LossD(t):
return np.sum(2 * (np.sum(t*X,axis = 1) - Y).reshape([len(X),1]) * X, axis = 0)
t = np.array([8,8,8])
X = np.array([[3,4,3],[8,1,4],[4,2,3],[5,7,9]])
Y = np.array([101,185,109,206])
GD1(Loss,LossD,t,delta = 0.001,tol=.01) # The true value is [18,5,9]
We can use pytorch to help us calculate the derivate value automatically
import torch
t = torch.tensor([8., 8, 8], requires_grad=True)
Y = torch.tensor([101.,185,109,206])
X = torch.tensor([[3.,4,3],[8,1,4],[4,2,3],[5,7,9]])
def GD2(t, delta = torch.scalar_tensor(0.001),tol=torch.scalar_tensor(.01)):
Loss = sum(([email protected])**2)
Loss.backward()
while Loss.data > tol:
print(t.data,Loss.data)
t = (t - delta * t.grad).data
t.requires_grad=True
Loss = sum(([email protected])**2)
Loss.backward()
GD2(t) # The true value is [18,5,9]
Furthermore, we can use the optimizer provided by pytorch. Since pytorch optimizer do not provide full batch gradient descent method, we use SGD optimizer.
from torch.nn import Parameter
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.t = Parameter(torch.Tensor(3, 1))
self.t.data = torch.tensor([8., 8, 8])
def forward(self, x):
out = [email protected]
return out
model = LinearRegression()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=1e-3)
out = model(X)
loss = criterion(out, Y)
while loss > 0.01:
out = model(X)
loss = criterion(out, Y)
print(model.t.data,loss.data*len(Y))
optimizer.zero_grad()
loss.backward()
optimizer.step()
4. Momentum algorithm
In some cases, Gradinet descent is very slow to converge, or even worse, not converge. We may adopt momentum algorithm and give it a try. for example:
f =lambda x:(x[0]-2)**2 + abs(x[1])
4.1 naive momentum
def MOMENTUM(f,x,lr=0.1,discount=0.3,tol=0.001):
g = approx_fprime(x,f,0.0001)
pre_g = g
xn = x - lr * g
while abs(f(x)-f(xn))>tol:
x = xn
pre_g = lr * approx_fprime(x,f,0.0001) - discount* pre_g
xn = x - pre_g
print(str(xn)+":"+str(f(xn)))
MOMENTUM(f,[1,1])
4.2 Nesterov
def NESTEROV(f,x,lr=0.01,discount=0.1,tol=0.01):
g = approx_fprime(x,f,0.00001)
pre_g = g
xn = x - lr * g
while abs(f(x)-f(xn))>tol:
x = xn
xf = x - pre_g * discount * lr
pre_g = approx_fprime(xf,f,0.0001) + discount * pre_g
xn = x - pre_g * lr
print(str(xn)+":"+str(f(xn)))
NESTEROV(f,[1,1])
5. Newton method
If we know the second derivate value of f f f, we can use newton method.
It is computationally huge to get the Hessian Matrix, and we usually use approximate method to calculate it.
Assume the loss function is Loss = ( t @ x 1 − y 1 ) 2 + ( t @ x 2 − y 2 ) 2 + . . . (t@x1-y1)^2+(t@x2-y2)^2+... (t@x1−y1)2+(t@x2−y2)2+...
Then L o s s ′ ′ ∣ t [ i ] , t [ j ] Loss''|_{t[i],t[j]} Loss′′∣t[i],t[j] = 2 ∗ x 1 [ i ] ∗ x 1 [ j ] + 2 ∗ x 2 [ i ] ∗ x 2 [ j ] + . . . = 2 ∗ x . T @ x 2*x1[i]*x1[j]+2*x2[i]*x2[j]+...=2*x.T@x 2∗x1[i]∗x1[j]+2∗x2[i]∗x2[j]+...=2∗x.T@x
…
In short, we should minimize Loss function with LossD= 2 ∗ ( f s ( x 1 ) − y 1 ) ∗ x 1 + 2 ∗ ( f s ( x 2 ) − y 2 ) ∗ x 2 + . . . 2*(fs(x1)-y1)*x1+2*(fs(x2)-y2)*x2+... 2∗(fs(x1)−y1)∗x1+2∗(fs(x2)−y2)∗x2+..., that means LossD should converges to 0 by gradient algorithm.
t = np.array([8,8,8])
X = np.array([[3,4,3],[8,1,4],[4,2,3],[5,7,9]])
Y = np.array([101,185,109,206])
def Loss(t):
#return np.sum((np.sum(t*X,axis = 1) - Y) **2)
A = [email protected]
return [email protected]
def LossD(t):
#return np.sum(2 * (np.sum(t*X,axis = 1) - Y).reshape([len(X),1]) * X, axis = 0)
return 2*([email protected])@X
def LossHInv(t):
return np.linalg.inv(2*X.T@X)
t-LossHInv(t)@LossD(t) # One step to optimal solution
We can also use pytorch to help calculate the Hessian values:
import torch
t = torch.tensor([8., 8, 8], requires_grad=True)
X = torch.tensor([[3.,4,3],[8,1,4],[4,2,3],[5,7,9]])
Y = torch.tensor([101,185,109,206])
loss = sum(([email protected] - Y)**2)
grad = torch.autograd.grad(loss, t, retain_graph=True, create_graph=True)
Print = torch.tensor([])
for anygrad in grad[0]: # torch.autograd.grad返回的是元组
Print = torch.cat((Print, torch.autograd.grad(anygrad, t, retain_graph=True)[0]))
t.data - torch.inverse(Print.view(t.size()[0], -1))@grad[0].data
6. Quasi-Newton Method
6.1 basic test
Let’s start with a simple problem:
f ( x ) = x 1 2 + x 2 4 + x 1 x 2 f(x) = x_1^2 + x_2^4 + x_1 x_2 f(x)=x12+x24+x1x2
The plot is as below:
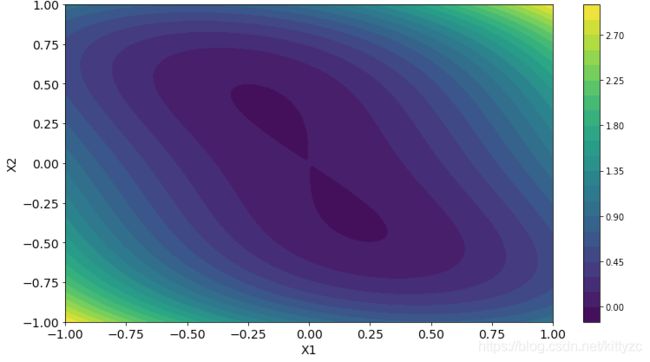
Let’s use gradient descent method as a test. The funtion below is similar to GD1 before. We add some new features like line search and verbose.
def gradient_descent(f, grad, x_0, alpha=0.1, verbose=0, steepest=0):
x_curr = x_0
x_iters = [x_curr]
for i in range(1, n_iters):
g = grad(x_curr)
if verbose: print('Iteration:%d\nCurrent x:%.5f\nGradient: %.5f'%(i,x_curr,g))
if steepest:
best_alpha = alpha_search(f, x_curr, g)
alpha = best_alpha
x_new = x_curr - alpha * g
if verbose: print('New x: ', x_new, '\n')
x_iters.append(x_new)
x_curr = x_new
return np.array(x_iters)
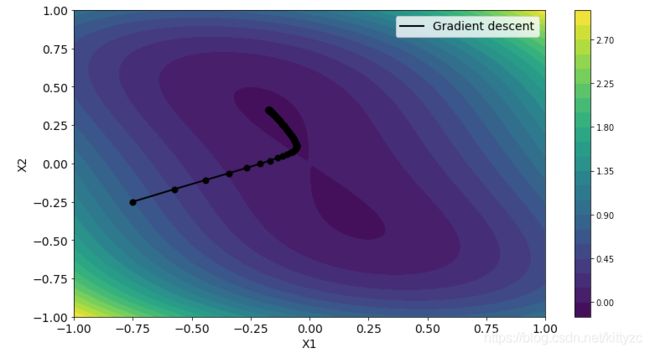
6.2 SR1 method
And then we test a SR1 quasi-Newton method.
We use H k H_k Hk to approximate G k − 1 G_k^{-1} Gk−1(Or B k B_k Bk to approximate G k G_k Gk).
Assume that H k + 1 = H k + β u u T H_{k+1}=H_k+\beta uu^T Hk+1=Hk+βuuT, we get Δ H = ( Δ x − H Δ g ) ( Δ x − H Δ g ) T ( Δ x − H Δ g ) Δ g \Delta H=\frac{(\Delta x-H\Delta g)(\Delta x-H\Delta g)^T}{(\Delta x-H\Delta g)\Delta g} ΔH=(Δx−HΔg)Δg(Δx−HΔg)(Δx−HΔg)T。
I don’t know why people used to assign s s s for Δ x \Delta x Δx and y y y for Δ g r a d ( x ) \Delta grad(x) Δgrad(x), but remember that in the following function, s and y stands for Δ x \Delta x Δx and Δ g \Delta g Δg in the formulation.
def sr1(f, grad, x_0, alpha=0.1, verbose=0, steepest=1):
# Starts from I
B_curr = np.identity(len(x_0))
H_curr = np.linalg.inv(B_curr)
x_curr = x_0
x_new = x_curr - alpha * grad(x_curr)
s_curr = x_new - x_curr
y_curr = grad(x_new) - grad(x_curr)
x_iters_sr1 = [x_0]
for i in range(1, n_iters):
if verbose: print('Iteration: ', i)
if verbose: print ('Current x: ', x_curr)
g = grad(x_curr)
p = H_curr.dot(g)
if steepest: alpha = alpha_search(f, x_curr, p)
x_new = x_curr - alpha * p
if verbose: print('New x: ', x_new, '\n')
s_new = x_new - x_curr
y_new = grad(x_new) - grad(x_curr)
s_curr = s_new
y_curr = y_new
# This is the essential of SR1 algorithm.
b = y_curr - B_curr.dot(s_curr)
B_new = B_curr + b.dot(b.T) / (b.T.dot(s_curr) + 10**-8)
a = s_curr - H_curr.dot(y_curr)
H_new = H_curr + a.dot(a.T) / (a.T.dot(y_curr) + 10**-8)
r = 10**-8
# sB>r*sqrt(ssBB)
if s_curr.T.dot(b) > r * np.sqrt(s_curr.T.dot(s_curr) * b.T.dot(b)):
if verbose: print('Update')
H_curr = H_new
B_curr = B_new
x_iters_sr1.append(x_new)
x_curr = x_new
return np.array(x_iters_sr1)
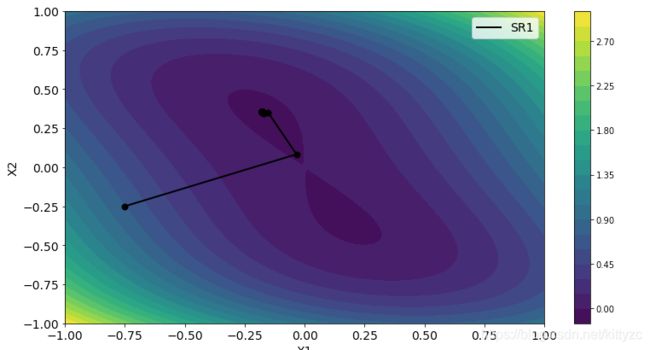
6.3 SR2: DFP and BFGS
SR2 quasi-newton method has two forms:
Let s = Δ x s=\Delta x s=Δx and y = Δ g y = \Delta g y=Δg
(0) Sherman-Morrison equation: ( A + u v T ) − 1 = A − 1 − A − 1 u v T A − 1 1 + v T A − 1 u (A+uv^T)^{-1}=A^{-1}-\frac{A^{-1}uv^TA^{-1}}{1+v^TA^{-1}u} (A+uvT)−1=A−1−1+vTA−1uA−1uvTA−1
(1) Assume that H k + 1 = H k + β u u T + γ v v T H_{k+1}=H_k+\beta uu^T+\gamma vv^T Hk+1=Hk+βuuT+γvvT, which is DFP, Δ H = s s T s T y − H y y T k H y T H y \Delta H=\frac{ss^T}{s^Ty}−\frac{Hyy^TkH}{y^THy} ΔH=sTyssT−yTHyHyyTkH
(2) Assume that B k + 1 = B k + β u u T + γ v v T B_{k+1}=B_k+\beta uu^T+\gamma vv^T Bk+1=Bk+βuuT+γvvT, which is BFGS, and we have Δ B = y y T y T s − B s s T B s T B s \Delta B=\frac{y y^T}{y^Ts}-\frac{Bss^TB}{s^TBs} ΔB=yTsyyT−sTBsBssTB. Using Sherman-Morrison equation 2 times, we have B ′ − 1 = s s T y T s + ( I − s y T y T s ) B − 1 ( I − y s T y T s ) B'^{-1}=\frac{s s^T}{y^Ts}+(I-\frac{sy^T}{y^Ts})B^{-1}(I-\frac{ys^T}{y^Ts}) B′−1=yTsssT+(I−yTssyT)B−1(I−yTsysT).
We can also combine DFP and BFGS with a certain ratio, and is called Broyden Formulation.
def dfp(f, grad, x_0, alpha=0.1, verbose=0, steepest=1):
B= np.identity(len(x_0))
x_curr = x_0
x_new = x_curr - alpha * grad(x_curr)
s_curr = x_new - x_curr
y_curr = grad(x_new) - grad(x_curr)
x_iters_dfp = [x_0]
for i in range(1, n_iters):
if verbose: print('Iteration: ', i)
if verbose: print ('Current x: ', x_curr)
g = grad(x_curr)
p = B.dot(g)
if steepest: alpha = alpha_search(f, x_curr, p)
x_new = x_curr - alpha * p
if verbose: print('New x: ', x_new, '\n')
s_new = x_new - x_curr
y_new = grad(x_new) - grad(x_curr)
s_curr = s_new
y_curr = y_new
bs = B.dot(s_curr)
B += s_curr.dot(s_curr.T) / (y_curr.T.dot(s_curr) + 10**-8)\
- bs.dot(s_curr.T).dot(B)/ (s_curr.T.dot(bs)+ 10**-8)
x_iters_dfp.append(x_new)
x_curr = x_new
return np.array(x_iters_dfp)

def bfgs(f, grad, x_0, alpha=0.1, verbose=0, steepest=1):
B_curr = np.identity(len(x_0))
x_curr = x_0
x_new = x_curr - alpha * grad(x_curr)
s_curr = x_new - x_curr
y_curr = grad(x_new) - grad(x_curr)
x_iters_bfgs = [x_0]
for i in range(1, n_iters):
if verbose: print('Iteration: ', i)
if verbose: print ('Current x: ', x_curr)
g = grad(x_curr)
p = B_curr.dot(g)
if steepest: alpha = alpha_search(f, x_curr, p)
x_new = x_curr - alpha * p
if verbose: print('New x: ', x_new, '\n')
s_new = x_new - x_curr
y_new = grad(x_new) - grad(x_curr)
s_curr = s_new
y_curr = y_new
pho = 1. / (y_curr.T.dot(s_curr) + 10**-8)
a = np.identity(len(x_0)) - pho * s_curr.dot(y_curr.T)
b = np.identity(len(x_0)) - pho * y_curr.dot(s_curr.T)
B_new = a.dot( B_curr.dot(b) ) + pho * s_curr.dot(s_curr.T)
B_curr = B_new
x_iters_bfgs.append(x_new)
x_curr = x_new
return np.array(x_iters_bfgs)

6.4 L-BFGS
L-BFGS is one particular optimization algorithm in the family of quasi-Newton methods that approximates the BFGS algorithm using limited memory. Whereas BFGS requires storing a dense matrix, L-BFGS only requires storing 5-20 vectors to approximate the matrix implicitly and constructs the matrix-vector product on-the-fly via a two-loop recursion.
In the deterministic or full-batch setting, L-BFGS constructs an approximation to the Hessian by collecting curvature pairs ( s k , y k s_k, y_k sk,yk) defined by differences in consecutive gradients and iterates, i.e. s k = x k + 1 − x k s_k = x_{k + 1} - x_k sk=xk+1−xk and y k = ∇ F ( x k + 1 ) − ∇ F ( x k ) y_k = \nabla F(x_{k + 1}) - \nabla F(x_k) yk=∇F(xk+1)−∇F(xk) . In our implementation, the curvature pairs are updated after an optimization step is taken (which yields x k + 1 x_{k + 1} xk+1).
The updating equation is:
B − 1 = V T B − 1 V + ρ s s T B^{-1}=V^TB^{-1}V+ \rho ss^T B−1=VTB−1V+ρssT, where ρ = 1 / ( y T s ) \rho = 1/(y^Ts) ρ=1/(yTs), V = I − ρ y s T V=I-\rho ys^T V=I−ρysT
We only keep track of y and s, not B. We have the following result:
B i + 1 − 1 = ( V i T . . . V i − m T ) B i − m − 1 ( V i − m T . . . V i T ) + ρ i − m ( V i − 1 T . . . V i − m T ) s i − m s i − m T ( V i − m T . . . V i − 1 T ) + . . . + ρ i s i s i T B^{-1}_{i+1} = (V^T_i...V^T_{i-m})B^{-1}_{i-m}(V^T_{i-m}...V^T_{i})+\rho_{i-m}(V^T_{i-1}...V^T_{i-m})s_{i-m}s^T_{i-m}(V^T_{i-m}...V^T_{i-1})+...+\rho_is_is^T_{i} Bi+1−1=(ViT...Vi−mT)Bi−m−1(Vi−mT...ViT)+ρi−m(Vi−1T...Vi−mT)si−msi−mT(Vi−mT...Vi−1T)+...+ρisisiT
def lbfgs(f, grad, x_0, alpha=0.1, verbose=0, steepest=1,m=20,error = 1e-5):
B= np.identity(len(x_0))
xk = x_0.reshape(len(x_0))
I = np.identity(xk.size)
Hk = I
sks = []
yks = []
x_iters_lbfgs = [x_0]
def Hp(H0, p):
m_t = len(sks)
q = grad(xk)
a = np.zeros(m_t)
b = np.zeros(m_t)
for i in reversed(range(m_t)):
s = sks[i]
y = yks[i]
rho_i = float(1.0 / y.T.dot(s))
a[i] = rho_i * s.dot(q)
q = q - a[i] * y
r = H0.dot(q)
for i in range(m_t):
s = sks[i]
y = yks[i]
rho_i = float(1.0 / y.T.dot(s))
b[i] = rho_i * y.dot(r)
r = r + s * (a[i] - b[i])
return r
for i in range(1, n_iters):
if verbose: print('Iteration: ', i)
if verbose: print ('Current x: ', xk)
gk = grad(xk)
pk = -Hp(I, gk)
if steepest: alpha = alpha_search(f, xk, pk)
# update x
xk1 = xk - alpha * pk
gk1 = grad(xk1)
# define sk and yk for convenience
sk = xk1 - xk
yk = gk1 - gk
sks.append(sk)
yks.append(yk)
if len(sks) > m:
sks = sks[1:]
yks = yks[1:]
# compute H_{k+1} by BFGS update
rho_k = float(1.0 / yk.dot(sk))
if verbose: print('New x: ', xk, '\n')
if np.linalg.norm(xk1 - xk) < error:
xk = xk1
break
x_iters_lbfgs.append(xk1.reshape([len(xk1),1]))
xk = xk1
return np.array(x_iters_lbfgs)
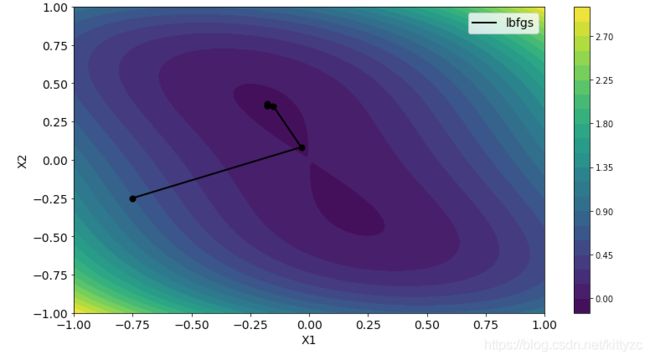
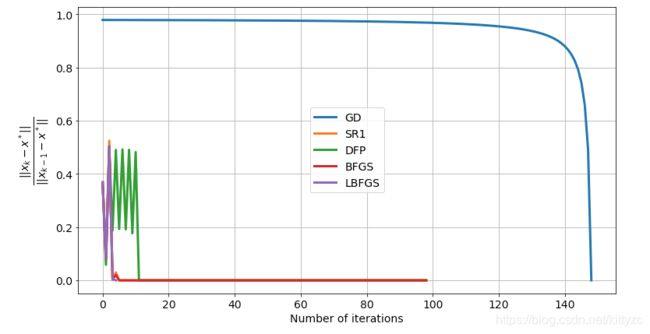
7. Comparison