数据结构与算法上机实验七 查找
实验七 查找
- 折半查找(二分法)
- 哈希表的插入和查找
本次继续更新数据结构与算法这门课的上机实验,并且从本次开始将持续更新三篇关于排序和查找的内容——最根本的操作,主要涉及折半查找和哈希表查找。
特此感谢, 实验过程中邓老师的指导和帮助!
对于想要获取此实验报告和源代码的同学,欢迎光顾小生寒舍 GitHub:https://github.com/ChromeWei?tab=repositories
实验内容
一、编写函数实现折半查找。
二、实现一个最简单的哈希表的插入和查找。
备注:鉴于方便大家对折半查找的理解,我查找了很多相关CSDN平台上也没有写得较为细致的博文,所以我打算将我之前学习时用的平台推荐给大家GeeksforGeeks;对于哈希表的插入和查找我推荐一个博客的讲解,连接在下面。(小生先谢过作者,如涉及侵权,亲联系我即删 )
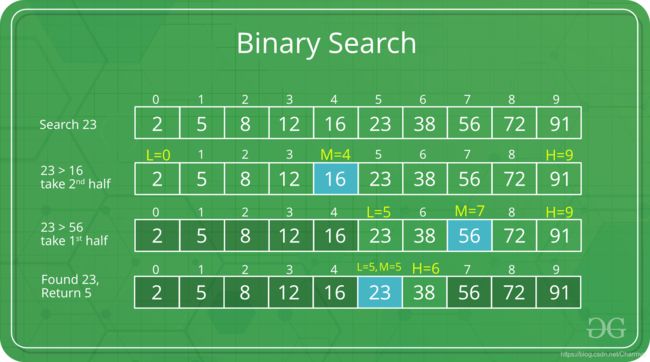
折半查找(二分法)
- 折半查找https://blog.csdn.net/weixin_44321600/article/details/86671672.
- Binary Search https://www.geeksforgeeks.org/binary-search/.
- [C语言] 选择排序之直接选择排序的特性及实现https://www.cnblogs.com/usingnamespace-caoliu/p/9428115.html.
哈希表的插入和查找
本算法中采用的构造哈希表的方法有:
- 构造哈希函数的方法:【除留余数法】
H(key) = key MOD p (p ≤ m),其中m为表长,本算法中取p=m;(一般情况下,可选p为质数或不包含小于20的质因数的合数) - 处理冲突的方法:【开放定址法】
Hi = (H(key) + di) MOD m, i=1,2,3,…,k(k <= m - 1),其中di为增量序列,可有下列三种取法:
(1) 线性探索再散列:di = 1,2,3,…,m-1
(2) 二次探索再散列:di = 1,-12,2,-22,…,±k^2(k <= m - 1)
(3) 伪随机探索再散列:di = 伪随机数序列
引用自:哈希表查找C实现(详细注释)http://blog.csdn.net/shengwusuoxi/article/details/8148460.
本篇重点: 但是最为推荐的是GeeksforGeeks官网链接这个平台 ,不止有较为详尽的算法介绍,图文都会比较直观,掌握数据结构和算法等知识足够!!
,不止有较为详尽的算法介绍,图文都会比较直观,掌握数据结构和算法等知识足够!!
链接:https://www.geeksforgeeks.org/sorting-algorithms/.

附件: 源代码
(测试环境:Win10, VisualC++ 6.0)
折半查找(二分法)
#include 哈希表查找
#include Records.txt
12 23 43 23 32 5 31 56 78 34 8 45 63 55 30
上一篇:数据结构与算法上机实验六 排序(二)
下一篇:数据结构与算法上机实验专栏
欢迎各位订阅我,谢谢大家的点赞和专注!我会继续给大家分享我大学期间详细的实践项目。