python2.7爬取大众点评 模拟鼠标 python第二天含源码
*第二天是指写博客的第二天
创作背景
对于新手来说最快的学习方法就是看项目,在百度搜索python爬虫基本都是爬大众点评的,不知道这个网站做错了什么被这么多人爬。接下来博主兴冲冲的找了几个有代码的博客,改了改就测试,但是结果无非就是网站不能正常访问啊,需要拖动验证之类的,还有的就是只有头尾两部分,总之没有看到想要的结果,看来大众点评这几年也在反爬虫上下了功夫。但是博主就跟他杠上了,无奈水笔博主选择了用selenium包来模拟人为操作,从主界面开始。
基本思路
访问大众点评从主页开始,然后选择钟意分类,让driver打开大众点评主页,找到美食元素,ActionChains(driver)悬停,定位到日本菜,ActionChains(driver)点击。
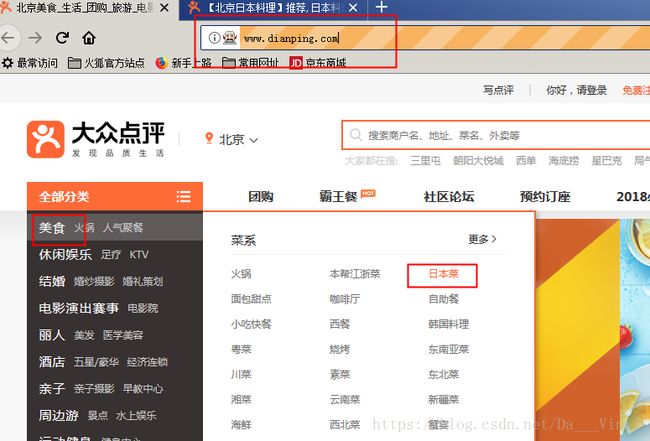
这之后会出现一个新窗口,需要将driver定位到这个窗口。一位博主告诉我的,感谢他。
代码运行过程中打开的窗口都可以通过driver获取,然后迭代定位。
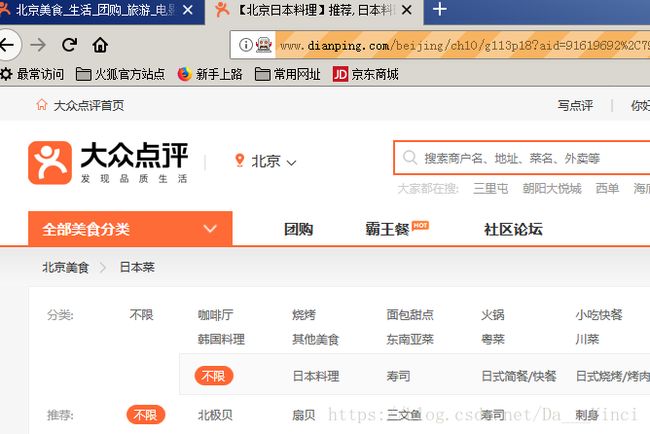
之后就是主要内容了,都在
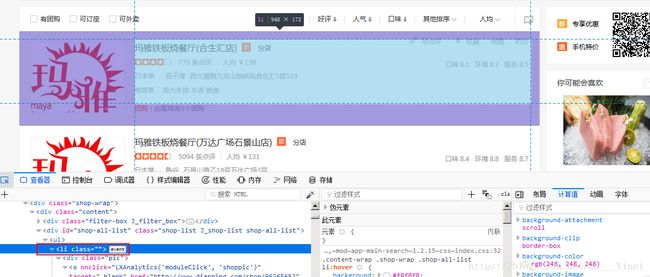
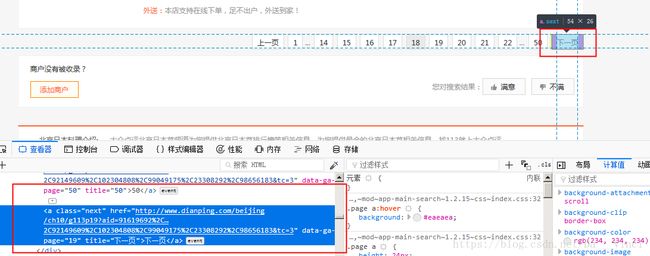
本页结束后,尝试寻找下一页标签,找到就点击,找不到就结束了。
博主把爬取到的内容存在项目文件中,目录要准确。要在project文件夹建文件才行,否则会被认为配置文件放到你找不到的地方,博主的电脑太慢了,爬了一会壁纸都出来了,反正可以用,就不等了哈哈。一共爬了18页的,内容大家可以根据需要改。

代码
代码是博主东拼西凑➕删删改改的,不知道光顾了多少人的博客,我就不一一答谢了,希望能够帮到大家。如果那位大罗金仙飘过,一定要点化晚辈啊,感激不尽。
# -*- coding:utf-8 -*-
import re
import time
from bs4 import BeautifulSoup
import json
import threading
from requests import Session
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
class dazp_bj:
def setUp(self):
# 调试的时候用firefox比较直观
# self.driver = webdriver.PhantomJS()
self.driver = webdriver.Firefox()
self.filename = 'D:\python\project\japanese.json' #储存位置
def testEle(self):
driver = self.driver
driver.maximize_window()
driver.get(r"http://www.dianping.com")#driver定位到主界面
attrible = driver.find_element_by_link_text("美食")
ActionChains(driver).move_to_element(attrible).perform()#鼠标悬停动作
time.sleep(1) #防止被判定为机器
attrible = driver.find_element_by_link_text("日本菜") #选择二级分类
ActionChains(driver).click(attrible).perform()
_json=dict() #定义一个字典用以存储数
time.sleep(1)
current_window = driver.current_window_handle # 获取当前窗口handle name
all_windows = driver.window_handles # 获取所有窗口handle name
# 切换window,如果window不是当前window,则切换到该window
for window in all_windows:
if window != current_window:
driver.switch_to.window(window)
print driver.title # 打印该页面title
time.sleep(10) #等待页面完全加载,否则数据不全,可根据电脑配置改变
while True: #while if 模仿 都while
soup = BeautifulSoup(driver.page_source, 'lxml') #获取当前页面全部内容
name=['商家名称','评论数量','人均消费','地址','评分','链接']
for li in soup.find('div',class_="shop-wrap").find('div',id="shop-all-list").ul.find_all('li'): #迭代商家
info=li.find('div',class_='txt')
_json[name[0]]=info.find('div',class_='tit').a.h4.get_text().encode('utf-8')
_json[name[1]]=int(info.find('div',class_='comment').find('a',class_="review-num").b.get_text().encode('utf-8'))
_json[name[2]]=int(re.sub('¥','',info.find('div',class_='comment').find('a',class_="mean-price").b.get_text().encode('utf-8')))
_json[name[3]]=info.find('div',class_='tag-addr').find('span',class_='tag').get_text().encode('utf-8')+info.find('div',class_='tag-addr').find('span',class_='addr').get_text().encode('utf-8')
_json[name[4]]=float(info.find('span',class_='comment-list').find_all('b')[0].get_text())+float(info.find('span',class_='comment-list').find_all('b')[1].get_text())+float(info.find('span',class_='comment-list').find_all('b')[2].get_text())
_json[name[5]]=info.find('div',class_='tit').a['href']
with open(self.filename,'a') as outfile: #追加模式
json.dump(_json,outfile,ensure_ascii=False)
with open(self.filename,'a') as outfile:
outfile.write(',\n')
if driver.find_element_by_css_selector("a[class= \"next\"][title=\"下一页\"]"): #css选择器查找
driver.find_element_by_css_selector("a[class= \"next\"][title=\"下一页\"]").click()
time.sleep(10)
continue
elif driver.find_element_by_link_text("下一页"): #text查找
driver.find_element_by_link_text("下一页").click()
time.sleep(10)
continue
else:
break
if __name__=='__main__':
a = dazp_bj()
a.setUp()
a.testEle()*爬虫的过程中不要动鼠标,最好将光标放到边缘。
有问题留言,我尽力帮助
更多机会与学习资料加入下方QQ群