基于机器学习算法对风险用户识别
基于机器学习算法对风险用户识别
题目简介:
根据提供的样本数据(语音通话、短信收发、及移动网络使用行为等特征),进行特征挖掘,并采用合适的算法模型(推荐xgboost),调试合适的参数,进行训练学习,最后得到风险用户判别结果。
资料说明:(数据集中uid->vid,代码中替换一下即可)

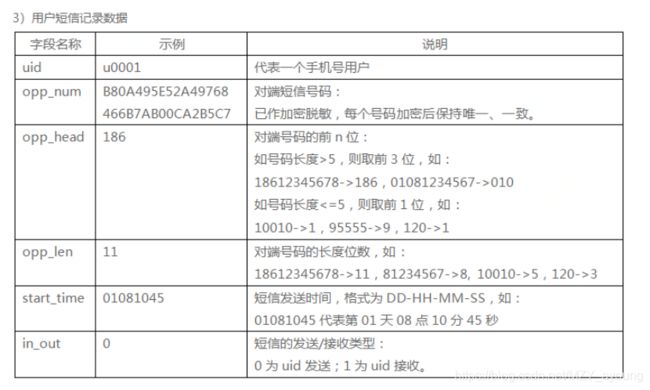

答题思路:
1.对数据集进行特征挖掘
#导入库
import pandas as pd
import numpy as np
import time
#读取文件数据
voice_train = pd.read_csv("voice_train.csv",sep="\t")
voice_test = pd.read_csv("voice_test.csv",sep="\t")
wa_test= pd.read_csv("wa_test.csv",sep="\t")
wa_train= pd.read_csv("wa_train.csv",sep="\t")
sms_train = pd.read_csv("sms_train.csv",sep ="\t")
sms_test = pd.read_csv("sms_test.csv",sep ="\t")
#合并数据
voice = pd.concat([voice_train,voice_test])
sms = pd.concat([sms_train,sms_test])
wa = pd.concat([wa_test,wa_train])
uid_train = pd.read_csv("uid_train.csv",sep ="\t")
uid_test = pd.read_csv("uid_test.csv",sep ="\t")
uid = pd.concat([uid_train,uid_test])
#去除重复的数据
voice.drop_duplicates(inplace=True)
#分组、统计in_out数、添加新字段名
voice_in_out = voice.groupby(['vid','in_out'])['vid'].count().unstack().add_prefix('voice_in_out_').reset_index().fillna(0)
#统计主动拨入与总平均拨入差值、
voice_in_out['voice_in_out-mean']=voice_in_out.voice_in_out_1 - np.mean(voice_in_out.voice_in_out_1)
#以vid分组输出特征唯一值
voice_in_out_unique = voice.groupby(['vid','in_out'])['opp_num'].nunique().unstack().add_prefix('voice_in_out_unique_').reset_index().fillna(0)
#对比呼入呼出次数
voice_in_out['voice_in_out_diff'] = voice_in_out.voice_in_out_1 - voice_in_out.voice_in_out_0
voice_in_out_unique['voice_in_out_unique_diff'] = voice_in_out_unique.voice_in_out_unique_1 - voice_in_out_unique.voice_in_out_unique_0
#号码分组、并统计号码唯一值次数
voice_opp_num = voice.groupby(['vid'])['opp_num'].agg({'unique_count': lambda x: len(pd.unique(x)),'count':'count'}).add_prefix('voice_opp_num_').reset_index().fillna(0)
#比较号码开头
voice_opp_head = voice.groupby(['vid'])['opp_head'].agg({'unique_count': lambda x: len(pd.unique(x))}).add_prefix('voice_opp_head_').reset_index().fillna(0)
#号码长度类型唯一性
voice_opp_len_type = voice.groupby(['vid'])['opp_len'].agg({'unique_count': lambda x: len(pd.unique(x))}).add_prefix('voice_opp_len_type_').reset_index().fillna(0)
#对唯一号码的长度分组
voice.opp_len = voice.opp_len.map(lambda x: 0 if (x==3 or x==6 or x == 14 or x>15) else x)
voice_opp_len=voice.groupby(['vid','opp_len'])['vid'].count().unstack().add_prefix('voice_opp_len_').reset_index().fillna(0)
#对唯一号码的类型分组
voice.call_type = voice.call_type.map(lambda x: 0 if (x > 3) else x)
voice_call_type = voice.groupby(['vid','call_type'])['vid'].count().unstack().add_prefix('voice_call_type_').reset_index()
#对号码类型统计
voice_call_type_unique = voice.groupby(['vid','call_type'])['opp_num'].nunique().unstack().add_prefix('voice_call_type_unique_').reset_index()
#数据集清洗函数
def time_gap(start,end):
if pd.isnull(start):
return np.nan
start = str(start)
end = str(end)
if(len(start)==7):
start = '0'+start
if(len(start)==6):
start = '00'+start
if(len(end)==7):
end = '0'+end
if(len(end)==6):
end = '00'+end
start_day = int(str(start)[0:2])
end_day = int(str(end)[0:2])
day_gap = (end_day-start_day)*86400
start_hour = int(str(start)[2:4])
end_hour = int(str(end)[2:4])
hour_gap = (end_hour-start_hour)*3600
start_min = int(str(start)[4:6])
end_min = int(str(end)[4:6])
min_gap = (end_min-start_min)*60
start_sec = int(str(start)[6:8])
end_sec = int(str(end)[6:8])
sec_gap = (end_sec-start_sec)
return day_gap+hour_gap+min_gap+sec_gap
# 对时间进行数据清洗
def time_clean(df):
try:
df["start_time"] = int(df["start_time"])
except ValueError:
df["start_time"] = df["end_time"]
return df
voice = voice.apply(time_clean,axis=1)
#对通话时间的统计
voice['gap_time']=voice[['start_time','end_time']].apply(lambda x: time_gap(x[0],x[1]),axis=1)
voice_gap_time=voice.groupby(['vid'])['gap_time'].agg(['std','max','min','median','mean','sum',np.ptp]).add_prefix('voice_gap_time_').reset_index()
#通话间隔统计
voice_sort = (voice.sort_values(by=['start_time','end_time'],ascending=True)).reset_index()
voice_sort['last_end_time']=voice_sort.groupby(['vid'])['end_time'].apply(lambda i:i.shift(1))
voice_sort['last_end_time'].dropna(inplace=True)
#对号码索引添加新列、计算其唯一数量
opp_num_list = voice.groupby(['opp_num'])['vid'].count().sort_values(ascending=False).reset_index()['opp_num'][0:1000].values
voice_each_opp_num_count=voice[voice.opp_num.map(lambda x: x in opp_num_list)].groupby(['vid','opp_num'])['vid'].count().unstack().add_prefix('voice_each_opp_num_count_').reset_index().fillna(0)
#对号码开头索引添加新列、计算其唯一数量
voice_each_opp_head_count=voice.groupby(['vid','opp_head'])['vid'].count().unstack().add_prefix('voice_each_opp_head_count_').reset_index().fillna(0)
#对端短信号码个数及出现次数
sms_opp_num_numcount=sms[["opp_num"]]
sms_opp_num_numcount["numcount"]=1
sms_opp_num_numcount=sms_opp_num_numcount.groupby(["opp_num"],as_index=False)["numcount"].agg({"numcount":np.sum})
sms_opp_head_0_count =sms.groupby(['vid'])['opp_head'].agg({'0': lambda x: np.sum(x.values == 0)}).add_prefix('sms_opp_head_').reset_index().fillna(0)
sms_opp_head_0_count['sms_head_0_count-mean'] = sms_opp_head_0_count.sms_opp_head_0 - np.mean(sms_opp_head_0_count.sms_opp_head_0)
sms = sms[sms.opp_head != 0]
#用户短信发送0/接收1数量
sms_in_out = sms.groupby(['vid','in_out'])['vid'].count().unstack().add_prefix('sms_in_out_').reset_index().fillna(0)
sms_in_out['sms_in_out-mean'] = sms_in_out.sms_in_out_1 - np.mean(sms_in_out.sms_in_out_1)
sms_in_out_unique = sms.groupby(['vid','in_out'])['opp_num'].nunique().unstack().add_prefix('sms_in_out_unique_').reset_index().fillna(0)
sms_in_out_unique['sms_in_out_unique-mean'] = sms_in_out_unique.sms_in_out_unique_1 - np.mean(sms_in_out_unique.sms_in_out_unique_1)
#用户每天接收短信数量
sms['sms_date'] = ((sms.start_time.astype(str).str.slice(0, 2).astype('int')-1) / 5).astype('int')
sms_date_count = sms.groupby(['vid', 'sms_date'])['vid'].count().unstack().add_prefix('sms_date_').reset_index().fillna(0)
sms_date_count_unique = sms.groupby(['vid', 'sms_date'])['opp_num'].nunique().unstack().add_prefix('sms_date_unique_').reset_index().fillna(0)
sms_opp_num = sms.groupby(['vid'])['opp_num'].agg({'unique_count': lambda x: len(pd.unique(x)),'count':'count'}).add_prefix('sms_opp_num_').reset_index().fillna(0)
sms_opp_num['sms_count-mean'] = (sms_opp_num.sms_opp_num_count - np.mean(sms_opp_num.sms_opp_num_count)).astype('float')
sms_opp_num['sms_unique_count-mean'] = (sms_opp_num.sms_opp_num_unique_count - np.mean(sms_opp_num.sms_opp_num_unique_count)).astype('float')
sms_opp_num['sms_opp_num_diff']=sms_opp_num.sms_opp_num_count - sms_opp_num.sms_opp_num_unique_count
#sms_opp_num
#_unique_count是排除多次重复接收短信后的次数,_count是包括了重复收到的短信次数,in_out中0是发送,1是接受
#统计用户接收的短信号码长度数量
sms.opp_len = sms.opp_len.map(lambda x: -1 if (x==3 or x==6 or x>15) else x)
sms_opp_len = sms.groupby(['vid','opp_len'])['vid'].count().unstack().add_prefix('sms_opp_len_').reset_index().fillna(0)
sms_opp_len_type = sms.groupby(['vid'])['opp_len'].agg({'unique_count': lambda x: len(pd.unique(x))}).add_prefix('sms_opp_len_type_').reset_index().fillna(0)
#统计一些特殊号码106的通知类短信,170、171虚拟号码段
sms_opp_head_17_count=sms.groupby(['vid'])['opp_head'].agg({'17_': lambda x: np.sum(x.values == 170) + np.sum(x.values == 171)}).add_prefix('sms_opp_head_').reset_index().fillna(0)
sms_opp_head_106_count =sms.groupby(['vid'])['opp_head'].agg({'106': lambda x: np.sum(x.values == 106)}).add_prefix('sms_opp_head_').reset_index().fillna(0)
sms_opp_head_106_count['sms_opp_head_106_count-mean'] = sms_opp_head_106_count.sms_opp_head_106 - np.mean(sms_opp_head_106_count.sms_opp_head_106)
sms_opp_head_106_count['sms_opp_head_not_106_count'] = sms_opp_num.sms_opp_num_count - sms_opp_head_106_count.sms_opp_head_106
sms_opp_head_106_count['sms_opp_head_not_106_count-mean'] = sms_opp_head_106_count.sms_opp_head_not_106_count - np.mean(sms_opp_head_106_count.sms_opp_head_not_106_count)
#统计特殊短信如opp_head为100的,像运营商的号码;170、171虚拟号码段,106的通知类短信
sms_opp_head_100_count =sms.groupby(['vid'])['opp_head'].agg({'100': lambda x: np.sum(x.values == 1)}).add_prefix('sms_opp_head_').reset_index().fillna(0)
sms_opp_head_100_count['sms_opp_head_100_count-mean'] = sms_opp_head_100_count.sms_opp_head_100 - np.mean(sms_opp_head_100_count.sms_opp_head_100)
sms_opp_head_100_count['sms_opp_head_not_100_count'] = sms_opp_num.sms_opp_num_count - sms_opp_head_100_count.sms_opp_head_100
sms_opp_head_100_count['sms_opp_head_not_100_count-mean'] = sms_opp_head_100_count.sms_opp_head_not_100_count - np.mean(sms_opp_head_100_count.sms_opp_head_not_100_count)
#用户短信接收/发送类型与相应的对端号码长度
sms_in_out_len = sms.groupby(['vid','opp_len'])['in_out'].agg({'in_out_0': lambda x: np.sum(x==0),'in_out_1': lambda x: np.sum(x==1)}).unstack().add_prefix('sms_in_out_len_').reset_index().fillna(0)
sms_opp_num_list = sms.groupby(['opp_num'])['vid'].count().sort_values(ascending=False).reset_index()['opp_num'][0:1000].values
sms_each_opp_num_count=sms[sms.opp_num.map(lambda x: x in sms_opp_num_list)].groupby(['vid','opp_num'])['vid'].count().unstack().add_prefix('sms_each_opp_num_count_').reset_index().fillna(0)
#去重函数drop_duplicates
wa.drop_duplicates(inplace=True)
#统计网站/APP的次数
wa_type =wa[['vid','watch_type']]
types = pd.get_dummies(wa_type["watch_type"])
types.columns =["APP","网站"]
wa_type = pd.concat([wa_type[["vid"]],types],axis=1)
wa_type =wa_type.groupby(["vid"],as_index=False).sum()
#统计浏览的总时长与次数
wa_visit =wa[['vid','visit_time_long']]
wa_visit =wa_visit.groupby(["vid"],as_index=False)["visit_time_long"].agg({"visit_time_long":np.sum})
wa_vist = wa[["vid","vist_times"]]
wa_vist = wa_vist.groupby(["vid"],as_index=False)["vist_times"].agg({"vist_times":np.sum})
#选择特征
feature = [
voice_in_out, voice_in_out_unique,
voice_opp_num, voice_opp_head,
voice_opp_len,
voice_opp_len_type,
voice_call_type,
voice_call_type_unique,
voice_gap_time,
#voice_each_opp_num_count,
voice_each_opp_head_count,
sms_in_out_len,#用户短信接收/发送类型与相应的对端号码长度
sms_opp_head_0_count,
sms_in_out,
sms_in_out_unique,#用户短信发送0/接收1数量
sms_opp_num,
#sms_opp_head,
sms_opp_len,sms_opp_len_type,#统计用户接收的短信号码长度数量
sms_opp_head_106_count, sms_opp_head_100_count,sms_opp_head_17_count,
#统计特殊短信如opp_head为100的,像运营商的号码;170、171虚拟号码段,106的通知类短信
#sms_start_time,
# sms_date_count, sms_date_count_unique,#用户每天接收短信数量
wa_type,wa_vist
]
train_feature = uid_train
for feat in feature:
train_feature=pd.merge(train_feature, feat, how='left',on='vid').fillna(0)
test_feature = uid_test
for feat in feature:
test_feature=pd.merge(test_feature,feat,how='left',on='vid').fillna(0)
#feature = pd.concat([train_feature,test_feature])
train_feature
train_feature.to_csv('total_train.csv',index=None)
test_feature.to_csv('total_test.csv',index=None)
以上是对训练集和测试集的特征挖掘,对数据清洗中,解决方法有:方法1、x/1000000取天数,其余类似。 方法2 可以先数据清洗 ,对于长度不为8的先转字符串 然后前面加 ‘00’ 再按位处理。以上挖掘的特征比较多,可以选择性选取训练,下一篇会有对特征模型训练的代码,欢迎大家一起讨论。