Python实战---使用Scrapy+ Selenium+ChromeDriver爬取简书所有文章
文章目录
- 使用Scrapy+ Selenium+ChromeDriver爬取简书所有文章
- 1、jianshu.py
- 2、items.py
- 3、middlewares.py
- 4、pipelines.py
- 5、settings.py
- 6、结果展示
- 7、总结
使用Scrapy+ Selenium+ChromeDriver爬取简书所有文章
创建项目
scrapy startproject jianshu
创建爬虫
scrapy genspider -t crawl jianshu “jianshu.com”
运行爬虫
scrapy crawl jianshu
或者创建start.py文件
from scrapy import cmdline
cmdline.execute('scrapy crawl jianshu'.split())
然后使用PyCharm打开项目
下面开始编写代码
1、jianshu.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import re
import requests
import json
from jianshu_spider.items import JianshuSpiderItem
class JianshuSpider(CrawlSpider):
name = 'jianshu'
allowed_domains = ['jianshu.com']
start_urls = ['https://www.jianshu.com/']
rules = (
# 编写匹配规则,简书文章的url只有中间12位不一样。
Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),
)
def parse_detail(self, response):
title = response.xpath('//h1[@class="_1RuRku"]/text()').get()
author = response.xpath('//span[@class = "FxYr8x"]/a/text()').get()
head_profile = response.xpath('//img[@class = "_13D2Eh"]/@src').get()
pub_time = response.xpath('//time/text()').get()
read_count = re.search(r'\d+',response.xpath('//div[@class = "s-dsoj"]/span[last()]').get()).group()
work_count = re.search(r'\d+',response.xpath('//div[@class = "s-dsoj"]/span[last()-1]').get()).group()
content = response.xpath('//article').get()
subjects_id = re.search(r'\d+',response.xpath('//meta[@property="al:android:url"]/@content').get()).group()
subjects = self.get_subject(subjects_id)
article_id = re.search(r'.*/p/(.*)',response.xpath('//meta[@http-equiv = "mobile-agent" ]/@content').get()).group(1)
article_url = response.url
item = JianshuSpiderItem(
title = title,
author = author,
head_profile = head_profile,
pub_time = pub_time,
read_count = read_count,
work_count = work_count,
content = content,
subjects = subjects,
article_id = article_id,
article_url = article_url
)
yield item
# 爬取文章所在的专题
#使用requests重新请求,获取专题列表并返回。
def get_subject(self,subjects_id):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
subjects_url = 'https://www.jianshu.com/shakespeare/notes/{}/included_collections?page=1&count=7'.format(
subjects_id)
resp = json.loads(requests.get(url=subjects_url,headers=headers).text)
total_pages = resp['total_pages']
subjects = []
for page in range(1, total_pages + 1):
subjects_url = 'https://www.jianshu.com/shakespeare/notes/{}/included_collections?page=1&count=7'.format(
subjects_id)
resp = json.loads(requests.get(url=subjects_url,headers=headers).text)
collections = resp['collections']
for collection in collections:
subject = collection['title']
subjects.append(subject)
subjects = ','.join(subjects)
return subjects
2、items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class JianshuSpiderItem(scrapy.Item):
title = scrapy.Field() # 标题
author = scrapy.Field() # 作者
head_profile = scrapy.Field() # 头像
pub_time = scrapy.Field() # 发布时间
read_count = scrapy.Field() # 阅读数
work_count = scrapy.Field() # 字数
content = scrapy.Field() # 文章内容
subjects = scrapy.Field() # 文章专题
article_id = scrapy.Field() # 文章id
article_url = scrapy.Field() # 文章url
3、middlewares.py
使用selenium+webdriver来请求url
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from selenium import webdriver
import time
from scrapy.http.response.html import HtmlResponse
class JianshuSeleniumDownloadMiddleware(object):
def __init__(self):
self.driver = webdriver.Chrome(executable_path=r'D:\Driver\chromedriver.exe')
def process_request(self,request,spider):
self.driver.get(request.url)
time.sleep(2)
# try:
# while True:
# show_more = self.driver.find_element_by_class_name('H7E3vT')
# show_more.click()
# time.sleep(2)
# if not show_more:
# break
# except:
# pass
source = self.driver.page_source
# 将重新组装的response返回给scrapy框架解析
response = HtmlResponse(url=self.driver.current_url,body=source,request=request,encoding='utf-8')
return response
4、pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class JianshuSpiderPipeline:
def __init__(self):
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': 'root',
'password': 'root',
'database': 'jianshu',
'charset': 'utf8'
}
self.conn = pymysql.connect(**dbparams)
self.cursor = self.conn.cursor()
self._sql = None
def process_item(self, item, spider):
self.cursor.execute(self.insert_sql,(
item['title'],
item['author'],
item['head_profile'],
item['pub_time'],
item['read_count'],
item['work_count'],
item['content'],
item['subjects'],
item['article_id'],
item['article_url']
))
print('第%s条数据即将被插入' % self.conn.insert_id())
self.conn.commit()
return item
@property
def insert_sql(self):
if not self._sql:
self._sql = """
insert into article
(id,title,author,head_profile,pub_time,read_count,work_count,content,subjects,article_id,article_url)
values (null,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
return self._sql
return self._sql
5、settings.py
把其中相关的设置打开
# -*- coding: utf-8 -*-
# Scrapy settings for jianshu_spider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'jianshu_spider'
SPIDER_MODULES = ['jianshu_spider.spiders']
NEWSPIDER_MODULE = 'jianshu_spider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'jianshu_spider (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'jianshu_spider.middlewares.JianshuSpiderSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'jianshu_spider.middlewares.JianshuSeleniumDownloadMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'jianshu_spider.pipelines.JianshuSpiderPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
6、结果展示
存入到mysql数据库中
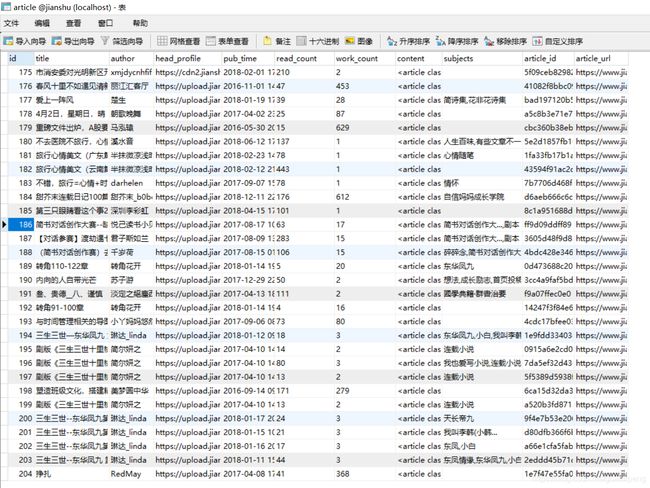
7、总结
博主没有完全爬取完毕,作为练习,爬取了一段时间就停止掉了。
如果您有需要,可以爬取所有的文章,之后再做相关分析。
项目的连接和sql文件在下面连接,需要的自行下载即可
项目源码和sql文件