专访范斌,谈开源三年后的Alluxio
在Alluxio(前Tachyon)项目开源三年后的今天,全世界已经有超过300名贡献者参与到项目当中,其中包括Intel,百度,去哪儿等100多家公司。仅仅在去年,它的代码贡献人数就比以往翻了三倍。Alluxio项目已经成为大数据领域内历史上成长最快的项目之一。
本期被访嘉宾——范斌(@apc2):Alluxio公司软件工程师,也是Alluxio开源项目的管理委员会(PMC)成员。曾在Microsoft Research,Google任职并研发大规模分布式存储系统。

以下为采访实录
CSDN:请介绍一下自己。
范斌:我是Alluxio公司的软件工程师,也是Alluxio开源项目的管理委员会(PMC)成员。加入Alluxio项目之前曾在Microsoft Research,Google任职并研发大规模分布式存储系统,并获Google Technical Infrastructure奖。博士毕业自卡内基梅隆大学计算机系,期间主攻分布式系统方向,并有多篇论文发表于SOSP,SIGCOMM,NSDI等顶级学术会议。
我和Alluxio项目创立者李浩源以及部分核心开发者会在七月底八月初在南京,上海和北京三地参加或举办一系列的meetup活动。期待可以和广大开发者以及用户能有深入的分享交流。
CSDN:Google是很多人理想供职公司, 从Google到Alluxio, 促成你做这个选择的原因是什么?
范斌:在Google工作期间, 非常喜欢那里深厚的技术底蕴以及工程师文化(当然园区内的免费食物也非常吸引人)。Google的经历不仅培养了我科学正规的软件工程习惯,加深了对大数据的理解,更重要的是帮助我开拓了视野,站在一个工业界的制高点来看待和理解技术发展趋势。
正是由于这样的经历,让我在和李浩源(Alluxio项目创始人)吃了一顿饭后就做出了加入Alluxio的决定。因为在我看来,Alluxio解决了一个大数据领域中正变得无比重要的问题——如何让数据从计算模型中抽象和独立出来,并在不同计算中高效的共享。同时这个项目又是从大数据领域的创新源泉UC Berkeley的AMPLab孵化而出,团队的创新氛围非常浓厚。在这样一个朝气蓬勃又理想远大的项目当中,每个人都能有更快的成长。
事实上不仅仅是我,Alluxio团队中超过一大半的工程师都来自于Google,都有着设计、实现或是使用大规模分布式系统的多年的经验。比如我就有若干个同事来自Google内部实现Google File System的团队以及F1(Google的分布式关系型数据库)的团队,大家都对Alluxio抱着相似的理想而加入了这个团队。
CSDN:Alluxio团队的构成大概是什么样子?平时在一起都做些什么?
范斌:我们的团队大多数成员都是从UC Berkeley,CMU等学校的计算机系博士毕业,并在Google,Facebook或者Palantir等业界知名公司的大数据部门工作过的工程师。可能整体年龄相对年轻的缘故,感觉非常像在学校。团队成员平时工作的时候的非常玩命,但工作之余也会像美剧《生活大爆炸》里面那样,非常喜欢说那些Geek才能理解的笑话,非常较真的一起玩桌游,打电子游戏。比如我就和美国同事那里学会了很多新奇的桌游,不过让我自豪的是我也教会了他们打英文版的《三国杀》。
CSDN:为何会有Alluxio项目?它最初是如何开始的?
范斌:大约在2012年的时候,加州大学伯克利分校的AMPLab在那时已经创建了Spark和Mesos等大数据项目,并正在越来越多的得到工业界关注和应用。然而这个时候的伯克利的大数据协议栈中还有一个重要的缺失环节:如何在多个任务之间以高速方便而可靠的方式共享数据。于是在两位导师Ion Stoica教授以及Scott Shenker教授的鼓励下,李浩源把这一问题当做自己的博士课题,设计并实现了一个基于内存的分布式文件系统Tachyon并将之开源,这也就是Alluxio的前身。
CSDN:请简单介绍一下Alluxio社区现状, 以及它的发展过程。
范斌:在2013年初的时候,Alluxio(原名Tachyon)还仅仅是项目创始人李浩源在UC Berkeley AMPLab的博士研究课题。自从放上Github开源以来,迅速吸引了各方的关注并实现了高速成长。项目从最初李浩源一个人的课题,扩大到一群AMPLab同学的加入,接下来由不同高校和科研机构的关注和贡献,再到获得像Intel等有雄厚实力的公司加盟助力。
在项目开源三年后的今天,全世界已经有超过300名贡献者参与到项目当中,其中包括Intel,百度,去哪儿等100多家公司。仅仅在去年,它的代码贡献人数就比以往翻了三倍。Alluxio项目已经成为大数据领域内历史上成长最快的项目之一。
CSDN:你认为Alluxio的典型应用场景是什么?当前有哪些公司在使用。
范斌: Alluxio作为一个内存级的虚拟分布式存储系统有几个常见的使用场景:
1. 计算层需要反复访问远程(比如在云端,或跨机房)的数据;
2. 计算层需要同时访问多个独立的持久化数据源(比如同时访问S3和HDFS中的数据);
3. 多个独立的大数据应用(比如不同的Spark Job)需要高速有效的共享数据;
4. 当计算层有着较为严重的内存资源、以及JVM GC压力,或者较高的任务失败率时,Alluxio作为输入输出数据的Off heap存储可以极大缓解这一压力,并使计算消耗的时间和资源更可控可预测。
Alluxio系统已经被部署使用在不同行业,例如百度、巴克莱银行、去哪儿网等公司的生产环境中,在其中一些部署应用中运行了一年多,管理着PB级别的数据。
CSDN:Alluxio的出现和发展在技术上有什么样的时代背景?
范斌:随着大数据生态的蓬勃发展,计算框架的选择越来越丰富也越来越细化,常见的选择包括Spark, Flink, Beam, Presto, MapReduce等。而海量数据的存储方案, 除了HDFS之外, 以AWS, GCE为代表的云存储也正迅速崛起。这些趋势叠加起来,将逐步颠覆过去一段时间里流行的将计算和存储紧密耦合的大数据处理模型。换言之,像过去那样由计算层完全理解和控制数据流动,会导致计算层和存储层都过于复杂,难以快速迭代。
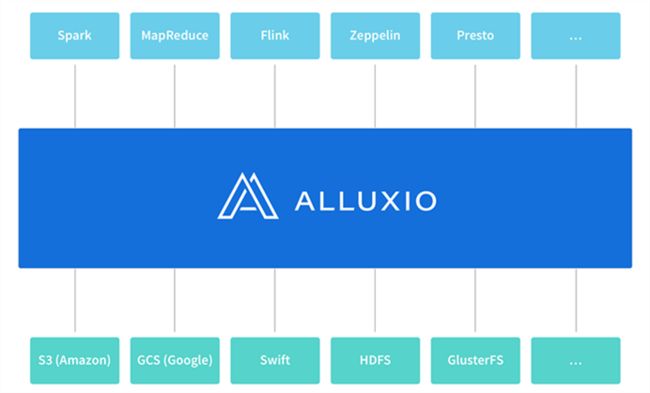
Alluxio的目的就是想要让计算层和存储层可以再次轻装上阵,让它们独立的优化和发展自己,而不用担心破坏两者之间的依赖。具体说来,Alluxio提供一层文件系统的抽象给计算层。这层抽象之上的计算只需要和Alluxio交互来访问数据;而这层抽象之下可以同时对接多个不同的持久化存储(比如一个S3加上一个HDFS部署),而这层抽象本身又是由部署在靠近计算的内存级Alluxio存储系统来实现。一个典型的场景比如在百度,Spark不在需要关心数据是否是在本机房还是远程的数据中心,它只需要通过Alluxio中读写数据,而Alluxio可以聪明的帮助应用在需要时把数据同步到远端。
CSDN:作为一个高速发展中的开源项目, 用户想投入生产环境使用往往会面对各种各样的问题, 那么用户从哪里可以找到答案, 甚至是参与这个项目。
范斌:想要了解如何贡献给Alluxio项目的人,可以参考项目的使用文档。在这里要特别感谢Alluxio中文社区特别是南京大学的贡献者,在他们的帮助下我们最近新添增了中文支持。
对于想以最快速度在生产环境中熟悉和部署Alluxio的用户,我们提供培训;其他需要可以通过这里和我们直接联系。
对于想要初步了解Alluxio的人我们有一个活跃的用户邮件列表方便大家交流。对于墙内用户,可以访问其镜像。
CSDN:相比较其他的基于内存的大数据开源项目,Alluxio的区别和优势在哪里?同时,也请给大家分享一下Alluxio未来的Roadmap, 让大家有更多的了解。
范斌: Alluxio是世界上第一个内存级虚拟分布式存储系统。其独特的优势直接体现在设计和架构理念上。从一开始,Alluxio的目标就是将现有的大数据生态更简单更有效的整合在一起,让未来大数据项目的开发和维护越来越简单,让Alluxio上层和下层都得以更快的发展,让所有其他大数据项目都可以更快的迭代。我们会围绕这一目标来提高和优化Alluxio,诸如和更多计算框架的整合,和更多存储系统的整合,在未来可以更好的发挥计算和存储之间的桥梁的作用。
Alluxio项目创立者李浩源以及部分核心开发者会在七月底八月初在南京,上海和北京三地参加或举办一系列的meetup活动。欢迎广大开发者以及用户参与交流。