基于NaiveBayse SVM KNN的Python垃圾短信过滤系统 附代码
垃圾短信过滤系统
一个课程的结课设计,挺好玩的。
数据处理:
短信数据来源于UCI machine learning repository,可以到以下网址去下载:https://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
计算机不可能直接识别文字,并在其基础上进行计算,因此,我们的文字将要转换成可计算的数字,比如,向量。
步骤:
比如:原句My name is jerry,my name is Tom.
1.原句转化成单个词汇的列表,因为我并不需要知道词汇之间的关系,我只需要找到这条信息中是什么把它变的倾向于垃圾短信或是正常短信。['my','name','is','jerry'],['my','name','is','Tom']
2.创建词汇表,记录所有出现词汇,并去除重复词汇。['my','name','is','jerry','Tom']
3.现在,根据原句可创建对应的向量并可用于计算。
以下所有机器学习算法,都统一使用如此处理的数据进行训练。
Naive Bayse 朴素贝叶斯:
基于贝叶斯定理:
![]()
笼统点,可以理解为是一种条件概率,在这个系统中可以表示为,这个单词出现时,是垃圾短信的概率有多少。
具体步骤:
1.基于上面数据处理步骤2中的词汇列表,进行频率的统计,例如,出现了几个‘My’,并且是垃圾短信时有几个‘My’,非垃圾短信时有几个‘My’。
2.创建概率表,基于步骤1的统计进行相应的概率计算,能得到每个词汇的垃圾概率和非垃圾概率。另外,此步骤需要加上拉普拉斯平滑,防止0进入计算。此步骤建议使用Log()方法,防止计算机计算过小值导致损失精度。
3.句子的向量与概率表进行计算,得出该句子的垃圾概率与非垃圾概率,选取较大的那个。
基于随机选取的60训练数据与20测试数据,进行10次运行。
MaxRecall: 0.8
MaxPrecision: 1.0
MinError: 0.2
AveRecall(平均召回率): 0.7068421052631579
AvePrecision(平均精确度): 0.9854166666666666
AveError(平均错误率): 0.3
AveTime(平均运行时间): 0.028286582971390355
MaxPrecision: 1.0
MinError: 0.2
AveRecall(平均召回率): 0.7068421052631579
AvePrecision(平均精确度): 0.9854166666666666
AveError(平均错误率): 0.3
AveTime(平均运行时间): 0.028286582971390355
看起来还不算差,起码AvePrecision不低,不会有太多的正常短信被误认为垃圾短信。
SVM (Support Vector Machine)支持向量机:
我有文章详细介绍过,这里就不多讲了。这里使用的是Sklearn的package来实现的。
默认状态:
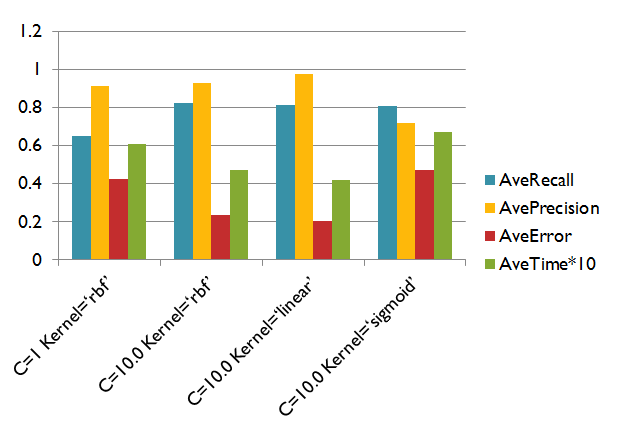
C=1 Kernel=‘rbf’
MaxRecall: 1.0
MaxPrecision: 1.0
MinError: 0.05
AveRecall: 0.6505847953216375
AvePrecision: 0.9140598290598291
AveError: 0.425
AveTime: 0.06084513318737096
MaxRecall: 1.0
MaxPrecision: 1.0
MinError: 0.05
AveRecall: 0.6505847953216375
AvePrecision: 0.9140598290598291
AveError: 0.425
AveTime: 0.06084513318737096
提高惩戒指数:
C=10.0 Kernel=‘rbf’
MaxRecall: 0.9444444444444444
MaxPrecision: 1.0
MinError: 0.1
AveRecall: 0.8248402869919899
AvePrecision: 0.9303405572755418
AveError: 0.23500000000000004
AveTime: 0.04786081637264809
MaxPrecision: 1.0
MinError: 0.1
AveRecall: 0.8248402869919899
AvePrecision: 0.9303405572755418
AveError: 0.23500000000000004
AveTime: 0.04786081637264809
就提升到10.0,后面优化的就不明显了,而且还有过拟合的风险。
更换核函数:
C=10.0 Kernel='linear'
MaxRecall: 0.9
MaxPrecision: 1.0
MinError: 0.1
AveRecall: 0.8122222222222222
AvePrecision: 0.977124183006536
AveError: 0.205
AveTime: 0.04208579490100922
MaxRecall: 0.9
MaxPrecision: 1.0
MinError: 0.1
AveRecall: 0.8122222222222222
AvePrecision: 0.977124183006536
AveError: 0.205
AveTime: 0.04208579490100922
测试了几个核函数,这个的数据是最满意的。
KNN(k-NearestNeighbor):
最简单的机器学习算法之一,我的文章也有涉及。这个是顺手就做了一个,依旧使用了Sklearn的包。
默认状态:
n_neighbors=5
MaxRecall: 0.6
MaxPrecision: 1.0
MinError: 0.4
AveRecall: 0.495
AvePrecision: 1.0
AveError: 0.505
AveTime: 0.060209280330714585
MaxRecall: 0.6
MaxPrecision: 1.0
MinError: 0.4
AveRecall: 0.495
AvePrecision: 1.0
AveError: 0.505
AveTime: 0.060209280330714585
不如随机系列。
尝试优化:
n_neighbors=3, algorithm='ball_tree'
MaxRecall: 0.65
MaxPrecision: 1.0
MinError: 0.35
AveRecall: 0.5499999999999999
AvePrecision: 1.0
AveError: 0.45000000000000007
MaxRecall: 0.65
MaxPrecision: 1.0
MinError: 0.35
AveRecall: 0.5499999999999999
AvePrecision: 1.0
AveError: 0.45000000000000007
AveTime: 0.05553739146649517
依旧不尽人意,训练数据量相同,都是30个,不会出现容易被归纳为实例多的样本的情况。可能是分布实在是不太有规律,可以试着使用朴素贝叶斯的概率表,根据概率表排序后可能就会好很多。不过,KNN有点就是正常短信永远都不会被误认为垃圾。
结论:
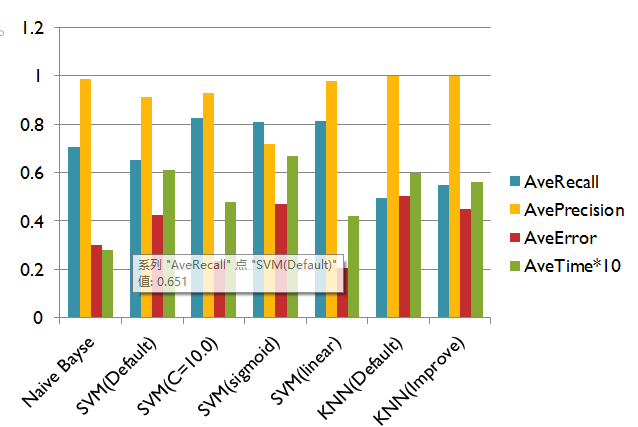
朴素贝叶斯用时最短,Recall和Precision也不错。
SVM用时略长,但是Recall特别高,Precision也不低。
KNN,虽然Recall和用时都不怎么样,但是Precision永远是100%。
附上Github源码:https://github.com/jerry81333/SpamSMSFiltering