ctdb原理介绍
1. CTDB概述
CTDB是一个集群TDB数据库,可以被Samba或者其他的应用使用来存储数据。如果一个应用是使用TDB来暂时存放数据,那么这个应用可以很轻松的使用CTDB扩展为集群模式。CTDB提供与TDB相同的函数接口,并且是构建在多台物理机器上的集群。
特性:
- CTDB提供一个横跨多个节点的并且数据一致、锁一致的TDB数据库;
- CTDB非常快速;
- 对于节点故障,CTDB将自动恢复和修复其所管理的所有TDB数据库;
- CTDB是Samba3/4的一个核心组件;
- CTDB提供高可用特性,例如节点监控、节点切换、IP切换;
- CTDB为其多个节点上的应用提供可靠的传输通道;
- CTDB提供可热拔插的后端传输通道,目前实现了TCP和IB;
- CTDB可以提供为应用指定特定的管理脚本,使得应用能够实现高可用。
2. CTDB配置
CTDB的配置相对简单,对于搭建一个三节点的CTDB配置步骤说明如下。
2.1 节点信息
| 节点名称 | 节点IP | 说明 |
|---|---|---|
| node1 | 10.10.10.90 | CTDB节点 |
| node2 | 10.10.10.91 | CTDB节点 |
| node3 | 10.10.10.92 | CTDB节点 |
| node4 | 10.10.10.99 | 共享存储 |
说明:此处为快速简单的搭建ctdb集群,采用单节点NFS共享,不考虑NFS共享的可靠性。
实际应用时,共享存储应由高可靠的集群担当。
2.2搭建CTDB集群
2.2.1 安装软件
在三个CTDB节点分别安装ctdb,nfsd,samba,可以通过命令 yum install ctdb依次进行安装;
2.2.2 创建共享存储
在node4创建一个共享目录/share,并设置权限777,在/etc/exports文件中添加如下:
/share *(sync,rw)然后在节点4上执行如下命令:
# exoprtfs -rvCTDB节点之间需要通过一个共享的存储来实现其基于锁机制的选举过程。
2.2.3 挂载共享存储
在三个CTDB节点上分别执行如下命令:
# mount -t nfs 10.10.10.99:/share /mntnode1, node2,node3上都挂载了node4共享出来的目录,这样三个节点就可以访问到一个相同的锁文件了。
2.2.4 修改CTDB服务配置
在三个CTDB节点上修改如下文件:
~# vi /etc/sysconfig/ctdb
CTDB_RECOVERY_LOCK=/mnt/ctdb_lock
CTDB_MANAGES_SAMBA=yes
CTDB_MANAGES_WINBIND=yes
CTDB_MANAGES_NFS=yes这个步骤中主要配置CTDB管理哪些应用。还有就是指定共享锁文件的目录。
2.2.5 修改CTDB节点配置
在三个CTDB节点上创建或者修改如下文件:
~# vi /etc/ctdb/nodes
10.10.10.91
10.10.10.92
10.10.10.902.2.6 修改CTDB IP配置
在三个CTDB节点上创建或者修改如下文件:
~# vi /etc/ctdb/public_addresses
10.0.0.1/24 eth0其中eth0是节点上存在的并且在线的网卡。10.0.0.1就是配置给这个三个节点CTDB集群对外提供业务的IP。
2.2.7 重启CTDB服务
在三个CTDB节点上执行如下命令:
~# systemctl restart ctdb2.2.8 查看CTDB服务状态
在节点1上执行:
# ctdb status
Number of nodes:3
pnn:0 10.10.10.91 OK
pnn:1 10.10.10.92 OK
pnn:2 10.10.10.90 OK (THIS NODE)
Generation:1699238992
Size:3
hash:0 lmaster:0
hash:1 lmaster:1
hash:2 lmaster:2
Recovery mode:NORMAL (0)
Recovery master:1
[root@xenserver-yzulkyuc ~]#
集群搭建完成。
说明:如果节点数量较少,可以将某一个CTDB节点作为共享存储,同时节点数量也可以为1。但是将CTDB节点作为共享存储的话,需要将/etc/sysconfig/ctdb 文件中的CTDB_MANAGES_NFS设置位NO。
3. CTDB源码分析
3.1 关键数据结构
3.1.1 ctdb
CTDB有两个进程构成,ctdbd和recoveryd。在这个两个进程进行各种事物处理时,一般都带有一个参数:ctdb。该数据结构是包含了基本上所有逻辑所需或者相关的数据。在CTDBD启动阶段就是对ctdb数据结构的填充阶段。
struct ctdb_context {
struct tevent_context *ev; //封装的事件处理接口,后端使用select/poll/epoll 多路I/O复用机制
struct timeval ctdbd_start_time; //ctdbd启动时间
struct timeval last_recovery_started;
struct timeval last_recovery_finished;
uint32_t recovery_mode; //根据此值可以判断是否需要进行recovery
TALLOC_CTX *tickle_update_context;
TALLOC_CTX *keepalive_ctx;
TALLOC_CTX *check_public_ifaces_ctx;
struct ctdb_tunable_list tunable;
enum ctdb_freeze_mode freeze_mode;
struct ctdb_freeze_handle *freeze_handle;
bool freeze_transaction_started;
uint32_t freeze_transaction_id;
ctdb_sock_addr *address; //此ctdb节点的IP地址
const char *name;
const char *db_directory;
const char *db_directory_persistent;
const char *db_directory_state;
struct tdb_wrap *db_persistent_health;
uint32_t db_persistent_startup_generation;
uint64_t db_persistent_check_errors;
uint64_t max_persistent_check_errors;
const char *transport;
const char *recovery_lock;
uint32_t pnn; /* our own pnn */
uint32_t num_nodes;
uint32_t num_connected;
unsigned flags;
uint32_t capabilities;
struct reqid_context *idr;
struct ctdb_node **nodes; //集群节点列表,索引为vnn
struct ctdb_vnn *vnn; //公共IP列表和网卡
struct ctdb_interface *ifaces; /* list of local interfaces */
char *err_msg;
const struct ctdb_methods *methods; //启动时注册的tcp处理函数
const struct ctdb_upcalls *upcalls; //启动时注册的处理函数
void *private_data; /* private to transport */
struct ctdb_db_context *db_list;
struct srvid_context *srv;
struct ctdb_daemon_data daemon;
struct ctdb_statistics statistics;
struct ctdb_statistics statistics_current;
#define MAX_STAT_HISTORY 100
struct ctdb_statistics statistics_history[MAX_STAT_HISTORY];
struct ctdb_vnn_map *vnn_map;
uint32_t num_clients;
uint32_t recovery_master;
struct ctdb_client_ip *client_ip_list;
bool do_checkpublicip;
bool do_setsched;
const char *event_script_dir;
const char *notification_script;
const char *default_public_interface;
pid_t ctdbd_pid;
pid_t recoverd_pid;
enum ctdb_runstate runstate;
struct ctdb_monitor_state *monitor;
int start_as_disabled;
int start_as_stopped;
bool valgrinding;
uint32_t *recd_ping_count;
TALLOC_CTX *recd_ctx; /* a context used to track recoverd monitoring events */
TALLOC_CTX *release_ips_ctx; /* a context used to automatically drop all IPs if we fail to recover the node */
struct eventd_context *ectx;
TALLOC_CTX *banning_ctx;
struct ctdb_vacuum_child_context *vacuumers;
/* mapping from pid to ctdb_client * */
struct ctdb_client_pid_list *client_pids;
/* Used to defer db attach requests while in recovery mode */
struct ctdb_deferred_attach_context *deferred_attach;
/* if we are a child process, do we have a domain socket to send controls on */
bool can_send_controls;
struct ctdb_reloadips_handle *reload_ips;
const char *nodes_file;
const char *public_addresses_file;
struct trbt_tree *child_processes;
/* Used for locking record/db/alldb */
struct lock_context *lock_current;
struct lock_context *lock_pending;
};3.1.2 初始化upcall
在上面一节中的ctdb结构中可以看到有这个upcall处理函数接口。初始化操作是在main()函数的入口处进行的。
ctdb->recovery_mode = CTDB_RECOVERY_NORMAL;
ctdb->recovery_master = (uint32_t)-1;
ctdb->upcalls = &ctdb_upcalls;而ctdb_upcalls定义如下:
static const struct ctdb_upcalls ctdb_upcalls = {
.recv_pkt = ctdb_recv_pkt, //当有消息包传入时调用此函数进行处理。
.node_dead = ctdb_node_dead, //当有节点出现故障或者离线时调用此函数,进行的操作是重启。
.node_connected = ctdb_node_connected //当有连接请求发送时,调用此函数,更新连接统计信息。
};
3.1.3 创建unix socket fd
在启动ctdbd守护进程过程中,创建了unix socket,并且将fd赋值给了3.1.1中的daemon.sd。并且开始监听是否有连接请求。
ctdb->daemon.sd = socket(AF_UNIX, SOCK_STREAM, 0);3.1.4 初始化tevent
tevent是ctdb中事件处理机制,底层采用select/poll/epoll多路I/O复用机制,对外提供统一的接口。初始化就是将接口进行统一处理。接口的统一入口就是3.1.1小节中提的ctdb->ev。
ctdb->ev = tevent_context_init(NULL);初始化完成后,形成一个双向链表,链表中存放的是不同的I/O多路复用接口,但是对于调用这来说,看的接口是相同的。
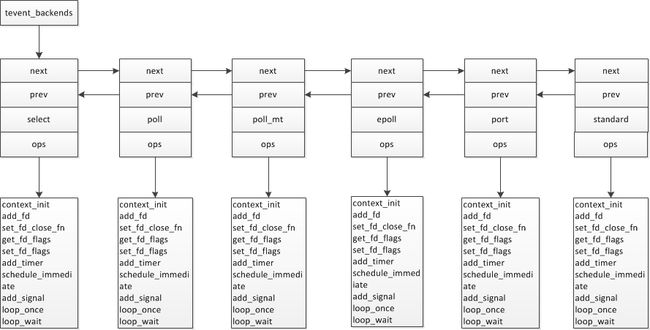
即ops的名称是一致的,而对于不同的I/O复用就赋值了相对应的函数接口。
static const struct tevent_ops select_event_ops = {
.context_init = select_event_context_init,
.add_fd = select_event_add_fd,
.set_fd_close_fn = tevent_common_fd_set_close_fn,
.get_fd_flags = tevent_common_fd_get_flags,
.set_fd_flags = tevent_common_fd_set_flags,
.add_timer = tevent_common_add_timer_v2,
.schedule_immediate = tevent_common_schedule_immediate,
.add_signal = tevent_common_add_signal,
.loop_once = select_event_loop_once,
.loop_wait = tevent_common_loop_wait,
};3.1.5 tcp传输通道初始化
在ctdbd守护进程启动节点,初始化tcp传输通道
/*
initialise tcp portion of ctdb
*/
int ctdb_tcp_init(struct ctdb_context *ctdb)
{
struct ctdb_tcp *ctcp;
ctcp = talloc_zero(ctdb, struct ctdb_tcp);
CTDB_NO_MEMORY(ctdb, ctcp);
ctcp->listen_fd = -1;
ctcp->ctdb = ctdb;
ctdb->private_data = ctcp;
ctdb->methods = &ctdb_tcp_methods;
talloc_set_destructor(ctcp, tcp_ctcp_destructor);
return 0;
}上面的代码中的ctdb->methods初始化为了&ctdb_tcp_methods,其定义如下:
static const struct ctdb_methods ctdb_tcp_methods = {
.initialise = ctdb_tcp_initialise,
.start = ctdb_tcp_start,
.queue_pkt = ctdb_tcp_queue_pkt,
.add_node = ctdb_tcp_add_node,
.connect_node = ctdb_tcp_connect_node,
.allocate_pkt = ctdb_tcp_allocate_pkt,
.shutdown = ctdb_tcp_shutdown,
.restart = ctdb_tcp_restart,
};进行上述接口注册后,就调用的ctdb_tcp_initialise进行初始了,在该函数中完成了两件事情
- ctcp->listen_fd = socket(sock.sa.sa_family, SOCK_STREAM, IPPROTO_TCP);创建了一个socket server端,监听的地址是当前ctdb节点的地址。监听后,注册了一个监听事件,一旦有其他节点来连接当前ctdb节点,将调用注册的函数:ctdb_listen_event,在该处理函数中将accept连接请求。并再次注册一个读事件到tevent中。也就是当客户端有写入数据时,当前ctdb将调用ctdb_tcp_read_cb进行数据包的处理。
in->queue = ctdb_queue_setup(ctdb, in, in->fd, CTDB_TCP_ALIGNMENT,
ctdb_tcp_read_cb, in, "ctdbd-%s", ctdb_addr_to_str(&addr));- 给ctdb集群的所有节点都创建了一个out_queue队列,并且这个数据结构保存在ctdb->node[i]中。
3.1.6 unix socket accept函数
在3.1.3中已经创建了unix socket,此时注册了一个accept事件,处理函数为:ctdb_accept_client,事件类型为TEVENT_FD_READ。在此处理函数中会accept连接请求。并将已经连接上的client信息存放在 ctdb->client_pids 链表当中。最后再次注册一个读请求处理函数ctdb_daemon_read_cb。该函数注册的位置为:ctdb->client_pids->queue->callback,此外ctdb->client_pids->queue->im= tevent_create_immediate(queue);理解起来应该是,如果已连接的这个unix socket上有读事件的话,立刻处理。
3.1.7 启动tcp传输通道
调用的函数为ctdb_tcp_start(ctdb);该函数主要完成node节点之间的tcp连接。在前3.1.5节中说到每一个ctdb节点都在监听自己的IP地址,而ctdb_tcp_start(ctdb)相当于把当前节点作为client,去连接所有其他的ctdb节点。同样,其他节点也会进行相同的操作处理。也就是最后会出现的结果是集群的每一个节点都与剩余节点存在链接。这个已连接的fd保存在ctdb->node[i]->private_data(ctdb_tcp_node)->fd。
同时注册了两个事件,一个是已建立连接可写时的事件处理函数。第二个是定时连接处理函数,就是每隔一秒钟去连接这个节点。
从已有的三节点ctdb环境中可以看到相关连接的信息:
[root]# netstat -anp | grep ctdbd
tcp 0 0 10.10.10.90:4379 0.0.0.0:* LISTEN 1006/ctdbd
tcp 0 0 10.10.10.90:50071 10.10.10.92:4379 ESTABLISHED 1006/ctdbd
tcp 0 0 10.10.10.90:4379 10.10.10.91:48353 ESTABLISHED 1006/ctdbd
tcp 0 0 10.10.10.90:4379 10.10.10.92:57112 ESTABLISHED 1006/ctdbd
tcp 0 0 10.10.10.90:57413 10.10.10.91:4379 ESTABLISHED 1006/ctdbd 从上面的连接信息判断,node1(10.10.10.90)通过57413端口作为client去connect了node2,通过50071端口去connect了node3。同样node2通过48353端口connect了node1。node3通过57112端口去连接了node1。与上述连接逻辑一致。
3.2事件通知机制
事件通知机制是ctdb结构中最重要的一部分,事件通知机制将各个逻辑链接起来以完成相关的功能实现。
下面以 fde = tevent_add_fd(ctdb->ev, ctdb, ctdb->daemon.sd, TEVENT_FD_READ,ctdb_accept_client, ctdb);为例来分析是如何将该事件监控起来并调用事件处理函数的。
在ctdb_start_daemon函数中,先后调用了tevent_add_fd以及tevent_loop_wait函数。
- tevent_add_fd,对于这个函数是tevent对外提供的接口,其实际调用的是epoll_event_add_fd函数(此处以epoll为例,如果内核不支持epoll,那么可能就会调用select或者poll相对应的函数。)在此函数中主要进行了2个逻辑处理
1. 将事件相关的参数和函数赋值到fde,并将fde加入到ctdb->ev->fd_events链表中;
2. 执行epoll_update_event(epoll_ev, fde)函数更新epoll_ev,具体就是将待添加的event通过epoll_ctl加入到epoll_ev->epoll_fd;
- tevent_loop_wait实际会调用epoll_event_loop_once,再调用epoll_event_loop,最终调用epoll_wait,查看已就绪事件,并调用相应的事件处理函数进行处理。
tevent_loop_wait会一直循环检查是否有事件注册了,如果有,就会不断的循环去判断;
*/
int tevent_common_loop_wait(struct tevent_context *ev,
const char *location)
{
/*
* loop as long as we have events pending
*/
while (tevent_common_have_events(ev)) { // 此函数会一直返回真
int ret;
ret = _tevent_loop_once(ev, location);
if (ret != 0) {
tevent_debug(ev, TEVENT_DEBUG_FATAL,
"_tevent_loop_once() failed: %d - %s\n",
ret, strerror(errno));
return ret;
}
}
tevent_debug(ev, TEVENT_DEBUG_WARNING,
"tevent_common_loop_wait() out of events\n");
return 0;
}3.3 主循环流程
下面图中所展示的是recoveryd进程的循环处理事务的过程。函数名称为main_loop。
A(检查ctdbd是否存活)-->B(告诉ctdbd recoveryd是活动的)
B-->C(是否选举中)
C-->D(是- 退出main_loop)
C-->E(不是- 获取ctdbd debug level)
E-->F(获取cdbd运行参数)
F-->G(获取ctdbd运行状态)
G-->H(获取nodemap)
H-->I(获取recovery mode)
I-->J(当前节点是否是stopped或者baned状态)
J-->K(是- 设置recovery mode为 active,并freezee db就是锁住?)
K-->L(获取所有节点所具备的角色能力,如下图所示)
L-->M(查看recmaster,如果unknown, force elelction)
M-->N(选举中,返回)
M-->O(查看是否有ip需要分配)
O-->P(查看是否所有节点都同意recmater node)
P-->Q(获取vnnmap)
Q-->R(查看是否需要recovery)
R-->S(查看所有节点处于normal状态)
S-->T(当前节点是否持有共享锁,是的话,检查一下锁状态)
T-->U(从所有其他节点获取nodemap并比较所有nodemap是否一致,不一致的话执行do_recover)
U-->V(更新所有节点状态标识)
V-->W(统计活动的node数量)
W-->X(active node情况与vnnmap记录一致)
X-->Y(检查所有节点是否有相同的vnn和相同的版本号)3.4节点及节点节点间通信总结
3.4.1单个ctdb节点内进程之间的连接
ctdb有两个进程,ctdbd和recoveryd,这个两个进程之间通过unix socket进行消息的传递。一般recoveryd发送带opcode的消息,ctdbd通过
3.4.2 ctdb节点之间连接
- 初始化函数ctdb_tcp_initialise中,为当前节点创建了一个监听ctdb address的socket,并且将fd保存在ctdb->private_data->listen_fd。其中private_data的数据结构是struct ctdb_tcp。也就是每一个ctdb节点启动时都会创建并监听本地节点的IP地址。
- 由于ctdb节点之间需要相互通信,因此在初始化过程中,将所有节点有关连接的信息都保存在ctdb中。ctdb->nodes[i]就可以遍历所有节点关于连接的信息。而ctdb->nodes[i]->private_data->fd就是保存相应node的fd。其中private_data的数据结构为struct ctdb_tcp_node。
- 基于上面步骤2中的描述,ctdb->nodes[i]->private_data->out_queue,就是初始化的一个队列。但是初始化时ctdb->nodes[i]->private_data->fd值为-1。
- 应该在main_loop 中getnodemap时会更新ctdb->nodes[i]->private_data->fd这个值(目前是猜测)
3.4.3 控制消息处理流程总结
下面以获取node map的消息为例来说明,如何从一个ctdb节点获取到另一个ctdb节点的信息。
1. ret = ctdb_ctrl_getnodemap(ctdb, CONTROL_TIMEOUT(), pnn, rec, &rec->nodemap);执行程序的自然就是发起消息的节点,其中pnn就是目标节点;该控制消息是获取nodemap;
2. ret = ctdb_control(ctdb, destnode, 0, CTDB_CONTROL_GET_NODEMAP, 0, tdb_null,mem_ctx, &outdata, &res, &timeout, NULL);其中destnode就是要目标node;
3. state = ctdb_control_send(ctdb, destnode, srvid, opcode, flags, data, mem_ctx,timeout, errormsg);
4. ret = ctdb_client_queue_pkt(ctdb, &(c->hdr));其中c->hdr中包含了函数调用中需要的参数;
5. ctdb_queue_send(struct ctdb_queue *queue, uint8_t *data, uint32_t length);
6. n = write(queue->fd, data, length2);即将数据包写入了unix socket 的fd中;
7. unix socket fd的read 函数是在ctdb_accept_client 中设置的:ctdb_daemon_read_cb
8. daemon_incoming_packet(client, hdr);其中,hdr即最初发送的数据包;
9. 依据hdr中的hdr->operation判断消息类别:CALL/MESSAGE/CONTROL
10. 调用CONTROL消息处理函数daemon_request_control_from_client
11. res = ctdb_daemon_send_control(client->ctdb, c->hdr.destnode,c->srvid, c->opcode, client->client_id,c->flags,data, daemon_control_callback,state);
12. ctdb_queue_packet(ctdb, &c->hdr);并添加了一个控制消息超时处理事件ctdb_control_timeout();
13. 语句node = ctdb->nodes[hdr->destnode]获取到目标node信息;
14. ctdb->methods->queue_pkt(node, (uint8_t *)hdr, hdr->length);该函数为初始化时注册的;
15. ctdb_tcp_queue_pkt(struct ctdb_node *node, uint8_t *data, uint32_t length);从node的node->private_data中提取出tnode;
16. ctdb_queue_send(tnode->out_queue, data, length);其中tnode->out_queue->fd即是已连接到目标节点的fd。
17. n = write(queue->fd, data, length2);数据通过fd写入到socket链接
18. 远端node接收到请求;在远端节点中从上述的第7步开始重复。
控制消息首先通过unix socket从recoveryd进程发送,ctdbd进程读取unix socket上的数据,并对数据进行解析,如果获取的是当前的节点信息就提供信息并返回,如果是需要获取remote node的节点信息,就使用保存在node = ctdb->nodes[hdr->destnode]中的fd将消息发送给remote node。
static const struct ctdb_methods ctdb_tcp_methods = {
.initialise = ctdb_tcp_initialise,
.start = ctdb_tcp_start,
.queue_pkt = ctdb_tcp_queue_pkt,
.add_node = ctdb_tcp_add_node,
.connect_node = ctdb_tcp_connect_node,
.allocate_pkt = ctdb_tcp_allocate_pkt,
.shutdown = ctdb_tcp_shutdown,
.restart = ctdb_tcp_restart,
};