scrapy爬虫-拉勾网(学习交流)
scrapy爬拉钩网 (学习交流)
2020-5-29
本教程将针对于拉勾网数据爬取进行分析,本教程讲使用到requests库。我知道很多人懒不想看文字,我直接讲思路上图。(程序员的浪漫–直入正题)
(新手上路,讲的不对的地方请大佬指正)
拉勾网的职位信息可以不使用很大力气爬取,但是职位详情页就会出问题。如图:
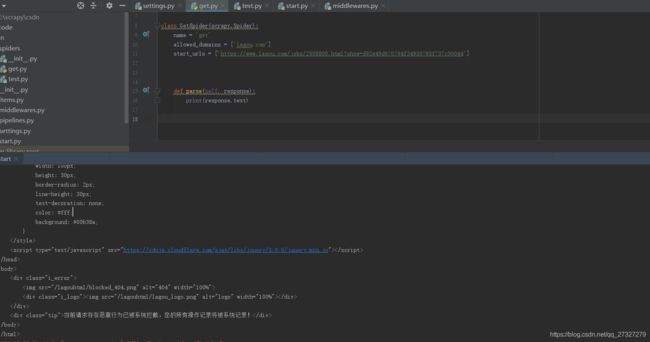
可见拉钩对职位详情页进行了反爬机制。通过常规方式无法爬取,添加随机请求头再试一下。在middleware.py中添加:
class UserAgentDownloadMiddleware(object):
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (X11; Linux i686; rv:64.0) Gecko/20100101 Firefox/64.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0',
'Mozilla/5.0 (X11; Linux i586; rv:63.0) Gecko/20100101 Firefox/63.0',
'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.10; rv:62.0) Gecko/20100101 Firefox/62.0',
'Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0',
]
def process_request(self, request, spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
再配置到setting.py中
SPIDER_MIDDLEWARES = {
'csdn.middlewares.CsdnSpiderMiddleware': 543,
'csdn.middlewares.UserAgentDownloadMiddleware': 2,
}
结果是:(并没有什么卵用)

分析一下网页:(随便打开一个职位详情页)发现在每一职位详情页的请求头中都会带有cookies,推断一下这个网站是用cookies验证的。

这个时候虽然发现了反爬机制,又伪造不了cookies,机智的我拿搜索页的cookies去测试一下。
用request库试一下:
思路:
1、获取搜索页的cookies
2、将获取的cookies带入到职位详情页的请求中去。
测试一下:
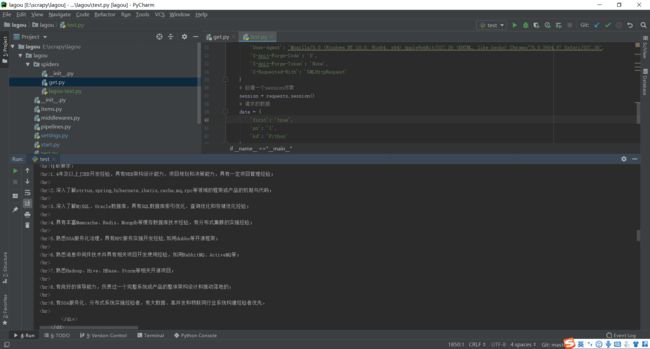
emmm我真是个小天才。果然,验证了我的猜想。接下来就简单了。
# 测试代码
# -*- encoding: utf-8 -*-
'''
@File : test.py
@Time : 2020/5/29 21:56
@Author : c-cc
@Software : PyCharm
'''
import requests
if __name__ =="__main__":
# 搜索页url
search_page = 'https://www.lagou.com/zhaopin/Java/?labelWords=label'
job_page = 'https://www.lagou.com/jobs/6843953.html?show=175b5cccafa247288f3bdfde988594e2'
#伪造的请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '25',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': search_page,
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
# 创建一个session对象
session = requests.session()
# 请求的数据
data = {
'first': 'true',
'pn': '1',
'kd': 'Python'
}
session.get(search_page)
result = session.post(job_page, headers=headers, data=data, allow_redirects=False)
print(result.text)
接下来就把requests集成到scrapy中就可以了.直接上代码
# -*- coding: utf-8 -*-
import scrapy
import requests
import re
from lxml import etree
# from scrapy.item import DictItem
# from scrapy.loader import ItemLoader
from lagou.items import LagouItem
class GetSpider(scrapy.Spider):
name = 'get'
allowed_domains = ['lagou.com']
start_urls = ['https://lagou.com/']
item = LagouItem()
def parse(self, response):
first_categorys = response.xpath('//div[@id="sidebar"]//div[@class="menu_box"]')
for first_category in first_categorys:
# 一级分类标题
first_category_title = first_category.xpath('.//h2/text()').getall()
# list
second_categorys = first_category.xpath('.//div[@class="menu_sub dn"]')
for second_category in second_categorys:
# 二级职务分类
job_category = second_category.xpath('.//span/text()').getall()
job = second_category.xpath('.//a/h3/text()').getall()
self.item['job_all_category'] = ",".join(job)
self.item['job_first_category'] = job_category
# self.item['job_title'] = job
# 工作详情页
job_urls = second_category.xpath('.//a/@href').getall()
# print(first_category_title,job_category.getall(),job.getall())
for job_url in job_urls:
self.joburl = job_url
yield scrapy.Request(url=job_url, callback=self.job_parse)
# 通过请求此url获取cookies进行内容爬取
def job_parse(self, response):
# 工作详情页
job_pages_url = response.xpath('//div[@id="s_position_list"]//div[@class="position"]//a/@href').get()
# print(response.url)
# # 当前url即为工作详情页。
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '25',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': response.url,
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
# 创建一个session对象
session = requests.session()
# 请求的数据
data = {
'first': 'true',
'pn': '1',
'kd': 'Python'
}
session.get(response.url)
result = session.post(job_pages_url, headers=headers, data=data, allow_redirects=False)
# 将返回对象转化为HTML,以便于使用xpath语法
html = etree.HTML(result.content)
describe = html.xpath('//dl[@id="job_detail"]//div[@class="job-detail"]/p/text()')
salary = html.xpath('//dd[@class="job_request"]//span[1]/text()')
job_expresion = html.xpath('//dd[@class="job_request"]//span[3]/text()')
city = html.xpath('//dd[@class="job_request"]//span[2]/text()')
job_company = html.xpath('//*[@id="job_company"]/dt/a/img/@alt')
job_title = html.xpath('//h1[2]/text()')
self.item['job_describe'] = describe
self.item['job_title'] = job_title
self.item["job_expresion"] = job_expresion
self.item["job_url"] = response.url
self.item["job_salary"] = salary
self.item["job_city"] = city
self.item["job_company"] = job_company
print(self.item)
我只获取了职位的分类,标题,工作简介,薪资工作地点等参数.虽然可以通过这种方法爬取到数据,但是很容被封ip.血泪史.后来在芝麻代理每天白嫖半个小时ip总算是搞完(猛男落泪).
添加常用反爬机制中间件:随即请求头,ip代理池
# ip代理,ip已失效,需要的自己购买或者是去芝麻白嫖,每天半个小时 =-=
class IpProxyMidleware(object):
Proxy = [
'58.218.92.90:2816',
'58.218.92.94: 7269',
'58.218.92.89: 4889',
'58.218.92.94: 8008',
'58.218.92.91: 9840',
'58.218.92.86: 5329',
'58.218.92.94: 3912',
'58.218.92.89: 4628',
'58.218.92.89: 3800',
'58.218.92.90: 4672',
'58.218.92.89: 5858',
'58.218.92.94: 8525',
'58.218.92.90: 9764',
'58.218.92.94: 9876',
'58.218.92.90: 9799',
'58.218.92.91: 3280',
'58.218.92.89: 5410',
'58.218.92.89: 4320',
'58.218.92.89: 8018',
'58.218.92.91: 4889',
]
def process_request(self, request, spider):
request.meta['proxy'] = 'https://' + random.choice(self.Proxy)
class UserAgentDownloadMiddleware(object):
USER_AGENTS = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML like Gecko) Chrome/44.0.2403.155 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36',
'Mozilla/5.0 (X11; Linux i686; rv:64.0) Gecko/20100101 Firefox/64.0',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0',
'Mozilla/5.0 (X11; Linux i586; rv:63.0) Gecko/20100101 Firefox/63.0',
'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.10; rv:62.0) Gecko/20100101 Firefox/62.0',
'Mozilla/5.0 (X11; Linux x86_64; rv:68.0) Gecko/20100101 Firefox/68.0',
]
def process_request(self, request, spider):
user_agent = random.choice(self.USER_AGENTS)
request.headers['User-Agent'] = user_agent
至此基本上就解决了拉钩爬不到数据的问题。
我已经将源码放到了我的码云上:码云地址https://gitee.com/hou_cc/woyulagoudedouzhidouyong
转载请注明来源。